
👉 강화학습, Reinforcement Learning이 궁금하다면?

강화학습, Reinforcement learning 이란 무엇인가?
Reinforcement learning 정의
인간은 주변의 환경과 상호작용을 통해 학습하고 익힐 수 있습니다. 명시적인 가르침 없이도 주변의 환경을 인식하고 몸을 제어할 수 있다는 것에서 알 수 있죠. 모든 Learning, Intelligence 등 이론의 근본적인 아이디어는 상호작용을 통한 학습에서 유래되었습니다. 강화학습은 이 중에서도 목표 지향(Goal-directed learning)에 초점을 둔 학습 방법을 의미합니다.
강화학습, Reinforcement learning 은 머신러닝의 한 종류로, 행동을 수행하는 학습자가 어떤 행동을 해야 하는지 알지 못하는 상태에서 행동에 대한 보상을 극대화하기 위해 어떻게 행동해야 할 지 방향을 찾는 학습 방법입니다.
특징
가장 대표적인 머신러닝 방법론 중 Supervised/Unsupervised Learning과는 다르게, Reinforcement learning은 독특한 특징을 가지고 있습니다.
- Trial and Error (시행착오)
- Reinforcement Signal (보상 신호)
- Delayed Reward (보상 지연)
- Exploration and Exploitation (탐험과 이용)
강화학습은 수많은 시행착오를 통해 최적의 행동을 찾아냅니다. 에이전트는 환경과 상호작용하면서 보상과 패널티를 경험하고, 이러한 결과를 바탕으로 행동을 개선할 수 있습니다. 이런 반복적인 과정을 통해 에이전트는 보상을 최대화하는 최적의 전략을 학습합니다. 또한 행동의 결과가 시간적으로 지연된 보상으로 표현됩니다. 이는 에이전트가 현재의 행동이 미래에 어떤 결과를 가져올지 예측하고 고려하도록 유도합니다. 즉, 에이전트는 장기적인 목표를 위해 단기적인 보상을 고려해야 합니다. 이미 알고 있는 최적의 행동을 지속적으로 선택함으로써 보상을 최대화할 수 있게 해주는 것이죠.
Supervised vs. Unsupervised vs. Reinforcement learning

머신러닝의 종류에는 지도학습과 비지도학습, 그리고 강화학습이 있습니다. 세 가지 모두 범용적으로 사용되는 방법론이지만, 명확한 차이점을 가지고 있습니다. 각각의 장단점을 비교해보면 다음과 같습니다.
- Supervised learning, 지도 학습은 가장 정확한 학습 유형이지만 레이블이 지정된 데이터가 필요
- Unsupervised learning, 비지도 학습은 지도 학습으로 찾기 어렵거나 불가능한 데이터 패턴을 찾는 데 유용하지만 정확도가 떨어질 수 있음
- Reinforcement learning, 강화학습은 구현하기 가장 어려운 학습 유형이지만 다른 유형의 학습으로는 해결하기 어렵거나 복잡한 문제 해결에 용이
이를 기반으로 해석하자면, 지도 학습은 이미지 분류, 자연어 처리, 사기 탐지 등의 작업에 주로 사용됩니다. 비지도 학습은 클러스터링, 이상 징후 감지, 차원 축소와 같은 작업에 주로 사용됩니다. 반면 강화학습은 게임 플레이, 로봇 공학, 금융 거래와 같은 작업에 자주 사용됩니다.
왜 강화학습이 중요한가

많은 AI 리딩 기업들이 강화학습에 주목하고 있습니다. 머신러닝에 대한 인기가 높아지는 가운데, 그 중에서도 왜 강화학습이 주목 받고 있을까요?
비지도 학습과 지도 학습의 한계 극복
Unsupervised learning, 비지도 학습은 레이블이 없는 데이터에서 특징을 추출하는 방법이지만, 목표에 대한 엄격한 지침이 없어 제한적인 결과를 가져올 수 있습니다. 지도 학습은 레이블이 있는 데이터에서 예측 모델을 만들지만, 사전적인 지식을 요구하고 학습 데이터가 많아야 하는 한계가 있습니다. 반면에 Reinforcement learning, 강화학습은 시행착오를 통해 에이전트가 최적의 행동을 스스로 학습하므로, 더 확장된 학습 방법을 제공할 수 있습니다.
복잡한 문제를 해결하고, 실시간 학습에 적응
강화학습은 복잡하고 도전적인 문제를 해결하는 데에 유용합니다. 예를 들어, 자율 주행 차량이나 로봇과 같은 실제 시스템에서 강화학습을 적용하여 에이전트가 환경과 상호작용하면서 최적의 행동을 학습할 수 있습니다. 이를 통해 시스템은 변화하는 환경에 적응하고 최상의 성능을 발휘할 수 있게 됩니다.
또한 강화학습은 실시간으로 학습하고 적응하는 능력을 가지고 있습니다. 에이전트는 환경과의 상호작용을 통해 행동의 결과를 경험하고 보상을 얻습니다. 이러한 실시간 학습과 적응 능력은 변화하는 환경에 유연하게 대처할 수 있도록 도와줍니다.
다양한 응용 분야
강화학습은 다양한 응용 분야에서 활용할 수 있습니다. 예를 들어, 게임 이론, 신경과학, 경제학, 로봇 공학 등 다양한 분야에서 강화학습을 적용하여 문제를 해결하고 최적의 전략을 구축할 수 있습니다. 이러한 다양성은 강화학습의 유용성과 활용 가능성을 더욱 높여줍니다.
이러한 이유들로 인해 강화학습은 머신러닝에서 주목 받고 있으며, 계속해서 발전되고 활용되고 있습니다. 강화학습은 복잡한 문제를 해결하고 실시간으로 학습하며 적응할 수 있는 강력한 학습 방법으로 폭넓은 응용 가능성을 가지고 있습니다.
강화학습 작동 방식
구성 요소, elements
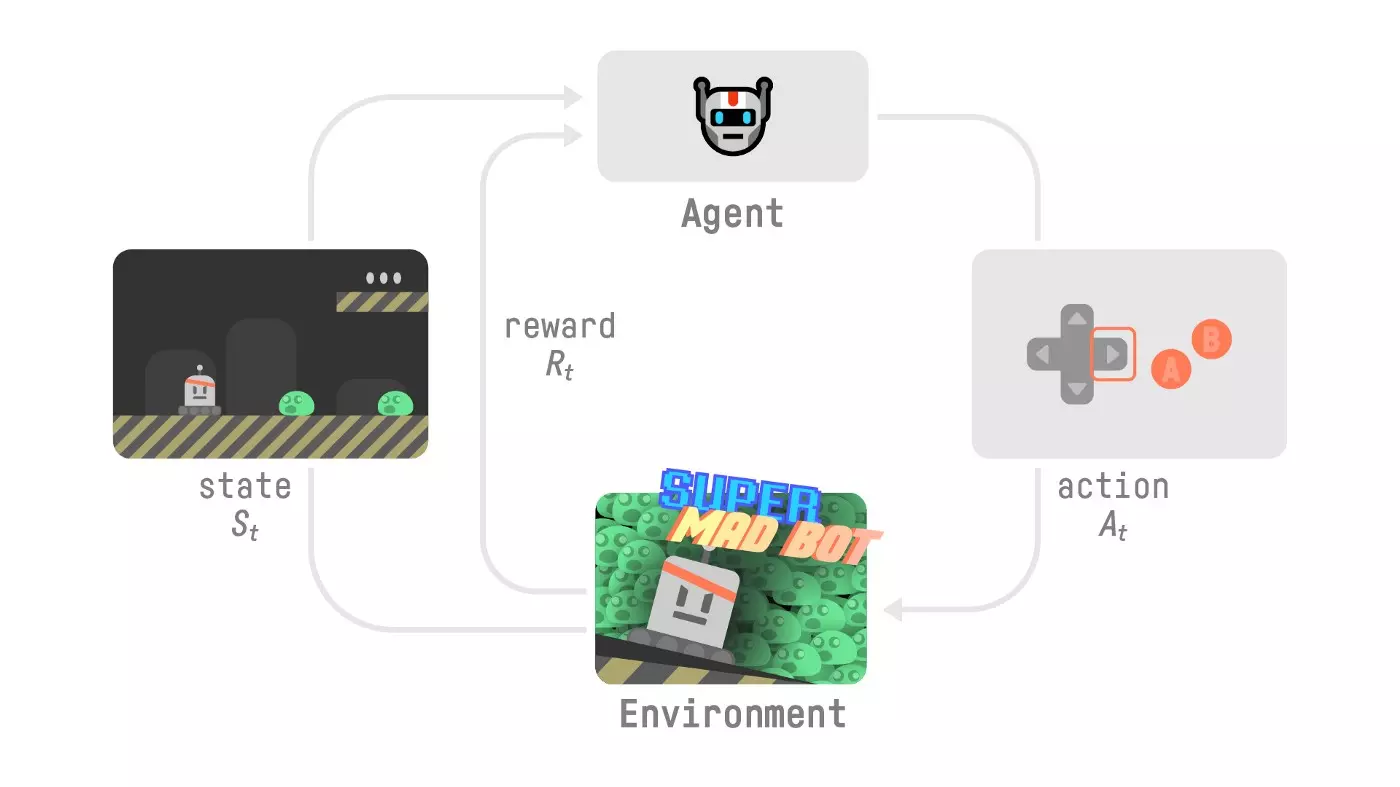
강화학습의 원리를 이해하기 위해서는 네 가지 구성요소를 먼저 이해할 필요가 있습니다.
Agent (에이전트)
강화학습에서 의사 결정을 수행하는 주체입니다. 에이전트는 환경과 상호작용하며 행동을 결정하고 그에 따른 보상을 받습니다. 에이전트는 현재의 상태를 파악하고 최적의 행동을 선택하기 위한 정책(Policy)을 가지고 있습니다.
정책은 에이전트가 수행하는 모든 항목의 핵심으로, 함수를 통해 다음 행동을 결정하게 됩니다.
Environment (환경)
환경은 에이전트가 학습하는 무대입니다. 환경은 에이전트의 행동하는 상태(State)와 보상(Reward)을 결정합니다. 이를 통해 에이전트는 행동 다음에 받을 보상을 예측하며 학습을 이어나가게 됩니다.
State (상태)
에이전트가 환경과 상호작용할 때 어떤 상황에 있는지를 나타냅니다. 상태는 환경에 따라 다양한 정보를 포함할 수 있으며, 에이전트의 의사 결정은 현재의 상태를 기반으로 이루어집니다.
State의 value는 state 집합의 장기적인 매력을 의미하는데, 예상되는 미래 상태와 해당 상태에서 발생하는 혜택을 기반으로 결정됩니다. 예를 들면 현재는 즉각적인 보상은 적지만 더 큰 보상을 제공하는 추가 상태가 계속된다면 여전히 가치 있다고 보는 것입니다.
Action (행동)
강화학습에서는 에이전트가 가능한 행동을 선택합니다. 행동은 에이전트가 의사 결정을 통해 환경에 대해 가하기로 선택한 변화입니다. 각 상태에서 에이전트는 가능한 행동 중에서 어떤 것을 선택해야 하는지 결정합니다.
Reward (보상)
보상은 에이전트가 특정 행동을 취했을 때 받는 신호입니다. 보상은 에이전트가 원하는 목표를 달성하기 위한 동기 부여에 중요한 역할을 합니다. 좋은 행동에 대해서 양의 보상이 주어지고, 나쁜 행동에 대해서는 음의 보상이 주어질 수 있습니다.
에이전트의 궁극적인 목적은 획득한 전체 보상을 최적화하는 것입니다. 따라서, 보상은 에이전트의 긍정적인 행동 결과와 나쁜 행동 결과를 구별할 수 있게 됩니다.
Reinforcement learning 알고리즘 분류
에이전트(Agent)의 구성 요소?
강화학습의 분류 체계를 알아보기 전에 먼저 분류의 기준이 되는 강화학습 agent(행위자)의 구성 요소에 대해 알아보아야 합니다. 강화학습의 agent는 크게 다음 세가지의 요소를 갖습니다.
- Policy
gent의 행동 패턴입니다. 주어진 환경(state)에서 어떤 행동(action)을 취할지 말해줍니다. 즉, 환경(state)을 행동(action)에 연결 짓는 함수입니다.
Policy는 크게 deterministic(결정적) policy와 stochastic(확률적) policy로 나뉩니다.
Deterministic policy는 주어진 환경(state)에 대해 하나의 행동(action)을 주고, stochastic policy는 주어진 환경(state)에 대해 행동(action)들의 확률 분포를 줍니다. - Value function
환경(State)과 행동(action)이 나중에 어느 정도의 보상(reward)을 돌려줄지에 대한 예측 함수입니다.
즉, 해당 환경(state)과 행동(action)을 취했을 때 이후에 받을 모든 보상(reward)들의 가중합입니다.
이때, 뒤에 받을 보상(reward) 보다 먼저 받을 보상(reward)에 대한 선호를 나타내기 위해 discounting factor λ를 사용합니다. - Model
다음 환경(state)과 보상(reward)이 어떨지에 대한 agent의 예상입니다. State model과 Reward model로 나눌 수 있습니다.
Model-Free vs. Model-based

강화학습 알고리즘을 구분하는 첫 번째 기준은 환경(Environment)에 대한 model 존재 여부입니다. 모델을 갖는 것은 각각의 장단점을 가지고 있습니다.
- 장점 : 계획이 가능함
자신의 Action에 따라 환경이 어떻게 바뀔지 안다면, 실제로 행동하기 전에 미리 변화를 예상해보고 최적의 행동을 실행할 수 있습니다. 이와 같은 계획으로 에이전트는 훨씬 효율적으로 행동할 수 있게 됩니다. - 단점 : 구현이 어렵거나 불가능함
모델이 환경을 제대로 반영하지 않는 오류가 빈번하게 발생하며, 이 오류는 그대로 에이전트의 오류로 이어지게 됩니다. 정확한 모델을 만드는 것은 좋은 에이전트를 만드는 것만큼, 혹은 그 이상 어려운 작업일 수 있죠.
각각의 장단점이 있기 때문에, 모델을 사용하는 에이전트는 Model-based, 그렇지 않은 에이전트는 Model-free라고 부릅니다.
Value-Based vs. Policy-Based
강화학습 알고리즘의 두 번째 구분은 value function과 policy의 사용 여부에 달려있습니다.
만약 Value function이 완벽하다면, 최적의 Policy (정책) 은 자연스럽게 따라옵니다. 각 상태에서 가장 높은 가치를 주는 행동만을 선택하면 되기 때문이죠. 이를 implicit policy (암묵적인 정책)이라고 합니다. DQN처럼 value function만을 학습하고, policy는 암묵적으로 갖는 알고리즘들을 value-based agent라고 부릅니다.
반대의 경우에는 완벽한 정책을 가지고 있고, Value function은 굳이 갖지 않습니다. 결국 value function은 정책을 만들기 위해 사용되는 중간 계산일 뿐이기 때문이죠. 이처럼 value function 없이 정책만을 학습하는 에이전트를 policy-based라고 부릅니다. Policy Gradient 등이 여기에 해당합니다.
후자의 경우 데이터를 더 효율적으로 활용할 수 있다는 장점이 있습니다. 이에 비해 Policy-based agent는 원하는 것에 직접적으로 최적화를 하기 때문에 더 안정적으로 학습할 수 있죠. 두 가지의 선택지를 모두 갖고 있는 케이스의 경우, Actor-critic agent라고 부릅니다.
강화학습 활용 사례
강화학습은 머신러닝의 기존 방법론보다 더 복잡한 문제를 해결하는 데에 특화되어 있습니다. 강화학습이 어떤 용도로 활용되고 있는지 사례 분석을 통해 용도를 확인해보겠습니다.
로보틱스
로봇은 역동적이고 끊임없이 변화하는 환경에서 작동하기 때문에, 다음에 무슨 일이 일어날 지 예측하는 것이 불가능했습니다. 강화학습은 산업 현장과 같은 시나리오에서 로봇을 견고하게 만들고, 복잡한 행동을 적응적으로 습득하는 데 도움이 되었습니다. 특히 반복적인 검사 과정을 제거하고 생산 조립 라인의 품질 관리를 보장하는 등 기존의 컴퓨터 비전 (Computer vision) 을 대체하는 데에 목표를 두고 있습니다.
제품 조립 및 결함 검사

여러 제조업체는 강화학습을 통해 제품 조립 프로세스를 개선하고, 이를 완전히 자동화하여 전체 흐름에서 관리자의 수동적인 개입을 제거하는 데에 성공했습니다. 객체 감지 및 객체 추적 모델에 강화학습을 더한 것입니다. 또한 심층 강화학습 모델은 누락된 조각이나 찌그러짐, 균열, 긁힘 및 전체 손상을 수백만 개의 데이터 포인트에 걸친 이미지로 쉽게 식별하기 위해 멀티모달 데이터를 사용하여 훈련하고 있습니다.
재고 관리

실시간으로 재고를 추적하기 위한 컴퓨터 비전 분야의 발명으로, 넓은 면적을 자랑하는 창고에서 재고 관리를 자동화할 수 있었습니다. 심층 강화학습 에이전트는 빈 용기를 찾아 재입고가 완전히 최적화될 수 있도록 돕습니다.
게임
강화학습의 에이전트는 보상을 받는 행동과 불이익을 받는 행동을 구분하여 보상을 극대화하는 행동 방식을 자연스럽게 습득합니다. 또한, 기초 모델은 복잡한 데이터를 표현하고 생성하는 일종의 머신 러닝 모델로, 자연어 처리 및 컴퓨터 비전 등 다양한 분야에서 활용됩니다.

DeepMind ADA는 이러한 기초 모델을 이용하여 강화학습의 성능을 향상시키는 새로운 알고리즘입니다. 이러한 알고리즘은 먼저 대규모 데이터 세트에서 기초 모델을 훈련하고, 이 모델을 이용하여 에이전트가 수행할 수 있는 작업을 생성합니다. 작업 결과는 다시 기초 모델을 업데이트하는데 활용됩니다.
구글 딥마인드 팀은 에이전트가 바둑을 두도록 훈련하는 방법에 대해 설명한 적이 있습니다. 이 에이전트는 바둑 게임 방법을 명시적으로 배운 적이 없음에도 불구하고 초인적인 수준으로 바둑을 둘 수 있었죠. 강화학습이 다양한 작업에서 사용될 수 있을 것이라는 잠재력을 보여준 사례로 전 세계에 유명해졌습니다.
최근 딥마인드는 바둑, 체스와 같은 게임에 적용할 목적으로 훈련한 강화학습 모델인 알파제로(AlphaZero)를 기반으로 알파데브를 개발했습니다. 주요 변경점은 AI가 더 빠른 알고리즘 찾기를 일종의 게임으로 간주하여 승리하도록 훈련시킨 것인데요. 컴퓨터 명령어 등을 선택해 순서대로 배치한 다음, 그 결과를 알고리즘으로 작동시키는 게임을 사용해 계산 시간을 단축하는 데에 성공했습니다.
자율주행
개방형 컨텍스트 환경에서 차량 주행은 실제 세계에서 일어날 수 있는 모든 장면과 시나리오로 훈련된 머신러닝 모델이 필요합니다. 하지만 주행 시나리오에 따른 모든 데이터를 구하기란 불가능에 가깝기 때문에 강화학습을 이용하여 모델을 훈련시킬 수 있습니다. 강화학습 모델은 트래픽 중단을 최소화하는 탐색 및 이용 원칙에 따라, 자체 경험에서 정책을 학습하여 동적 환경에서 훈련됩니다. 자율주행 자동차는 이를 기반으로 운전 구역을 식별하고, 교통 처리 및 제한 속도 유지, 충돌 방지 등의 결정을 내릴 수 있습니다.
자율주행에서 강화학습을 사용하는 원리는 다음과 같습니다.
- 먼저 컨볼루션 신경망 계열의 학습 알고리즘을 사용하여, 카메라 등을 통해 수집된 방대한 이미지 데이터를 컴퓨터가 인식할 수 있는 모델로 변환시킵니다.
- 이후 빠른 학습을 위해 GPU나 전용 칩 등을 활용하여 병렬 처리한 뒤, 만들어진 모델을 시뮬레이터에서 돌려 강화학습을 진행합니다.
- 그리고 실제 환경에서 시험 운전을 거치면 완전한 자율주행을 달성할 수 있을 것이라고 보고 있습니다.
웨이모 (Waymo)
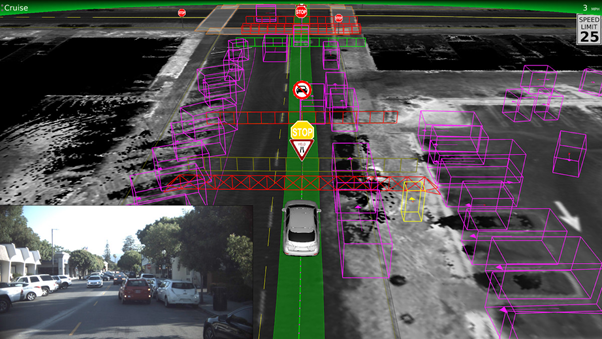
웨이모의 강화학습은 실제 도로 상황을 시뮬레이션하여 다양한 주행 상황에 대한 경험을 축적하고 이를 이용해 파악된 상황에 가장 적합한 주행 전략을 개발하는 방식입니다. 웨이모의 자율주행차량은 수많은 시뮬레이션을 기반으로 학습하고, 실제 도로 상황에서도 안정적이고 예측 가능한 주행을 수행할 수 있습니다. 강화학습을 통해 훈련된 웨이모의 자율주행차량은 인간 운전자와 비교해 높은 수준의 안전성과 효율성을 보여주고 있습니다.
테슬라 (Tesla)

반면 테슬라는 자율주행을 위해 강화학습을 사용하고 있는지 확실하지 않지만, 지금까지는 Imitation Learning (모방 학습)을 활용하고 있다고 밝힌 바가 있습니다. 모방 학습이란, 전문가의 데이터를 모아 인공지능이 전문가가 하는 방식대로 하면 보상을 많이 주는 방법론입니다. 위에서 설명한 강화학습과는 달리, 결과값이 담긴 데이터를 주입해서 컴퓨터가 알고리즘을 찾도록 하는 supervised learning (지도 학습) 방법 계열이죠.
전문가들은 테슬라는 80억 마일이 넘는 실제 주행 데이터를 보유하고 있기 때문에 실제 운전자의 주행 데이터를 기반으로 한 모방 학습이 강화학습보다 유리할 것이라고 설명했습니다. 그러나 최근 테슬라가 강화학습 전문 인력을 채용하고 있는 것으로 미루어보아, 향후 자율주행을 위해 두 방식의 결합을 추진할 수도 있을 것입니다. 만약 테슬라의 자율주행 시스템에 강화학습 방법을 적용한다면 실시간 데이터를 수집하고 분석하여 다양한 주행 상황에서의 최상의 행동을 학습할 것입니다. 이를 통해 테슬라 차량은 자동차 조작에 있어 좀 더 정교한 판단과 반응을 보여주며, 운전 환경이나 교통 상황 변화에 더 잘 대응할 수 있게 됩니다.
NLP
강화학습은 텍스트 요약, 질문 답변, 번역, 대화 생성 등 다양한 NLP 영역에서 사용되고 있습니다. 여기서 에이전트는 문장의 상태를 이해하고 추가할 가치를 극대화하는 작업 세트를 구성할 수 있습니다.
Reinforcement learning to NLP

강화학습을 NLP 작업에 적용할 수 있는 방법을 정리하면 다음과 같습니다.
Text generation (텍스트 생성)
- 앞의 용어가 주어진대로 다음 단어를 예측하여 텍스트를 생성하는 방법을 학습
- 생성된 텍스트가 인간이 작성한 참조 텍스트와 얼마나 밀접하게 일치하는지에 기초
Dialogue systems (대화 시스템)
- 가장 적절한 반응을 예측해 챗봇 또는 가상 비서 시스템에서 사용자 입력에 반응하는 방법을 학습
- 에이전트의 답변은 응답의 품질과 사용자의 만족도를 고려할 수 있는 보상 기능을 기반으로 평가
Sentiment analysis (감정 분석)
- 주어진 텍스트의 감정을 예측하여 텍스트를 긍정, 부정 또는 중립으로 분류하는 방법을 학습
- 에이전트가 얼마나 잘 분류하는지에 따라 보상 함수가 에이전트의 예측을 판단하는 데 사용
Text summarization (텍스트 요약)
- 가장 중요한 문장이나 구문을 예측하여 긴 문서의 요약을 생성하는 방법을 학습
- 에이전트의 요약은 요약의 관련성과 일관성에서 찾을 수 있는 보상 함수를 기반으로 평가
👉 LLM (초거대 언어모델)에 대해 자세히 알고 싶다면?

세계 최대 벤처캐피탈(VC) 중 하나인 세쿼이아 캐피털이 공개한 보고서에 의하면 ChatGPT 열풍 이후, 기업의 LLM (거대 언어 모델) 도입률이 비약적으로 상승했다고 합니다. 세쿼이아 캐피털이 조사한 기업 중 새로운 LLM을 적용한 앱을 만든 기업의 비중이 불과 두 달 만에 15%에서 65%로 급등했다고 합니다. 대상 기업이 AI를 적용한 분야도 다양했습니다. 또한 대부분의 기업이 LLM을 자체 개발하기보다는 공개된 API를 사용하고 있다고 하죠.
생성 AI의 가능성이 주목받으면서 LLM에 대한 관심도 함께 커지고 있습니다. 이 글에서는 LLM에 대한 정의와 원리, 사용 사례와 구축 노하우에 대해 소개합니다.
LLM (Large Language Model) 이란 무엇인가?
정의
LM (언어 모델, Language Model) 이란, 인간의 언어를 이해하고 생성하도록 훈련된 일종의 인공지능 모델입니다. 주어진 언어 내에서 패턴이나 구조, 관계를 학습하여 텍스트 번역과 같은 좁은 AI 작업에서 주로 활용되었죠. 언어 모델의 품질은 크기나 훈련된 데이터의 양 및 다양성, 훈련 중에 사용된 학습 알고리즘의 복잡성에 따라 달라집니다.
그렇다면 LLM (거대 언어 모델, Large Language Model) 이란, 대용량의 언어 모델을 의미합니다. LLM은 딥 러닝 알고리즘과 통계 모델링을 통해 자연어 처리(Natural Language Processing, NLP) 작업을 수행하는 데에 사용합니다. 이 모델은 사전에 대규모의 언어 데이터를 학습하여 문장 구조나 문법, 의미 등을 이해하고 생성할 수 있습니다.
예를 들어, 주어진 문맥에서 다음 단어를 예측하는 문제에서 LLM은 문장 내의 단어들 사이의 유사성과 문맥을 파악하여 다음 단어를 생성할 수 있습니다. 이러한 작업은 기계 번역, 텍스트 요약, 자동 작문, 질문 응답 등 다양한 NLP 과제에 활용됩니다. LLM은 GPT(Generative Pre-trained Transformer)와 BERT(Bidirectional Encoder Representations from Transformers)와 같은 다양한 모델들이 있습니다. 이러한 모델들은 수천억 개의 매개변수를 가지고 있습니다. 최근에는 대용량의 훈련 데이터와 큰 모델 아키텍처를 사용하여 더욱 정교한 언어 이해와 생성을 달성하는데 주목을 받고 있습니다.
NLP vs. LLM
NLP와 LLM은 관련이 있는 개념이지만, 서로 다른 개념입니다.
NLP는 인간의 언어를 이해하고 처리하는 데 초점을 맞춘 인공지능 분야입니다. NLP는 컴퓨터가 자연어 텍스트를 이해하고 분석하는 기술을 개발하는 것을 목표로 합니다. NLP는 문장 구문 분석, 텍스트 분류, 기계 번역, 질의 응답 시스템, 감정 분석 등과 같은 다양한 작업에 활용됩니다.
반면 LLM은 큰 데이터셋을 사용하여 훈련된 대용량의 언어 모델을 가리킵니다. 딥 러닝 기술과 통계 모델링을 사용하여 자연어 처리 작업을 수행할 수 있죠.
즉, NLP는 자연어 처리 분야 전반을 아우르는 개념이며, 텍스트를 이해하고 처리하는 기술에 초점을 둡니다. LLM은 NLP의 한 부분으로, 대량의 언어 데이터를 바탕으로 학습된 언어 모델을 사용하여 특정 NLP 작업을 수행하는데 초점을 둡니다. NLP는 더 넓은 의미의 개념이며, LLM은 그 안에서 특정한 접근 방식과 모델을 가리키는 한 가지 형태입니다.
왜 LLM (Large Language Model) 이 중요할까?
거대 언어 모델의 산업 적용 가능성
대규모 언어 모델은 다양한 유형의 소통이 필요한 언어나 시나리오에 적합합니다. 이를 기반으로 산업과 전반에 AI가 활용되는 범위가 넓어졌고, 연구와 창의성과 생산성 분야에 새로운 지평을 가져다줄 것이라는 기대를 받고 있습니다. 아래에서는 LLM이 활용될 수 있는 많은 사례 중 일부를 소개합니다.
- 소매 업체와 기타 서비스 제공 업체는 LLM을 기반으로 챗봇, AI 비서 등으로 고객 서비스의 퀄리티를 높이고 있습니다.
- LLM을 적용한 검색 엔진은 보다 사람처럼 직접적인 응답을 제공할 수 있습니다.
- 생명과학 연구원은 단백질, 분자, DNA, RNA를 이해하기 위해 LLM을 훈련시킬 수 있습니다.
- LLM을 통해 개발자는 소프트웨어 코드를 작성하고, 로봇에게 물리적인 작업을 가르칠 수도 있습니다.
- 마케터는 LLM을 훈련시켜 고객의 피드백이나 요청을 클러스트화하고, 제품 설명에 따라 제품을 범주별로 세분화하기도 합니다.
- LLM을 사용해 수익 결산 (Earning call) 을 요약하고 중요한 회의를 기록할 수 있습니다. 또한 신용카드사는 이를 활용해 이상 징후를 감지하거나, 사기 가능성을 분석해서 소비자 보호에 앞장설 수 있습니다.
- 법적인 해석이나 서류 작성 등에 LLM의 도움을 받을 수 있습니다.
LLM 및 기초 모델이 비즈니스 환경에 미치는 영향
ChatGPT와 같은 LLM은 이제 튜링 테스트를 가뿐히 통과할 수 있을 정도로 자연스러워졌습니다. 이를 기반으로 위의 사례처럼 다양한 분야와 산업에서 LLM을 사용하고 있습니다. 그렇다면 실제로 LLM은 어떤 식으로 비즈니스 세계에 영향을 미치고 있을까요?
- 작업 자동화: LLM은 현재 사람이 수행하는 많은 작업을 자동화하는 데 사용할 수 있습니다. 직원들은 보다 전략적이고 창의적인 업무에 집중할 수 있습니다.
- 고객 서비스 개선: LLM을 사용하여 연중무휴 24시간 고객의 질문에 답변하고 문제를 해결할 수 있는 챗봇을 만들 수 있습니다.
- 창의적인 콘텐츠 생성: LLM은 창의적인 콘텐츠를 생성하는 데 사용할 수 있습니다.
- 더 나은 비즈니스 의사 결정: LLM은 데이터를 분석하고 미래 트렌드를 예측하는 데 사용할 수 있습니다. 이를 통해 기업은 제품, 마케팅, 투자에 대한 더 나은 의사 결정을 내릴 수 있습니다.
기초 모델(Foundation Model)이란, 매우 큰 데이터 세트에서 학습하는 다목적 ML 모델로, 교육이 완료되면 이러한 모델을 표준 소비자 등급 장비에서 사용합니다. 기초 모델은 비즈니스 운영의 상당 부분을 차지하는 것들을 수행할 수 있습니다. 예를 들면 이미지를 만들거나 코딩을 작성하는 것이죠. 이렇게 사전 학습된 모델은 특정 작업이나 용도에 맞게 사용할 수 있습니다.
이 모델은 적은 수의 변수와 제한된 기능을 갖추고 있습니다. 주로 초기 실험이나 컨셉 검증, 프로토 타입 단계에서 사용하고 있습니다. 기존의 기업들은 자체적으로 LLM을 구축 또는 ChatGPT를 활용하기 위해 많은 비용을 지불해야만 했습니다. 그러나 이제는 기초 모델을 통해 LLM의 초기 형태를 갖춘 뒤 비즈니스에 적용할 수 있게 되었습니다. 현재 오픈소스로 많은 기초 모델이 공개되었기 때문에, 기업은 목적에 맞는 모델을 구축하기 전에 비용과 절차를 간소화할 수 있었습니다.
LLM과 기초 모델은 단순히 일상적인 경험이나 환경을 디지털화하는 것이 아닙니다. 온라인에서 사용할 수 있는 거의 모든 지식을 가지고, 현실 세계의 문제를 효과적으로 해결할 수 있는 모델로 만드는 것이죠. 외부에 현실과 닮은 시뮬레이션을 만드는 것이 아니라, 인간 언어 자체의 살아있는 대화형 시뮬레이션을 생성했다고 보는 것이 더 가까울 것입니다. 도메인 지식을 훈련시킨 기초 모델을 기반으로 LLM을 구축하면, 기업 맞춤형 솔루션을 구축할 수 있게 된 것이죠.
Active Learning을 활용해 데이터가공 작업 속도 가속하기

Active Learning 이란?
전통적으로 수동적 머신러닝 (Passive Machine Learning) 은 라벨링되지 않은 데이터에 사람이 직접 라벨을 붙이고 머신러닝을 하는 방식이었습니다. 이 방식은 데이터 라벨링을 통해 학습 데이터를 준비하는 데 상당한 사람의 노동력이 필요합니다. 또한 최근 발표되는 논문과 공개되는 오픈소스 기계 번역 모델을 보면 인간보다 더 잘할 수 있는 모델들이 굉장히 다양한데, 우수한 기계 라벨링을 두고 사람이 모든 라벨링을 하는 것은 다소 낭비일 것 같습니다.
머신러닝을 통해 어떤 데이터가 필요한지 판단하고 인간에게 라벨링을 요청하면 인간은 라벨링 작업을 덜 하면서도 좋은 모델을 학습할 수 있을까요? 이것이 바로 Active Learning, 능동형 학습의 개념입니다. 인공지능 학습 과정에서 액티브 러닝, Active Learning 이란 아직 레이블링이 되어 있지 않은 데이터(unlabeled data) 중에 모델 학습에 가장 효과적일 것 같은 데이터를 고르는 작업을 말합니다.
여기서 말하는 효과적인 학습이란, 결과적으로 가지고 있는 데이터셋 전체를 잘 학습했을 때의 기대 성능이 100이라면 샘플링 작업 속도 측면에서 ‘어떻게 하면 100에 빠르게 도달할 수 있는지’ 또는 ‘혹시 그 이상의 성능을 확보할 수 있는지’가 있을 수 있습니다.
능동형 학습의 목표는 기계가 라벨링할 가장 유익한 데이터를 자동으로 점진적으로 선택하는 것입니다. 모델은 초기에 레이블이 지정된 일부 데이터를 사용하여 학습을 시작하고 학습에 중요한 레이블이 지정되지 않은 데이터에 레이블을 지정하도록 요청합니다. 그런 다음 모델은 더 많은 정보를 제공하는 데이터를 사용하여 학습 및 데이터 요청 주기를 진행하면서 점차적으로 모델을 개선합니다.
인공지능 모델 입장에서는 아직 공부한 적도 없는 문제들(데이터)인데, 누가 나한테 더 도움이 될지 어떻게 알아?라고 할 수 있지만, 사실 사람도 직감적으로 알 때가 있습니다. 어떤 문제가 더 어려운지, 어떤 챕터를 공부하면 지금 나에게 더 중요할지.
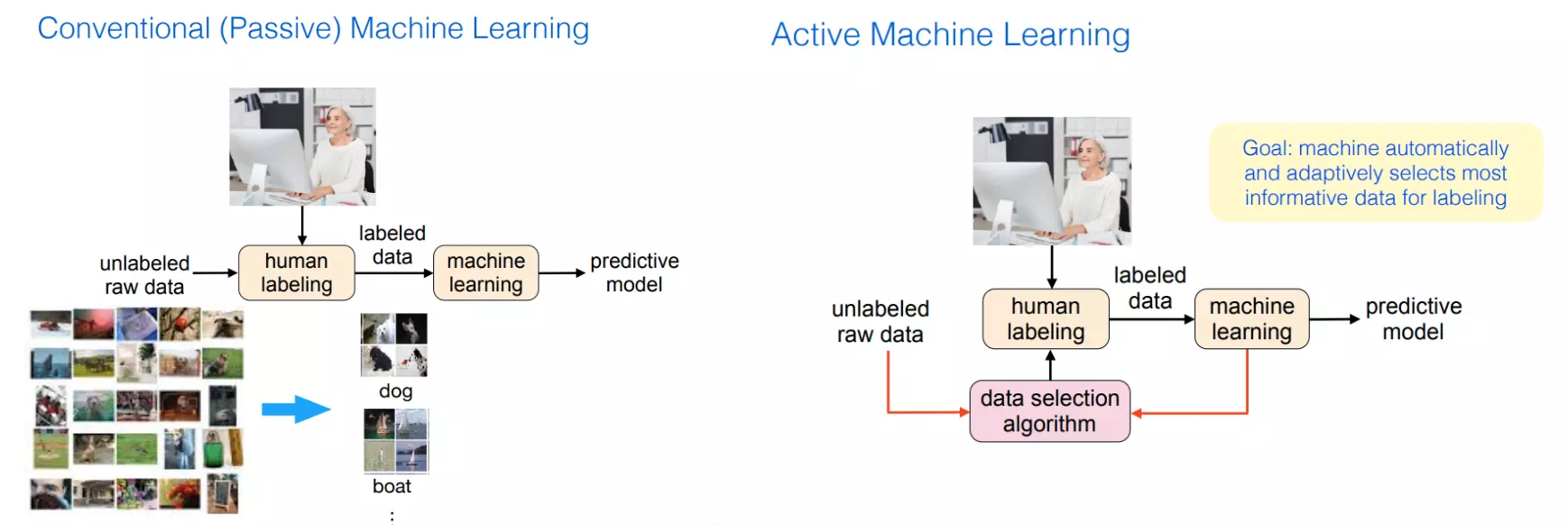
Active Learning 왜 필요한가요?
데이터헌트에서는 AI 모델을 통해 사전 레이블링(Pre-labeling) 작업을 하고 이후 사람 작업자가 작업을 수정합니다. 이를 설명하기 위해 하나의 상황을 만들어 보겠습니다.
손을 다쳐서 문제를 직접 푸는데 시간이 많이 걸리는 나(작업자)는 학교 시험을 대비하여 친구(AI)에게 컨닝 페이퍼(pre-label)를 부탁했습니다. 친구가 공부를 잘할수록 내가 직접 풀 문제도 적어지고 시험 성적도 올라갈 것 같습니다. 그래서 공부를 잘하는 나는 친구에게 수업을 해주기로 했습니다.
컨닝 페이퍼 버전 1
- [나] 일단 아무 문제(데이터)나 소량을 골라 직접 푼다.
- [친구] 내가 푼 문제로 공부(모델 학습)를 한다.
- [친구] 공부한 내용을 바탕으로 컨닝 페이퍼(pre-label)를 만든다.
- [나] 친구(AI)가 건네준 컨닝 페이퍼를 참고해 시험을 본다
얼핏 보면 훌륭한 것 같지만 결국 모델은 초기 소량의 데이터로만 학습한 그다지 똑똑하지 않은 모델일 가능성이 높습니다. 제대로 공부도 하지 않은 친구가 만든 컨닝 페이퍼는 신뢰하기 어려운 구석이 많을 것 같습니다… 오히려 우리의 머리를 복잡하게 할 가능성이 높겠죠.
그래서 주기적으로 친구에게 공부를 가르쳐 주기로 했습니다. 24시간 붙어 공부를 가르쳐주기는 어려우니까 적당한 주기로 수업을 진행해 보겠습니다.
컨닝 페이퍼 버전 2
- [나] 일단 아무 문제(데이터)나 소량을 골라 직접 푼다.
- 다음을 반복한다.
- [친구] 내가 푼 문제로 공부(모델 학습)를 한다.
- [친구] 공부한 내용을 바탕으로 컨닝 페이퍼(pre-label)를 만든다.
- [나] 컨닝 페이퍼를 참고하여 소량의 문제(데이터)를 직접 푼다.
- [나] 친구(AI)가 건네준 컨닝 페이퍼를 참고해 시험을 본다
작업자가 작업을 진행할수록 모델이 공부하는 내용이 많아집니다. 만약 수업을 하루에 한 번씩 진행한다면 매일매일 똑똑해지는 모델을 만들 수 있고, 우리가 얻는 컨닝 페이퍼는 점점 더 정답에 가까워지고 신뢰할 수 있을 것 같습니다.
하지만 모든 내용을 한 번씩 공부한다고 해서 각 내용에 대한 실력이 똑같기는 어렵습니다. 이해가 잘 되는 내용이 있으면 그렇지 않은 내용도 있을 수 있으니까요. 그래서 친구가 잘 모르는 내용 위주로 수업을 진행하면 더 효과적일 것 같습니다
컨닝 페이퍼 버전 3
- [나] 일단 아무 문제(데이터)나 소량을 골라 직접 푼다.
- 다음을 반복한다.
- [친구] 내가 푼 문제로 공부(모델 학습)를 한다.
- [친구] 공부한 내용을 바탕으로 컨닝 페이퍼(pre-label)를 만든다.
- [친구] 컨닝 페이퍼를 만들면서 더 공부가 필요할 것 같은 문제를 골라본다(샘플링).
- [나] 친구가 고른 문제(데이터)를 직접 푼다.
- [나] 친구(AI)가 건네준 컨닝 페이퍼를 참고해 시험을 본다

자기가 약한 부분을 직접 파악하고 더 공부하겠다는 친구가 너무 대견스럽습니다. 이렇게 열심히 공부한 친구가 만들어 준 컨닝페이퍼를 갖고 시험을 보면 혹시 만점을 받는 건 아닌지 벌써부터 기대가 됩니다.
Active Learning 쉽게 알아보기
Active Learning 의 이런 과정을 그림으로 표현하면 아래와 같습니다.

그림을 통해 본 Active Learning 에서는 여러 가지 요소들이 존재합니다.
- 초기 학습량
- 학습 주기/추가 학습량
- 샘플링 방법
이 중 가장 연구가 활발하게 진행되고 중요하게 다뤄지는 샘플링 방법에 대해 알아보고, 데이터헌트에서는 어떤 방법으로 Active Learning 을 통해 샘플링 작업 속도 에 효과적으로 도입했는지 살펴보겠습니다.
사실 액티브러닝, ActiveLearning 에는 여러 가지 방법론이 존재합니다.
Membership Query Synthesis(현재 모델이 학습했으면 하는 데이터를 직접 생성하는 방법), Stream-based Selective Sampling(순차적으로 오는 데이터를 두고 학습 여부를 결정하는 방법), 그리고 Pool-based Sampling(보유한 전체 데이터를 두고 그 안에서 어떤 데이터를 먼저 학습할지 결정하는 방법)이 대표적입니다. 이번에는 그중 Pool-based Sampling에 대해 이야기하려 합니다. 그 이유는 아래에서 부연 설명하도록 하겠습니다.
샘플링 방법
데이터헌트에서는 Active Learning의 몇 가지 전략 중 Pool-based Sampling을 적용할 경우가 많습니다. 왜냐하면 작업에 앞서 전체 데이터셋을 확보하는 경우가 많기 때문입니다. 그리고 실제 서비스에서도 많은 데이터를 먼저 보유하고 있는 상황이 많은지 Pool-based 방식에서 가장 많은 연구가 이루어지고 있습니다.
많은 데이터 중 어느 것을 먼저 학습시키면 모델이 더 빠르게 똑똑해질까요? 이것 또한 방법이 여러 가지 존재하지만 그중 Uncertainty Sampling이 주목받고 있습니다. 구현도 쉽고, 범용적이며, 샘플링 속도도 빠르는 장점이 크기 때문입니다. (이 점은 상당히 중요합니다. 모델은 쉬더라도 작업은 계속 진행되기 때문에 최대한 빠르게 pre-label을 전달할 수 있어야 하기 때문이죠.)
Uncertainty Sampling이란 단어 그대로 불확실성에 의거하여 데이터를 고르는 방법입니다. 모델이 뭐가 답인지 많이 헷갈릴수록 어려운 문제라는 것이 전제입니다. 불확실성을 판단하는 방법은 크게 3가지가 있는데, 그중 Maximum Entropy라는 엔트로피 기반의 불확실성 계산이 가장 유명합니다.
구체적으로...
가장 간단한 분류(Classification) 문제를 살펴보겠습니다. 이 모델은 3가지 클래스를 분류하고 있고 각 입력 데이터에 대해 얻은 결과는 아래와 같습니다.

Least Confidence: 가장 유력한 클래스의 확률이 가장 낮은 데이터 선택
- 각 후보의 가장 유력한 후보와 그 확률을 살펴보면, 후보 1: 0.5 (강아지), 후보 2: 0.34 (햄스터), 후보 3: 0.4 (강아지 또는 고양이)
- 이에 따라 우선순위는 후보 3 > 후보 1 > 후보 2
Margin Sampling: 가장 유력한 클래스(Top-1)와 그다음 유력한 클래스(Top-2)의 확률 차이가 가장 작은 데이터 선택
- 각 후보의 Top-1과 Top-2를 두고 계산하면, 후보 1: 0.1 (강아지 – 고양이), 후보 2: 0.01 (햄스터 – 강아지), 후보 3: 0.0 (강아지 – 고양이)
- 이에 따라 우선순위는 후보 3 > 후보 2 > 후보 1
Maximum Entropy: Entropy가 가장 높은 데이터 선택
- 엔트로피를 구하는 방법은

- 각 후보의 엔트로피를 계산하면 후보 1: 1.361, 후보 2: 1.585, 후보 3: 1.522
- 이에 따라 우선순위는 후보 2 > 후보 3 > 후보 1
각 방법에서 서로 다른 결과를 얻을 수 있습니다. 그중 activelearning에는 Maximum Entropy 방법이 가장 효과가 좋다고 알려져 있습니다 (정보 이론에서 엔트로피의 개념을 열심히 강조하는 것은 다 이유가 있었다).
예시는 데이터 단 3개를 들었지만 실제로는 적게는 1만 개, 많게는 10만 개 단위의 큰 데이터 중에서 먼저 학습해야 할 녀석들을 골라야 합니다. 시간이 많이 걸리는 일이기도 하고, 모종의 이유로 전체 데이터를 대상으로 위와 같은 과정을 거치지는 않는데 데이터헌트에서는 어떤 이유에서 그랬는지 또 실험 결과는 어땠는지 설명하겠습니다.
데이터헌트의 Active Learning 실험
Beluch et al.에서 연구한 내용에 따르면 Unlabeled set에서 K-most uncertain samples를 뽑는 방법은 그다지 효과적이지 않다고 말하고 있습니다. 그 이유는 데이터셋 사이즈 대비 클래스의 수나 복잡도가 떨어지는 데이터에서는 정보의 중복이 발생하기 쉽기 때문이라고 합니다. 따라서 핵심은
- 보다 작은 subset에서 샘플링 하는 것이 효과적이고, 해당 subset은 random 하게 뽑기
- 장점은 정보의 중복을 줄일 수 있다는 점
- 단점은 Global optimal을 찾아가기 어렵다는 점
의 사이즈를 어느 정도로 설정할 것인가는 실험에 따라 다를 수 있습니다. 저희의 실험에서는 전체 데이터 사이즈의 10%로 설정했습니다.
실험설계
- 모델: YOLOv5s
빠른 실험을 위해 가벼운 모델로 진행했습니다 - Uncertainty 계산 대상: 결과로 얻는 각 Bounding box의 class probability
Bounding box에는 클래스뿐만 아니라 좌표 또한 존재하지만 정답을 모르는 상태에서 좌표의 uncertainty를 구하기가 쉽지 않았습니다
- 데이터셋: 비공개
영업 비밀…
- 초기 labeled 데이터양: 전체의 2%
초기 모델을 학습하기 위한 최소 데이터 양을 정했습니다. 너무 적으면 모델이 학습할 내용이 없고, 너무 많으면 그만큼 작업자들이 pre-label을 활용하지 못한다는 의미이기 때문에 적정 수준을 정했습니다.
- 샘플링 주기 및 수량: 20 Epoch마다 전체 데이터의 10%씩 추가
이것 또한 샘플링 및 모델 재학습의 주기가 실제 작업자의 작업 효율에 영향을 미치기 때문에 일정 수준을 정했습니다.
- 전체 학습량: 총 100 Epoch 실험을 통해 전체의 42%에 해당하는 데이터가 레이블링 되고 학습에 쓰인다고 설정
모든 데이터가 전부 학습에 쓰이는 시나리오는 없습니다. 왜냐하면 그 말인즉슨 이미 레이블링 작업이 끝났다는 것이기 때문입니다. 모든 데이터가 전부 레이블링 되기 전에 모델은 학습을 마치고 pre-label을 전달할 준비가 되어 있어야 합니다.
샘플링 작업 속도 를 높이는 실험 방법 1
실험 방법
- 아직 레이블링이 되지 않은 데이터()에서 20%를 랜덤하게 샘플링한다. 이 데이터의 집합을 이라고 한다.
- 의 모든 데이터에 대해 모델 추론 결과를 얻고, Entropy 값이 가장 높은 개의 데이터를 고른다 (실험 설계에 따라는 전체 데이터의 10%로 설정한다)
- 이미 레이블링이 되어 있는 데이터 집합()에 개의 데이터를 추가하여 모델을 재학습한다.
- 위의 과정을 매 20 epoch마다 진행하여 총 100 epoch까지 학습한다.
이렇게 했을 때 실험 결과는 mAP 기준 0.41 → 0.41로 변화가 없었습니다. 여기서 비교 군은 Active Learning을 진행하지 않고 무작위로 데이터를 골라 학습을 진행한 모델입니다.
분명 논문을 통해 연구된 내용으로는 효과적이었던 알고리즘이 이번 실험에선 왜 효과가 없었을까요? 그 이유를 여러 가지 생각해 봤습니다.
- 논문의 실험과는 다른 초기 데이터양, 샘플링 양 및 재학습 주기 문제
- 데이터셋 학습 자체의 난이도
- 샘플링 방법의 차이
저희는 이 중 세 번째 – 샘플링 방법을 수정해 보기로 했습니다. 왜냐하면 첫 번째는 작업 스케줄링에 크게 영향을 줄 수 있고, 두 번째는 제어하기 어려운 요소이기 때문이었습니다.
생각해 보면 이 방법이 시사하는 바는 무엇일까요? 예시를 들어보겠습니다.
전교생이 1000명 있는 학교에서 임의로 5개 학급으로 나눠 놓고 하나의 학급에서 성적 순으로 100명을 선발하는 것으로 표현할 수 있습니다.
- 그냥 전교생 중 성적순으로 100명을 뽑으면 성적에 대해 과하게 편향된 샘플링이 될 수 있고
- 학급의 수를 10개로 늘려 한 학급 당 100명으로 만든 후 하나의 학급을 골라 100명을 뽑으면 결국 그 반에 있는 모든 학생을 뽑는 일이고, 이건 랜덤 샘플링과 다를 바가 없습니다.
모델이 현재 어려워하는 데이터만 모아서 학습을 진행하기보다는 조금 더 넓은 범위의 학습이 효과적이지 않을까요? 우리는 이것을 학습 데이터가 경계(decision boundary) 근처에 편향(bias) 되었다고 이야기하고 이런 학습은 특정 클래스에 편향된 학습을 야기하거나, 앞으로 학습해야 할 다른 데이터의 분포를 잘 고려하지 못하는 generalized 가 덜 된 학습을 유도하게 될 것입니다. 따라서 이 문제를 해결하기 위해 다른 방법을 제안했습니다.
샘플링 작업 속도를 높이는 실험 방법 2
실험 방법
- 아직 레이블링이 되지 않은 데이터()에서 20%를 랜덤하게 샘플링한다. 이 데이터의 집합을 이라고 한다.
- 의 모든 데이터에 대해 모델 추론 결과를 얻고, Entropy 값이 가장 높은 개의 데이터를 고른다 (실험 설계에 따라는 전체 데이터의 10%로 설정한다)
- 에서 랜덤하게 개의 데이터를 샘플링한다.
- 이미 레이블링이 되어 있는 데이터 집합()에 개의 데이터를 추가하여 모델을 재학습한다.
- 위의 과정을 매 20 epoch마다 진행하여 총 100 epoch까지 학습한다.
데이터 샘플링에 있어 decision boundary에 너무 집중되지 않은 Generalized Subset을 만들기 위해 나머지 그룹에서 정말 랜덤하게 샘플링을 수행합니다. 과 에서 샘플링 되는 데이터의 비율을 50:50으로 만들 수도, 30:70으로 만들 수도 있습니다. 하지만 이 실험에서는 너무 다양한 실험을 진행하지는 않았고 50:50으로 진행했습니다.
결과는 0.41 → 0.43으로 같은 양의 데이터를 학습했음에도 여러 번의 반복 실험 결과 유의미한 샘플링 속도 성능 향상을 얻을 수 있었습니다.

결론
이번 글에서는 Active Learning에 대해 설명하고 데이터헌트에서 샘플링 작업 속도 에 어떻게 적용했는지에 대해 소개했습니다.
작업자의 작업 효율 향상을 위해 Pre-label을 전달하는 데 사용되는 모델을 학습하는 과정에서, 아무 전략 없이 학습하는 것이 아니라 아주 복잡하지는 않지만 나름의 전략과 실험을 통해 더 나은 모델을 만들 수 있었습니다.
LLM (거대 언어 모델) 작동 원리
언어 모델의 유형
언어 모델에 대한 연구는 현재에도 진행형입니다. 본격적으로 작동 원리에 대해 이해하기 전에, 개발 단계를 네 가지로 나눠 알아보겠습니다.
- SLM (Small Language Model): 제한된 양의 텍스트 데이터를 학습하여, 작업 전반에 걸쳐 국소적인 문맥을 이해하는 데에 초점을 맞춥니다. 작은 규모에도 불구하고, SLM은 가볍고 실행 속도도 빠른 특징을 가지고 있습니다.
- NLM (Neural Language Model): NLM은 기존의 통계 기반 언어 모델보다 더 정확한 성능을 제공합니다. 이러한 모델은 주로 단어 임베딩, 문장 완성, 기계 번역 등 다양한 NLP 작업에 사용됩니다.
- PLM (Pretrained Language Model): PLM은 대규모 데이터셋으로 미리 학습되며, 이후 다양한 NLP 작업에 전이학습(Transfer Learning)을 통해 적용됩니다. BERT와 GPT와 같은 주요 모델들은 이 PLM에 속합니다.
연구자들은 PLM을 확장하면 다운스트림 작업에서 모델 용량이 향상될 수 있다는 사실을 발견했습니다. 많은 연구에서 훨씬 더 큰 PLM을 훈련하면서 성능 한계를 탐색해보고자 했죠. 이러한 대형 PLM은 소형 PLM과는 다르게, 일련의 복잡한 작업을 해결할 때 놀라운 능력을 발휘한다는 점이 밝혀졌습니다. 예를 들어, GPT-3는 상황을 학습하여 단발성 과제를 해결할 수 있는 능력을 가졌지만 GPT-2는 그렇지 못했죠. 따라서 연구 커뮤니티에서는 이러한 대형 PLM을 두고 “대규모 언어 모델(LLM)”이라는 용어를 사용하기 시작했습니다. 즉, LLM은 언어 모델의 현주소이자 최종 개발 단계라고 할 수 있습니다.
LLM에서 자주 사용하는 용어
아래는 LLM을 다루는 문서 및 논문에서 자주 사용하는 단어의 정의입니다. 미리 알아두면 LLM에 대해 이해하는 데에 도움이 될 수 있습니다.
- 단어 임베딩: 단어들을 고차원 벡터로 표현하여 각 단어 간의 유사성과 관계를 캡처하는 기술
- 주의 메커니즘: 입력 시퀀스의 다양한 부분에 가중치를 부여하여 모델이 중요한 정보에게 집중할 수 있도록 하는 기술
- Transformer: 주의 메커니즘을 기반으로 한 인코더와 디코더 구조의 신경망 모델로, 길이가 다른 시퀀스를 처리하는 데 탁월한 성능
- Fine-tuning LLMs: 사전 학습된 대규모 언어 모델을 특정 작업에 적용하기 위해 추가 학습하는 과정
- Prompt engineering: 모델에 입력하는 질문이나 명령을 구조화하여 모델의 성능을 향상시키는 과정
- Bias (편향): 모델이 학습 데이터의 불균형이나 잘못된 패턴을 포착하여 실제 세계의 현실과 일치하지 않는 결과를 내놓는 경향
- 해석 가능성: LLM이 가진 복잡성을 극복하고 AI 시스템의 결과와 결정을 이해하고 설명할 수 있는 능력
LLM 작동 방식 및 원리

이제 본격적으로 LLM의 작동 원리에 대해 살펴보겠습니다. LLM이 언어를 학습하는 과정에는 딥 러닝의 원리가 활용됩니다. LLM은 딥 러닝의 방식으로 방대한 양을 사전 학습(Pre-trained)한 전이 학습 (Transfer) 모델이라고 할 수 있습니다.
LLM은 문장에서 가장 자연스러운 단어 시퀀스를 찾아내는 딥 러닝 모델입니다. 딥 러닝 기술을 사용하여, 문장에서 단어와 구문을 인식하고 이를 연관시켜 언어적 의미를 파악할 수 있죠. 이러한 과정에서, LLM은 문법 규칙이나 단어의 사전적 의미와 같은 구체적인 규칙은 따르지 않고, 빈도수나 문법적인 특성 등을 학습하여, 문맥상 올바르게 문장을 생성할 수 있습니다. 즉, 문장 속에서 이전 단어들이 주어지면 다음 단어를 예측하거나 주어진 단어들 사이에서 가운데 단어를 예측하는 방식으로 작동합니다.
이러한 인공 신경망 기반의 언어 모델들은 방대한 양의 데이터를 학습하여, 마치 인간처럼 자연스러운 문장을 생성할 수 있습니다. LLM을 학습시키는 방법은 대부분 큰 양의 텍스트 데이터를 기계학습 알고리즘에 입력하는 것입니다. 이때 일반적으로, 먼저 토큰화(tokenization)과 같은 전처리 과정을 거쳐 문자열 데이터를 분리한 다음, BERT, GPT, GPT-2, GPT-3, T5 등의 모델을 사용하여 학습합니다.
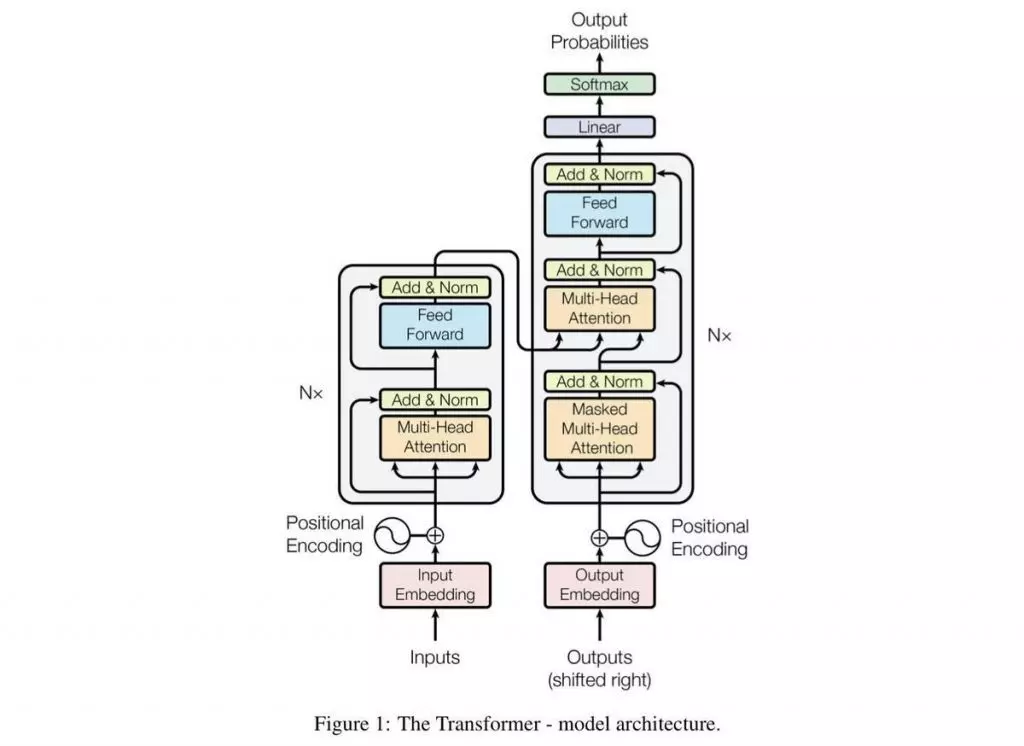
위 사진은 Google이 발표한 언어 모델 Transformer의 Decoder 부분만 사용하는 GPT 모델입니다. GPT는 기존 모델보다 더욱 세밀하게 사람의 의도를 이해할 뿐만 아니라, 적절한 답변을 내릴 수 있으며 사람처럼 말하는 법까지 알고 있습니다.
LLM 핵심 기술
오랜 시간동안 연구가 이어지면서 지금의 LLM이 될 수 있었습니다. 여러 중요한 기법들이 개발 과정에서 등장하면서 LLM의 역량이 크게 향상될 수 있었죠. 여기서는 LLM이 유능한 학습자가 될 수 있도록 하는 중요한 기술을 간략하게 소개합니다.
스케일링
확장(Scaling up)은 대규모 데이터셋과 컴퓨팅 리소스를 활용하여 언어 모델의 성능을 더욱 향상시키는 것을 의미합니다. 대규모 데이터셋을 사용하면 모델이 더 많은 언어 정보를 습득하고, 더 정확하게 예측할 수 있습니다. 대표적으로 LLM의 확장은 두 가지 방법이 있습니다. 첫째는 모델의 크기를 늘리는 방법으로 더 많은 계산 능력과 메모리를 필요로 합니다. 두번째는 데이터 증강(Data augmentation)을 통해 모델을 확장하는 방법입니다. 데이터 증강은 기존 데이터를 변형시켜 더 많은 데이터를 만드는 방법으로, 모델이 다양한 언어 패턴을 습득할 수 있도록 돕습니다.
LLM의 모델 확장은 다양한 NLP 작업에 적용할 수 있도록 성능을 향상시킬 수 있다는 장점이 있지만, 컴퓨팅 리소스와 계산 복잡도가 증가한다는 점에서 유의해야 합니다. 또한 사전 학습 데이터의 품질은 좋은 성능을 달성하는 데에 핵심적인 역할을 하므로, 사전 학습 코퍼스를 확장할 때 데이터 수집 및 정리 전략을 고려하는 것이 중요합니다.
학습
다양한 병렬 전략이 공동으로 활용되는 LLM의 네트워크 파라미터를 학습시키기 위해서는 분산 훈련 알고리즘이 필요합니다. 분산 학습을 지원하기 위해 DeepSpeed 및 Megatron-LM과 같은 병렬 알고리즘의 구현 및 배포를 용이하게 하는, 여러 최적화 프레임워크가 출시되었죠. 또한 훈련 손실 급증을 극복하기 위해 재시작 및 혼합 정밀도 훈련과 같은 최적화 트릭도 훈련 안정성과 모델 성능에 핵심적인 역할을 합니다. 최근에는 GPT-4에서 훨씬 작은 모델로 대규모 모델의 성능을 안정적으로 예측할 수 있는 특수 인프라와 최적화 방법이 개발 화두에 올라있습니다.
능력 도출
대규모 말뭉치에 대한 사전 학습을 마친 LLM은 다양한 작업을 수행할 수 있습니다. 하지만 LLM이 어디까지 할 수 있는지 명시적으로 알 수 있는 방법이 없기 때문에, 적절한 작업 지침이나 특정 상황에 맞는 학습 전략을 제시해야 합니다. 예를 들어, 연쇄적 사고 프롬프트는 중간 추론 단계를 포함함으로써 복잡한 추론 과제를 해결하는 데에 유용하다고 밝혀졌습니다. LLM에 대한 인스트럭션 튜닝을 수행하면, 보이지 않는 과제에 대한 LLM의 일반화 가능성을 향상시킬 수 있다는 연구 결과가 있었죠.
정렬 튜닝(Alignment Tuning)
Alignment tuning은 입력 문장과 레퍼런스 문장 간의 정렬 정보를 모델 학습에 이용하는 방법입니다. 기존의 Fine-tuning 방식은 입력 문장과 해당하는 레이블로 이루어진 데이터셋을 기반으로 모델을 학습시키는 반면, 정렬 튜닝은 입력 문장과 레퍼런스 문장 간의 정렬 정보도 함께 이용합니다. 정렬 튜닝은 fine-tuning 방식과 함께 사용할 수도 있습니다.
Alignment tuning은 언어 번역과 같은 작업에서 유용하게 활용할 수 있습니다. 예를 들어, "나는 사과를 먹는다"와 "I eat an apple"이라는 레퍼런스 문장이 있다고 가정해보겠습니다. 정렬 정보를 이용하여 "나는"과 "I", "사과를"과 "an apple"을 서로 매핑하여 입력 문장에서 적절한 위치에 배치할 수 있습니다. 이러한 정렬 정보를 활용하면 모델이 문장의 의미와 문법적 구조를 보다 정확하게 이해하고, 더욱 자연스러운 번역 결과를 제공할 수 있습니다.
도구 조작
본질적으로 LLM은 방대한 일반 텍스트 말뭉치를 가지고 훈련되었기 때문에, 텍스트 형태로 잘 표현되지 않는 작업에 대해서는 성능이 떨어질 수 있습니다. 또한 사전 학습 데이터에 한정되어 있어 최신 정보를 캡처할 수 없는 한계도 가지고 있었죠. 이러한 문제를 해결하기 위해 최근, 외부 도구를 사용하여 LLM의 결함을 보완하는 이론이 주목 받고 있습니다.
최근에는 ChatGPT가 외부 플러그인을 사용하는 메커니즘을 활성화했는데, 이는 LLM의 ‘눈과 귀’가 되어주면서 용량 범위를 광범위하게 확장하는 역할을 해주었습니다.
주요 모델과 역사
역사
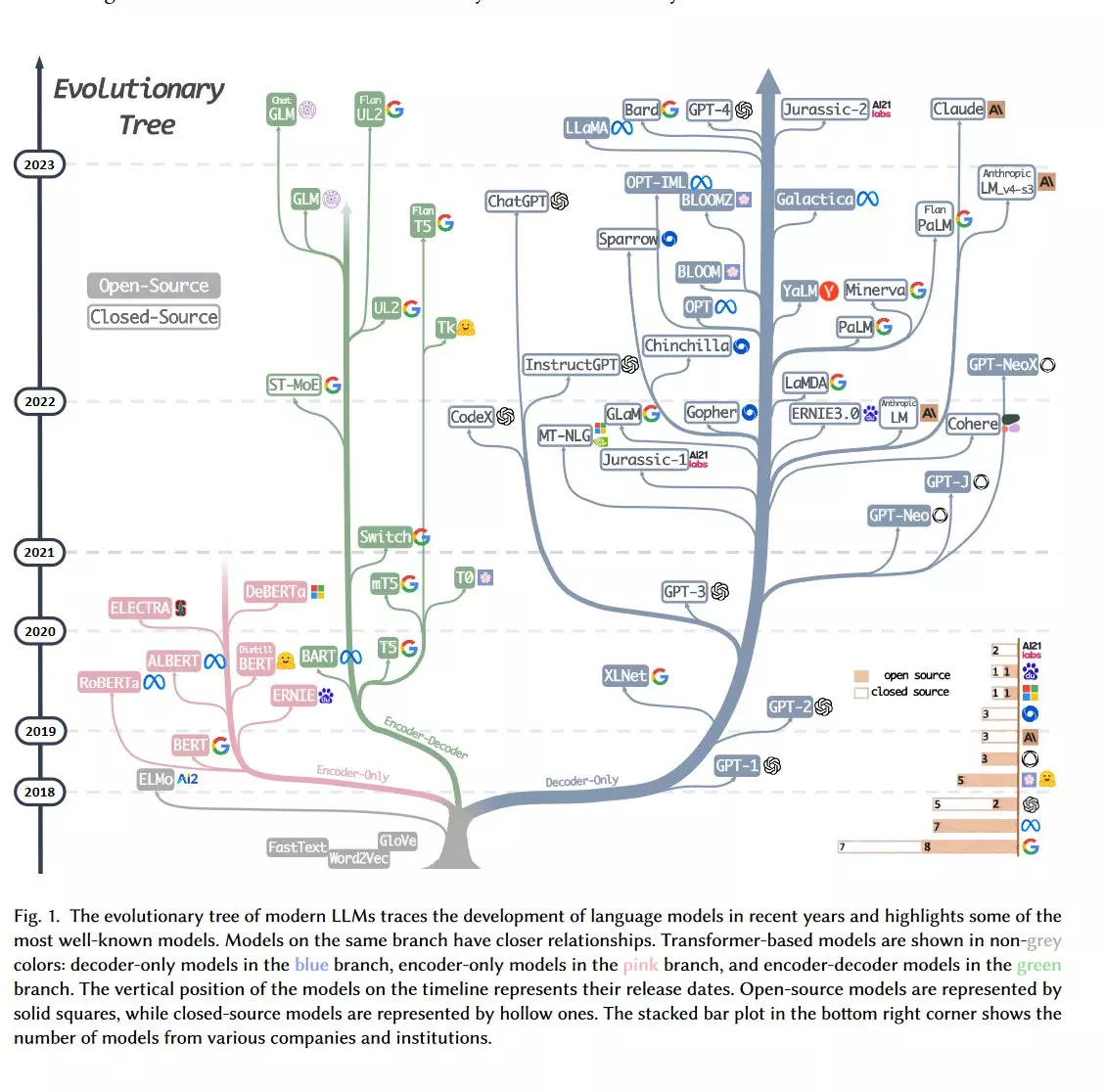
LLM의 시작은 1960년대에서 시작되었습니다. 간단한 챗봇 프로그램에서 시작되어 오늘날의 ChatGPT와 같은 대형 모델이 탄생했죠. 아래는 LLM의 역사 중 핵심적인 이벤트와 그에 대한 설명입니다.
- Eliza (Joseph Weizenbaum, 1960s): 패턴 인식을 사용하여 사용자의 입력을 질문으로 변환하고, 미리 정의된 규칙 집합을 기반으로 응답을 생성
- LSTM (1997): 더 깊고 복잡한 신경망의 생성을 통해 더 많은 양의 데이터를 처리
- CoreNLP (2010): 감정 분석 및 명명된 NTT 인식 등의 복잡한 NLP 작업이 가능한 도구 및 알고리즘 세트
- Google Brain (2011): NLP 시스템이 단어의 맥락을 더 잘 이해할 수 있도록 지원
- Transformer (2017): 더 크고 정교한 LLM 모델을 만들 수 있게 되었으며, AI 기반 애플리케이션의 기반이 된 GPT-3의 전신이 됨
또한 최근에는 연구자와 개발자가 자신만의 LLM을 구축할 수 있도록 지원하는 사용자 친화적인 프레임워크와 도구가 개발되었습니다. 이를 기반으로 LLM의 발전은 여전히 현재진행형이라고 할 수 있습니다.
주요 모델
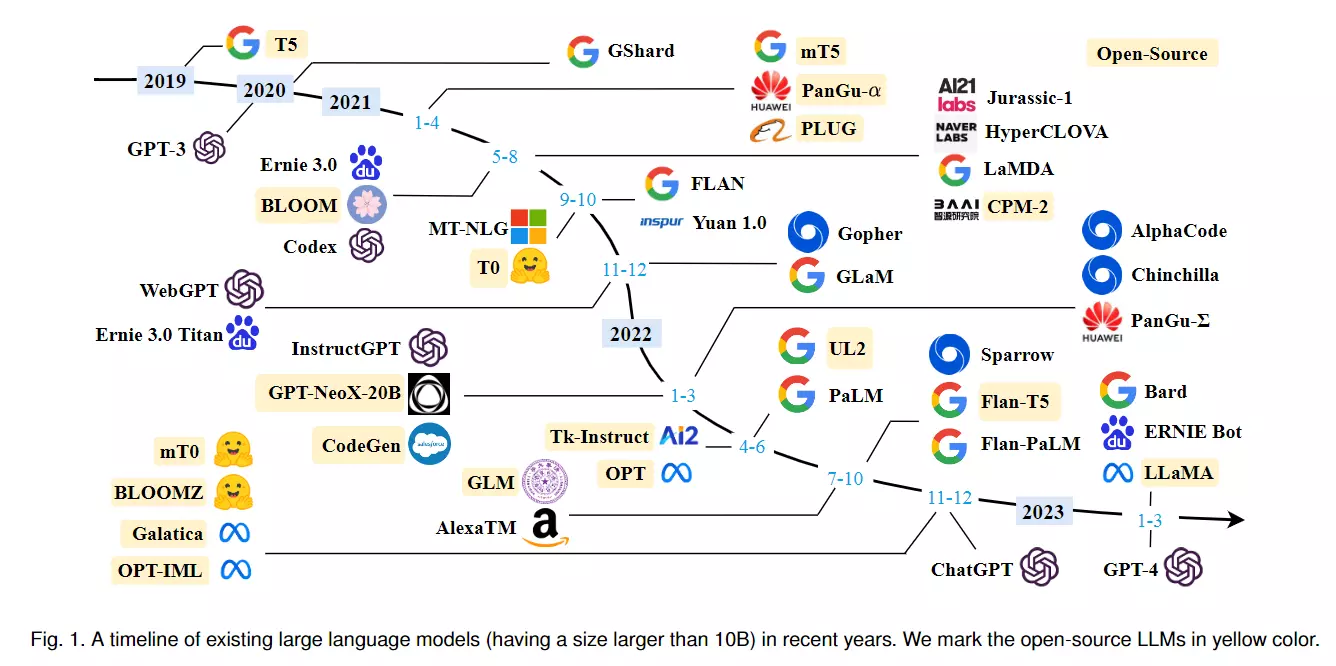
최근 가장 주목 받는 LLM의 핵심 모델은 다음과 같습니다.
- GPT-3.5 (OpenAI): GPT-3보다 약간의 성능과 안정성을 개선했으며, 광범위한 학습 데이터를 활용해 언어 이해 및 생성 능력을 향상시켜 SOTA를 달성했습니다.
- GPT-4 (OpenAI): GPT-3의 후속 모델로, 이전 버전보다 더 큰 모델 크기와 더 정교한 언어 이해와 생성 능력을 갖추고 있습니다.
- PaLM 2 (Google): Pre-trained Automatic Metrics를 사용한 언어 모델로, 사전 훈련된 언어 모델을 사용하여 기계 번역, 요약, 질문 응답 등의 다양한 NLP 작업에서 성능 평가를 위해 사용됩니다.
- LlaMA (Meta AI): Language Model Benchmark (LlaMA)에서 개발한 작업 중심 언어 모델로 sota를 달성했습니다. 다양한 자연어 처리 작업을 포함하여 언어 모델의 성능을 평가하고 비교하기 위해 사용됩니다.
'say와 AI 챗봇친구 만들기 보고서' 카테고리의 다른 글
| 엔비디아 'RTX4090' 품귀…원인은 AI (2) | 2023.10.20 |
|---|---|
| LLM (거대 언어 모델) Use cases (0) | 2023.10.19 |
| YOLO Object Detection, 객체인식 - 개념, 원리, 주목해야 할 이유, Use Case (1) | 2023.10.19 |
| 보안 AI 인공지능, 활용 사례와 적용 기술 (1) | 2023.10.19 |
| ChatGPT를 넘어, 생성형 AI(Generative AI)의 미래 – 1, 2편 (2) | 2023.10.19 |



