
LLM (거대 언어 모델) Use cases
스타트업 LLM 사용 사례
실제로 많은 스타트업이 파운데이션 모델을 토대로 LLM을 비즈니스에 투입하고 있습니다. 여러 기업들의 LLM 적용 사례를 보면 다양한 모델을 활용해 비즈니스의 색깔에 맞게 Tuning했다는 것을 알 수 있습니다. 여기서 그들이 선택한 파운데이션 모델의 평가는 비용과 성능, 정확성을 토대로 결정됩니다. 대부분의 기업은 여전히 OpenAI의 모델을 신뢰하는 경향이 있습니다. 다만 모델이 개선되고 더욱 세분화되거나 업종에 특화된 모델이 등장하기 시작하면 더욱 다양해질 것입니다. 여기서는 스타트업 생태계가 LLM을 활용하는 방식에 대해 알아보겠습니다.
Yoodli
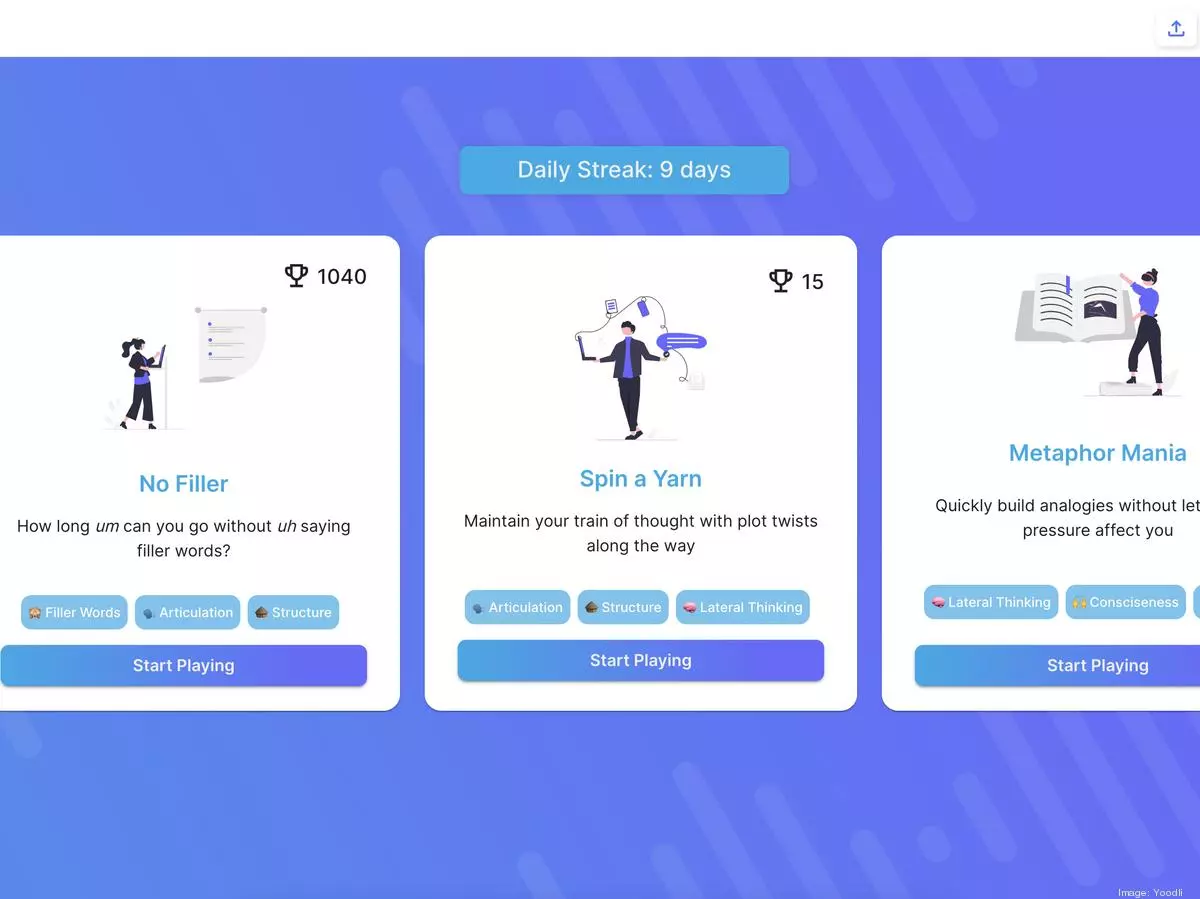
- LLM을 사용해 사용자에게 텍스트 기반의 피드백 형태로 AI 기반 스피치 코칭을 제공
- 청중이 이해할 수 있는 연설 요약과 간결성, 의역, 준비해야 할 후속 질문에 대한 제안을 제공
Compose AI
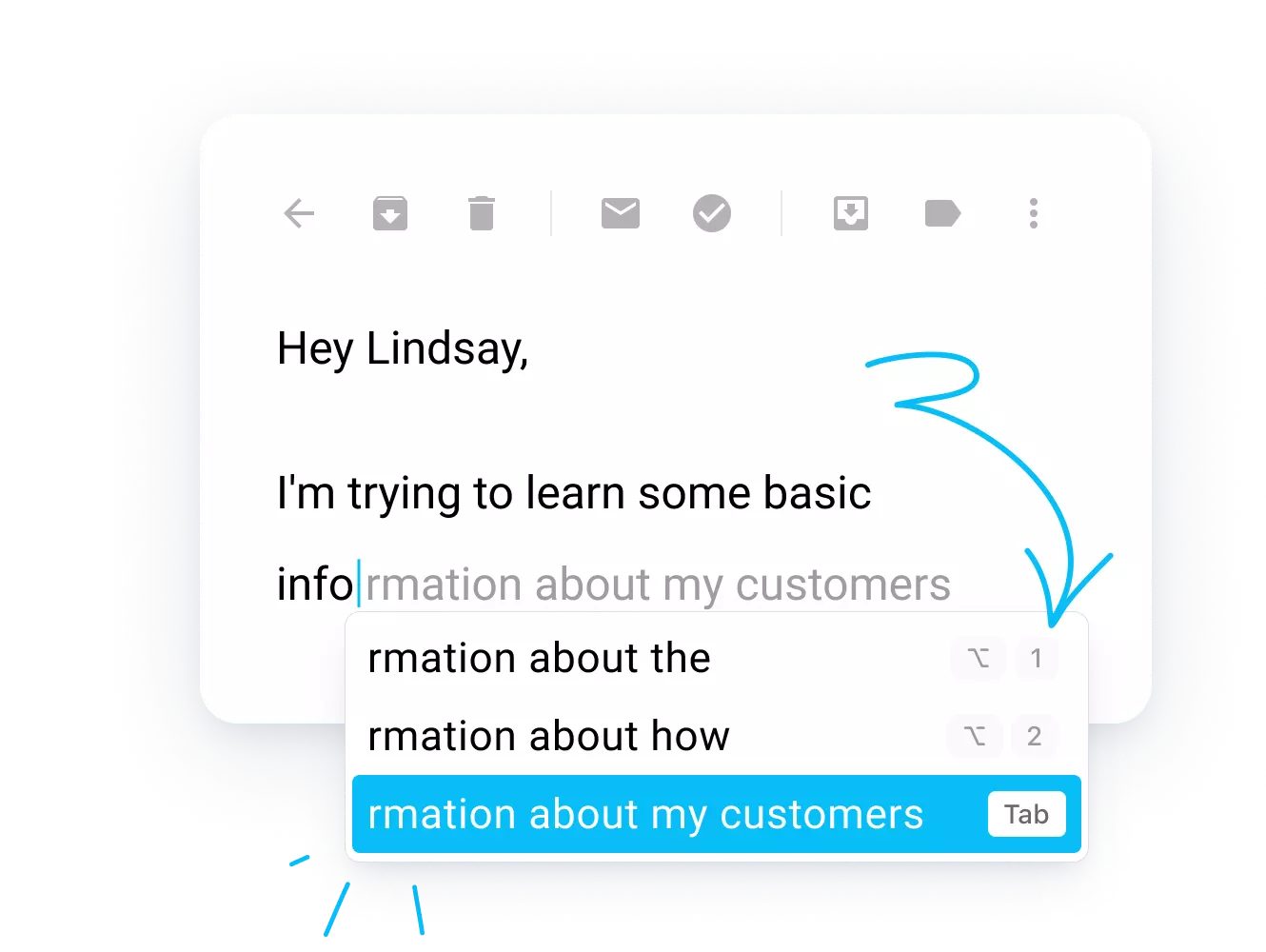
- 타이핑 과정을 자동화하여 텍스트를 생성하고, 문장을 고치거나 자동 완성을 지원
- 스토리, 블로그 게시물, 웹사이트 카피, 연구 주제 등에 대한 아이디어를 획득하고 메시지나 이메일에 답장
Speak
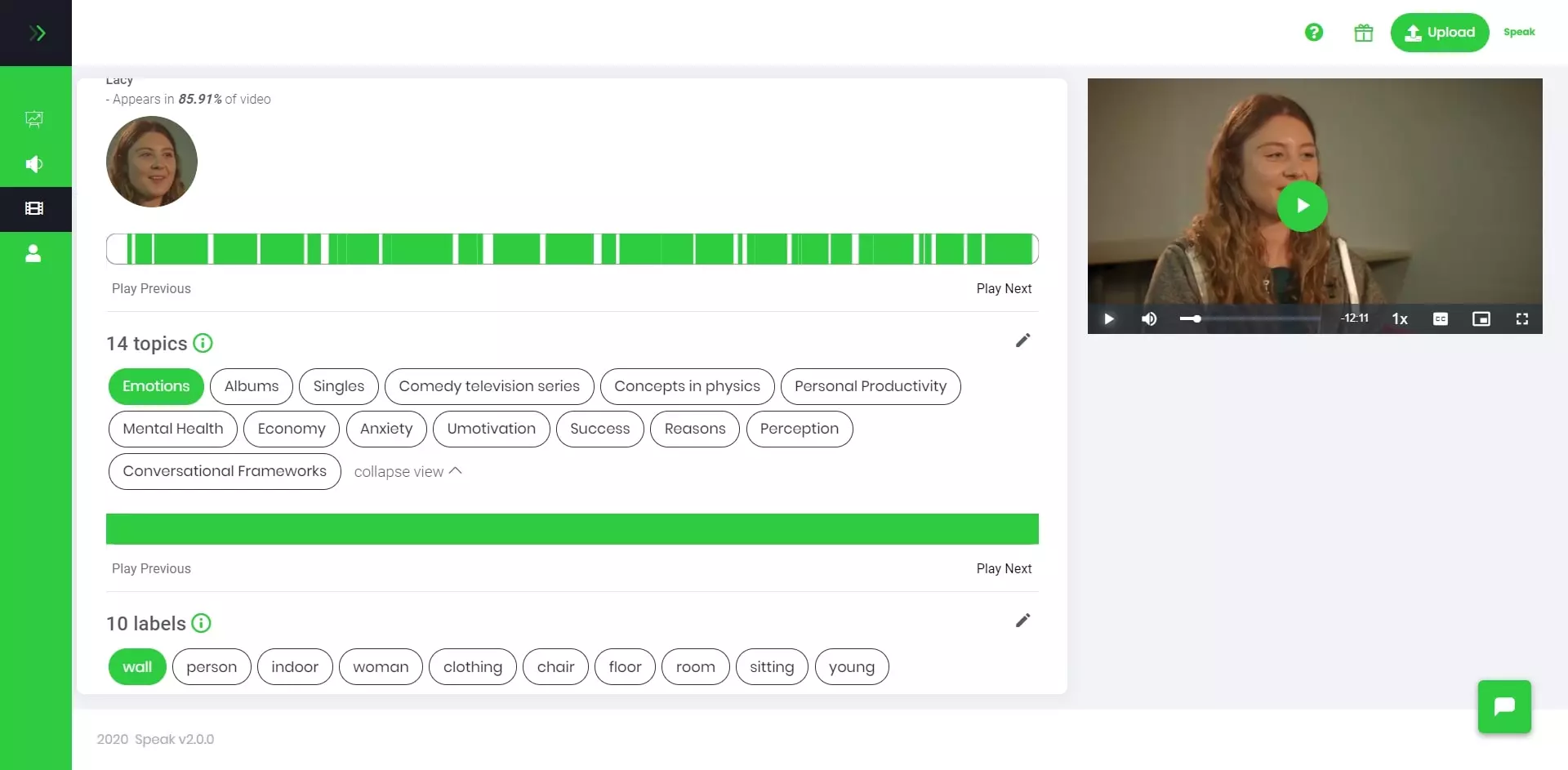
- 언어 학습자가 개방형 대화에 참여하도록 유도
- 보다 원어민처럼 말하는 방법에 대해, 맥락에 맞는 피드백 제공
Seekout
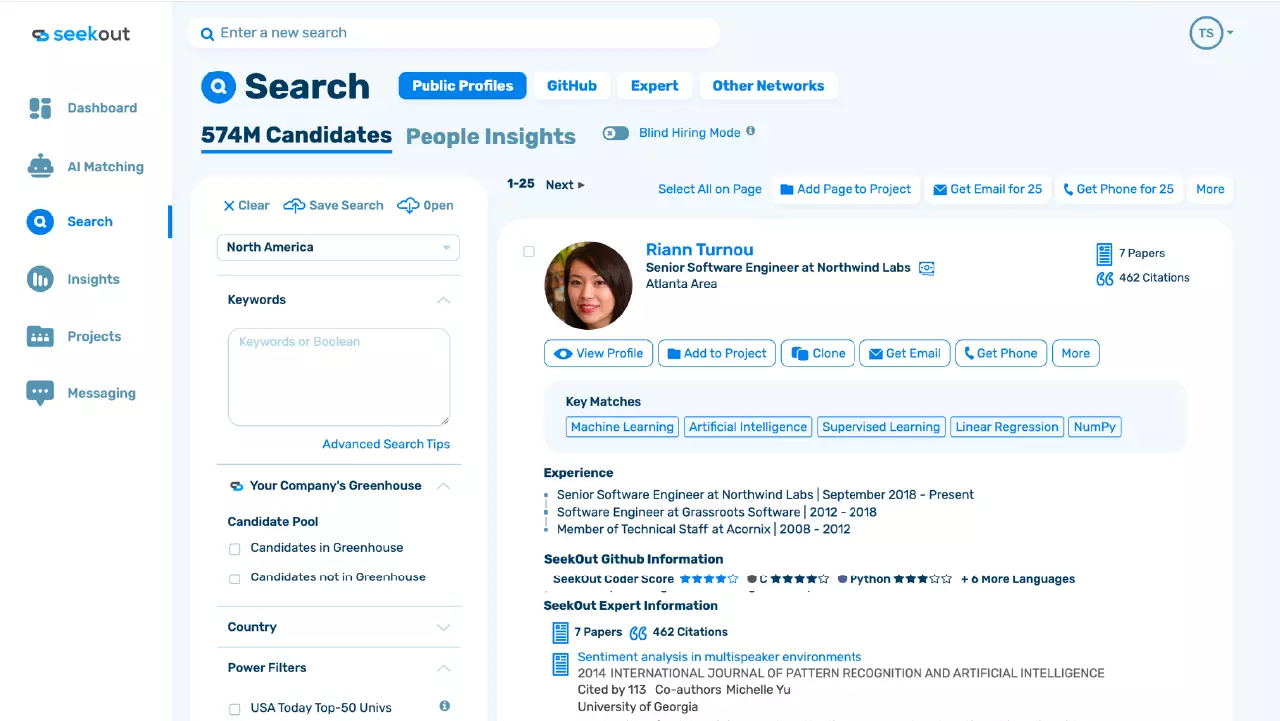
- NTT 추출 및 텍스트 요약, 코드 요약, 콘텐츠 생성, 시맨틱 검색, 임베딩 및 코드 생성
- 인재 확보 및 인재 관리를 지원
Coda
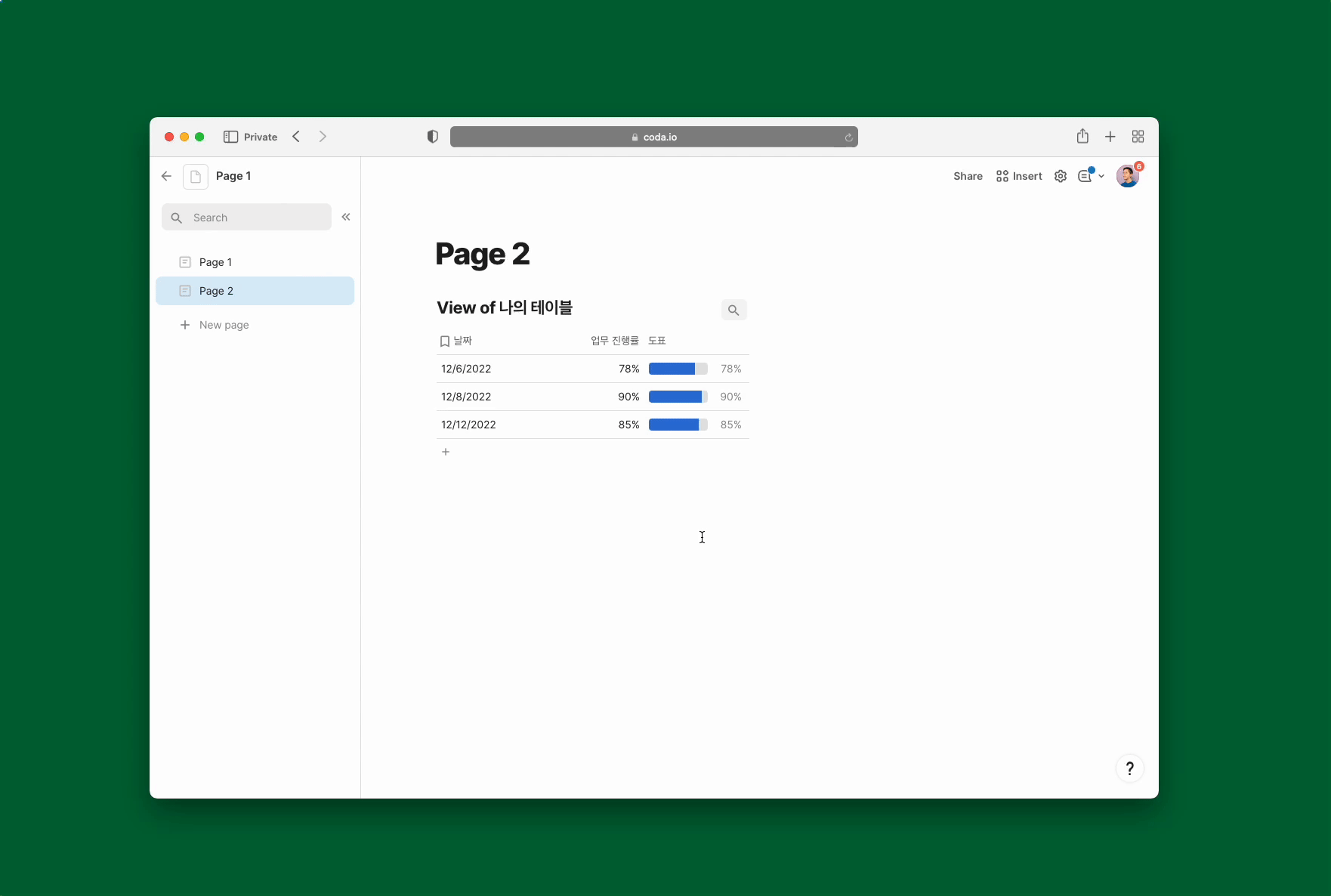
- 표를 지능적으로 작성 및 편집할 수 있도록 도와주는 업무 도우미
- 회의 요약, 실행 항목 추출, 자동화된 워크플로우를 위한 카테고리, 데이터 및 콘텐츠 생성
국내 LLM 구축 사례
GPT 모델이 전 세계적으로 강세를 띄고 있는 가운데, 대한민국에서도 이에 지지 않는 기술력을 선보이며 세계 무대에 두각을 드러내고 있습니다. 국내에서 LLM을 직접 구축한 사례에 대해 살펴보겠습니다.
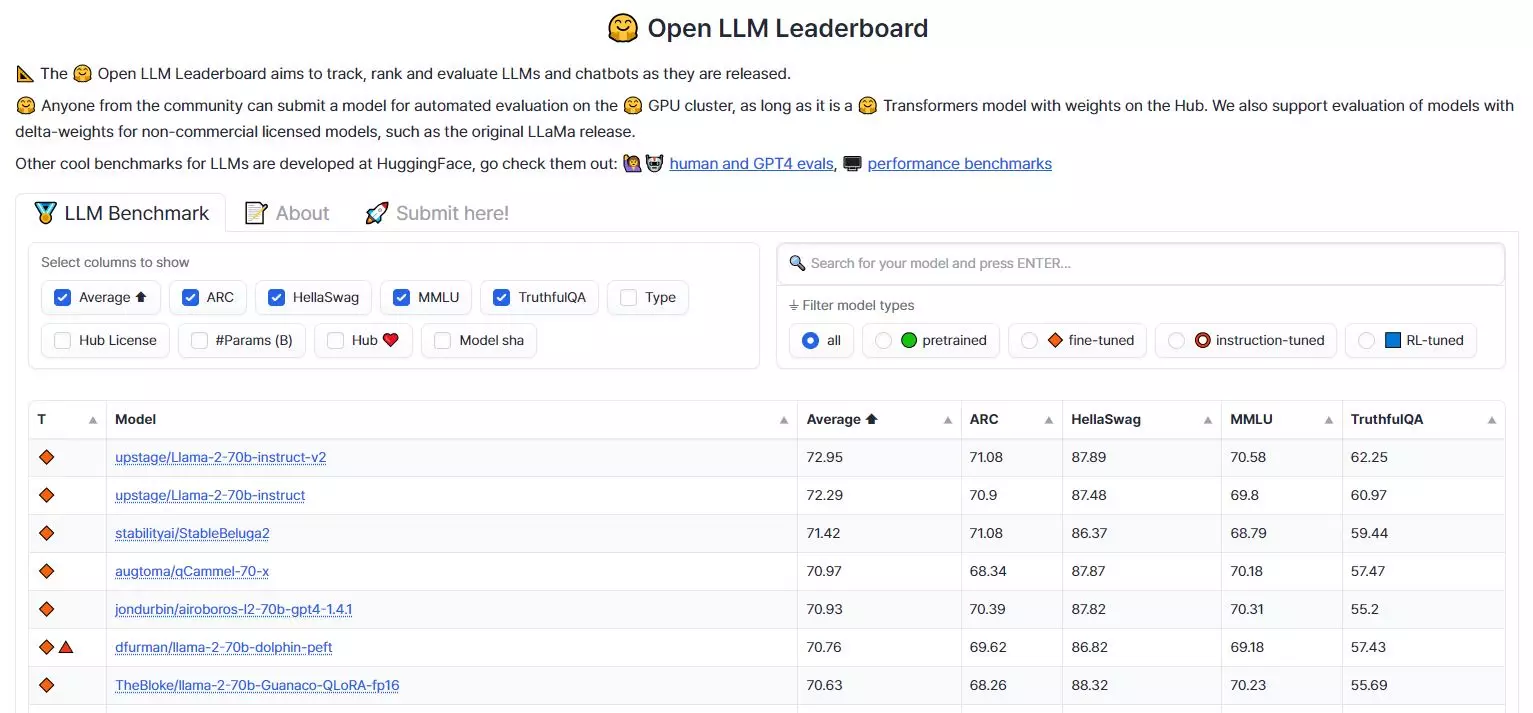
Huggingface의 오픈 LLM 리더보드는 전 세계 500여 개의 오픈 모델들이 추론과 상식 능력, 언어 이해 종합 능력 및 환각 현상 방지 등의 지표를 가지고 평균 점수로 경쟁하고, 공신력 있는 순위를 매기고 있습니다. 최근 업스테이지에서 개발한 생성 AI 모델이 Huggingface의 ‘오픈 LLM 리더보드’ 평가 점수에서 72.3점을 획득하여 GPT-3.5의 성능을 뛰어넘는 쾌거를 이뤄냈습니다.
지난 달 업스테이지가 공개한 30B(300억) 매개변수 모델은 평균 67점을 기록했으며, 같은 날에 발표한 메타의 LlaMA 2의 70B(700억) 모델을 추월했었죠. 이후 업스테이지는 더 많은 데이터를 기반으로 LlaMA 2 모델을 fine-tuning하여 세계 1위를 탈환하는 기록을 올렸습니다.
업스테이지는 최초의 한국어 자연어 이해(NLU) 평가 데이터셋인 '클루(KLUE)'를 개발하고, ICDAR OCR 세계대회에서 4개 종목에서 우승을 차지하며 성과를 거두었습니다. 또한, 국내 대표적인 멀티모달 생성 AI 서비스인 '아숙업(AskUp)'을 운영하여 130만 명의 이용자를 구독하게 되었으며, 프롬프트 엔지니어링과 파인튜닝에 대한 노하우 등 업스테이지만의 기술 자산을 결집하였습니다.
실전에서 LLM 구축 시 주의해야 할 점
사전학습 데이터가 LLM에 미치는 영향
소규모 PLM과 달리, 일반적으로 LLM은 막대한 계산 리소스를 사용하기 때문에 사전 학습을 여러 번 반복하는 것이 불가능에 가깝습니다. 따라서 LLM을 학습시키기 전에 잘 준비된 학습 코퍼스를 구축하는 것이 중요합니다. 사전 학습 훈련 말뭉치의 품질과 분포가 LLM의 성능에 어떤 영향을 미치게 될까요?
- 사전 학습 데이터의 품질
사전 학습 데이터의 품질은 모델이 언어의 다양한 측면을 잘 이해하고 표현할 수 있는지에 영향을 줍니다. 품질 좋은 데이터는 문법, 의미, 문맥 등을 잘 반영하고 있는 자연스러운 문장으로 구성되어야 합니다. 또한, 다양한 주제와 도메인의 데이터가 포함되어야 모델이 다양한 문제에 대해 잘 대응할 수 있습니다. 품질 좋은 데이터를 사용하면 모델은 보다 정확하고 의미 있는 문장 생성과 이해를 수행할 수 있게 됩니다. - 사전 학습 데이터의 분포
학습 데이터의 분포는 모델이 실제 문제를 처리할 때 언어의 다양한 측면을 얼마나 잘 다룰 수 있는지에 영향을 줍니다. 학습 데이터의 분포가 실제 응용 분야의 데이터와 유사하다면, 모델은 해당 분야의 언어 패턴과 도메인 특징을 잘 학습하여 더 정확한 예측을 할 수 있습니다. 예를 들어, 의료 분야에서 사용되는 모델은 의료 관련 텍스트 데이터로 사전 학습되는 것이 좋습니다. - 사전 학습 데이터의 양
기존 연구에 따르면 LLM 파라미터 규모가 커질수록 모델 학습에 더 많은 데이터가 필요한 것으로 나타났습니다. 모델 성능과 관련하여 모델 크기와 유사한 스케일링 법칙이 데이터 크기에서도 관찰된다는 것인데요. 최근 LLaMA는 더 많은 데이터와 긴 트레이닝을 통해 더 작은 모델도 좋은 성능을 달성할 수 있다는 것을 보여줬습니다. 따라서 연구자들은, 특히 모델 파라미터를 확장할 때 모델을 적절하게 훈련하기 위해서 고품질 데이터의 양에 더 많은 주의를 기울여야 한다고 강조하고 있습니다.
일반적으로 서로 다른 도메인이나 시나리오의 사전 학습 데이터는 서로 다른 언어적 특성이나 의미론적인 지식을 가지고 있습니다. 다양한 소스의 텍스트 데이터를 혼합하여 사전 학습함으로써, LLM은 광범위한 지식을 습득할 수 있게 될 뿐만 아니라 강력한 일반화 능력을 갖추게 됩니다. 물론 서로 다른 소스를 혼합할 때에는 다운스트림 작업에서 모델 성능을 저해하지 않도록 사전 학습 데이터의 분포를 신중하게 결정해야 합니다.
또한 특정 도메인에 대한 과도한 데이터 학습이 이뤄질 경우, 다른 도메인에 대한 LLM의 일반화 능력에 영향을 미칠 수 있습니다. 따라서, 연구자들은 사전 훈련 말뭉치에서 다른 도메인의 데이터 비율을 신중하게 결정할 필요가 있습니다. 이를 통해 특정 요구사항을 더 잘 충족하는 LLM을 개발할 수 있습니다.
거대 언어 모델 도입 시 기업이 주의해야 할 점
AI가 가져다주는 이점은 매우 크지만, 무턱대고 AI를 도입했을 경우 다른 부작용을 겪게 될 수도 있습니다. 따라서 아래와 같은 내용을 확인하고 전략적으로 접근하는 것이 중요합니다.
클라우드 애플리케이션 배포
비즈니스 요구 속도에 맞춰 애플리케이션 배포 속도를 높일 수 있다면 좋은 일이겠지만, 일부 기업은 애플리케이션 개발을 무모한 수준까지 확장하고 있다는 우려가 이어지고 있습니다. 시스템을 구축하고 배포하는 데 필요한 작업은 의외로 짧은 편에 속합니다. 그러나 기업 상당수가 애플리케이션의 전체적인 역할에 대해 충분히 고려하지 않고 있습니다. 전략상 필요해서 애플리케이션을 만들었다고 해도, 향후 살펴봤을 때 중복되는 기능일 가능성도 있습니다. 이런 혼란이 지속되면 관리 비용이 늘어나기 때문에 오히려 기업 미래를 해치는 길이 될 수 있습니다.
이를 극복하기 위해서는 AI를 도입하기 전에 명확한 목적과 전략을 수립해야 합니다. 기업은 어떤 문제를 해결하거나 어떤 가치를 창출하고자 하는지 목표를 설정해야 합니다. 목표를 정의하고 전략을 수립함으로써 AI 도입의 방향성을 잡을 수 있습니다.
시스템 확장 문제
AI 모델은 지속적인 개선과 최신 기술적 동향을 따라가는 것이 중요합니다. 모델의 성능을 평가하고 개선하기 위한 프로세스를 도입하고, AI 연구 및 개발 동향을 주시하여 최신 기술을 적용할 수 있어야 하죠.
그러나 빠르게 확장되는 AI 시스템을 지원하기 위해서는 기존보다 더 많은 양의 컴퓨팅 및 스토리지 리소스를 필요로 합니다. 즉, AI 시스템을 구축하기 위해서는 적절한 컴퓨팅 리소스와 인프라가 필요합니다. 기업은 충분한 리소스를 투입하여 인프라를 구축하고 유지보수할 수 있어야 합니다. 또한, AI 팀의 역량과 인력을 적절하게 보강하여 효과적인 운영을 할 수 있어야 합니다.
또한 AI 모델의 품질은 데이터의 품질에 크게 의존하므로 데이터 품질 관리가 중요합니다. 데이터의 정확성, 완전성, 일관성 등을 확인하고 개인정보 보호에 주의해야 합니다. 개인정보 보호 및 데이터 윤리에 대한 적절한 접근 방식과 정책을 마련해야 합니다. 따라서 사전 학습된 모델의 Tuning 과정의 중요성이 더욱 커지고 있는데요. 아래에서 LLM의 Tuning 방법인 파인 튜닝과 프롬프트 튜닝에 대해 자세히 알아보겠습니다.
파인 튜닝과 프롬프트 튜닝
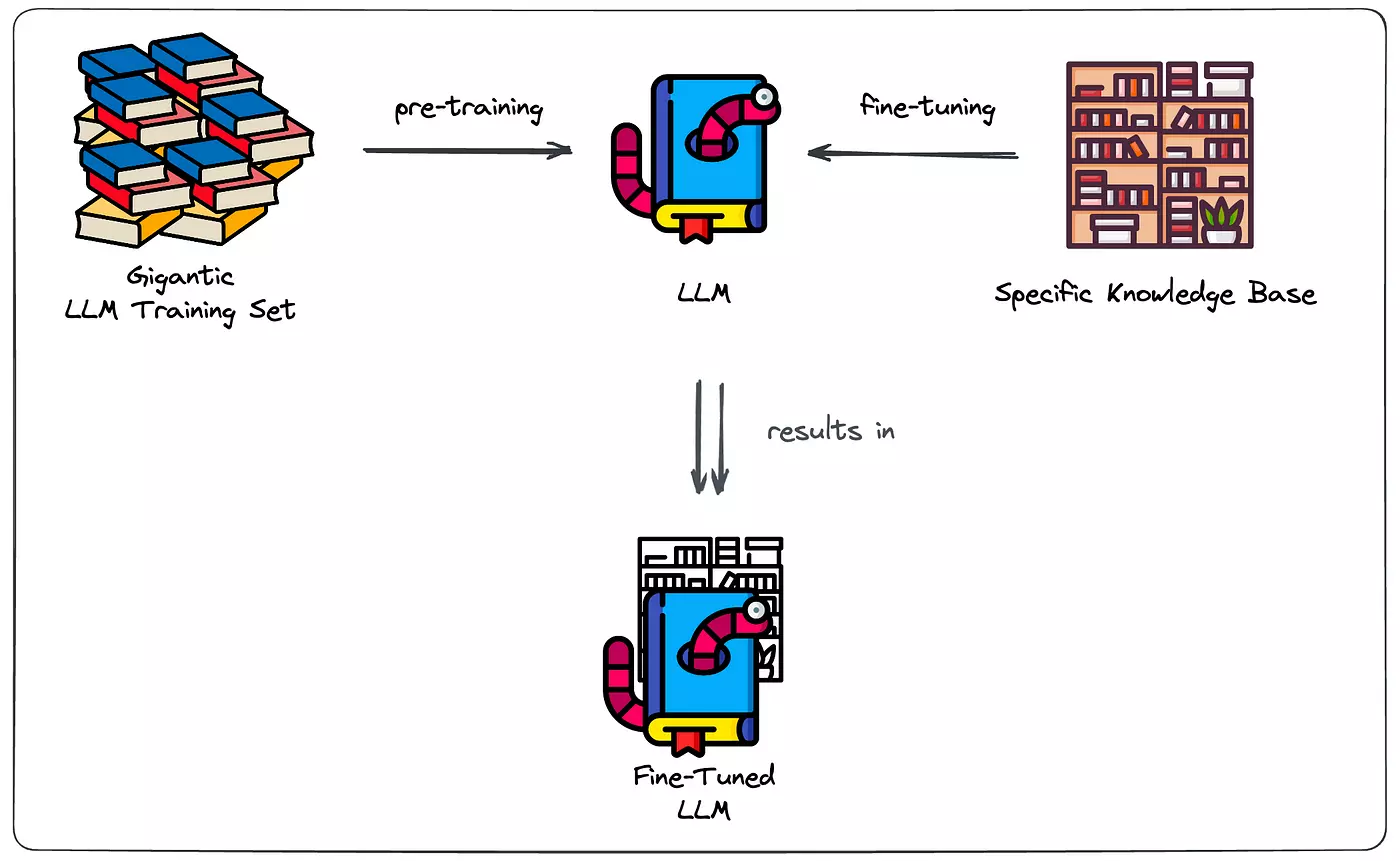
파인 튜닝(Fine-tuning)과 프롬프트 튜닝(Prompt tuning)은 모두 사전 학습된 언어 모델(Language Model)을 특정 작업에 맞게 조정하는 방법입니다. 두 방법론 모두 LLM을 조정하는 방식으로 널리 사용되고 있지만, 일부 차이점도 있습니다. 여기서 정의와 특징을 자세히 비교해 보겠습니다.
파인 튜닝 (Fine-tuning)
사전 학습된 언어 모델 전체를 대상으로 추가 작업 데이터를 이용하여 모델을 재학습시키는 방법입니다. 사전 학습한 모델을 초기 가중치로 사용하고, 특정 작업에 대한 추가 학습 데이터로 모델을 재학습
- 모델 파라미터의 일부 또는 전체를 재학습하기 때문에 작업 특정성(task-specific)이 높은 모델을 얻을 수 있습니다.
- 대량의 추가 작업 데이터가 필요할 수 있습니다.
- 일반적으로 새로운 작업에 대해 파인 튜닝하는 데 시간이 오래 걸릴 수 있습니다.
- 특정 작업에 특화된 예측 수행 가능성이 높아집니다.
프롬프트 튜닝 (Prompt tuning)
입력 텍스트에 특정 구조화된 프롬프트(prompt)를 추가하거나 수정하여 모델의 동작을 조정하는 방법입니다. 특정 작업에 맞는 최적의 프롬프트 구성을 실험하고, 모델 출력을 조작하여 원하는 결과를 얻을 수 있도록 모델을 조정합니다.
- 사전 학습된 모델의 파라미터를 고정하고, 프롬프트 구성을 조정하여 특정 작업에 적합한 결과를 얻습니다.
- 기존 데이터에 추가 작업하지 않아도 되므로 데이터 확보에 대한 부담을 줄일 수 있습니다.
- 작업 특정성이 낮고, 다양한 작업에 대해 유연한 조정이 가능합니다.
- 초기 설정과 프롬프트 구성에 대한 실험이 필요하며, 설정에 따른 성능 차이가 있을 수 있습니다.
파인 튜닝은 모델 자체를 특정 작업에 맞게 재학습하는 것이며, 프롬프트 튜닝은 입력의 구조를 조정하여 모델의 동작을 조정하는 것입니다. 두 방법은 각각 장단점과 적용 가능한 상황에 따라 선택되어야 합니다.
결론: LLM의 비즈니스 적용을 위해 모델 경량화와 학습 데이터 품질 향상이 중요한 과제
대규모 LLM은 많은 파라미터와 계산 리소스를 필요로 합니다. 모델 경량화는 모델 용량과 계산 요구를 줄여서 더 빠른 추론 속도를 실현할 수 있습니다. 또한 기기 제약이나 대역폭, 저장 공간 등의 문제로 배포와 사용이 어려운 한계를 극복할 수 있습니다. 경량화된 모델은 이러한 제약을 극복하고 다양한 플랫폼과 환경에서 쉽게 배포하고 사용할 수 있다는 장점이 있습니다.
만약 기존 LLM의 파인 튜닝과 프롬프트 튜닝을 진행하는 과정에서 적합한 결과를 획득하지 못할 경우 많은 리소스를 낭비하게 됩니다. 반면 경량화되어 보다 합리적인 비용으로 운영할 수 있게 된 LLM은 다방면으로 모델을 조정할 수 있게 되어 훨씬 더 비즈니스에서 유효한 결과를 낼 수 있습니다.
최근 오픈 소스 모델이 다양해짐에 따라, 모델 선택의 폭이 더 넓어지고 있습니다. LLM을 정확히 벤치마킹하는 방법을 찾기는 어렵지만, 그만큼 LLM 사이를 전환하는 것이 더 쉬워지고 있습니다. 오픈 LLM이나 패스트챗(FastChat)과 같은 프로젝트는 API와 인터페이스가 서로 다른 다양한 모델을 더 간편하게 연결할 수 있도록 돕습니다. 경량화된 모델을 사용하면 레이어를 이어 붙이고, 경우에 따라서는 여러 모델을 병렬로 실행하는 방법을 채택할 수도 있죠.
또한 LLM을 비즈니스에 적용하기 위해서는 고품질 학습 데이터를 기반으로 한 구체적인 튜닝 노하우가 중요해지고 있습니다. LLM은 가능한 간결하고 효율적인 방식으로 사용자의 과제 해결이나 질문에 답변하려는 시도가 필요합니다. 또한 조작된 정보 대신 정확한 콘텐츠를 사용자에게 제공하는 것이 중요합니다. LLM이 사용자의 의도를 정확하게 정의하고 측정하는 것은 물론, 정직성을 가진 모델이 되기 위해서는 LLM이 학습한 대규모 말뭉치 데이터셋에 대한 품질과 피드백 데이터가 핵심 역량으로 떠오르고 있습니다.
RLHF (Reinforcement Learning from Human Feedback)
자연어 처리에서 강화학습의 중요한 응용 분야 중 하나는 사람의 피드백을 통한 학습입니다. ‘인간 피드백을 통한 강화학습(Reinforcement Learning from Human Feedback, RLHF)'이란, 인간 주석자가 생성된 여러 응답 간의 선호도 비교라는 형태로 피드백을 제공하는 것을 의미합니다. 이 피드백은 강화학습 과정을 안내하는 보상 모델을 만드는 데 사용되며, 모델이 사람의 선호도에 더 잘 부합하는 응답을 생성하도록 장려합니다.
예를 들어 ChatGPT에 적용된 RLHF는 3단계로 요약할 수 있습니다.
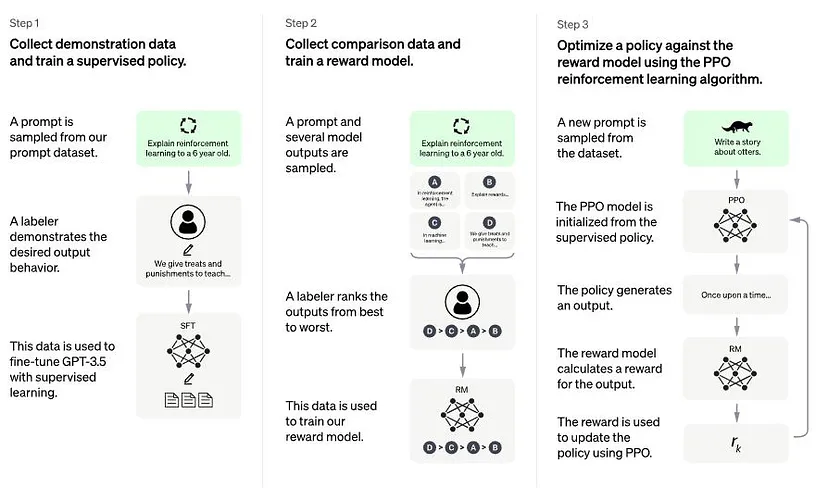
- Supervised Fine-Tuning (SFT)
인간이 의도하는 정책을 학습시키기 위해 인간 라벨러가 선별한 적은 양의 샘플 데이터셋으로 Pre-trained LM을 Fine-tuning - Reward Model (Mimic Human Preferences)
SFT 단계에서 Fine-tuning한 모델이 생성한 여러 답변 후보들 중, 무엇이 더 좋은 답변인지 인간 라벨러가 랭킹을 매겨 점수화한 데이터셋을 수집
이 데이터셋을 이용하여 새로운 보상 모델을 학습 - PPO (Proximal Policy Optimization)을 이용한 SFT 모델 강화학습
SFT 모델에 여러 사용자들의 입력을 주고, Reward Model과 함께 상호 작용하면서 강화학습을 반복
이 과정을 통해 OpenAI는 LLM의 고질적인 alignment 문제를 완화하고자 했습니다. 사용자의 명시적인 지시에 따르지 않는 현상, 존재하지 않거나 잘못된 사실을 만드는 환각 현상 등이 있었죠. 또한 인간이 모델이 한 특정 결정이나 예측에 도달한 방법을 이해하기 어렵고, 편향/독성 데이터로 학습한 언어 모델이 그에 기반한 답변을 출력하는 문제를 극복하고자 했습니다. ChatGPT에 사용된 RLHF 방식의 Fine tuning은 이 논문에서 더 자세하게 확인하실 수 있습니다.
👉 AI모델의 성능을 평가하는 f1 score 자세히 알아보기
F1 Score 란 무엇인가?
오랫동안 Model accuracy는 머신러닝 모델을 평가하고 비교하는 데 사용되는 유일한 지표였습니다. 그러나 Model accuracy는 모델이 전체 데이터 세트에서 몇 번이나 올바른 예측을 했는지를 계산하는 것으로, 평가한 횟수와 연관된 데이터가 전체 데이터 셋의 분포가 유사한 경우에만 정확하다고 말할 수 있다는 한계가 존재합니다.
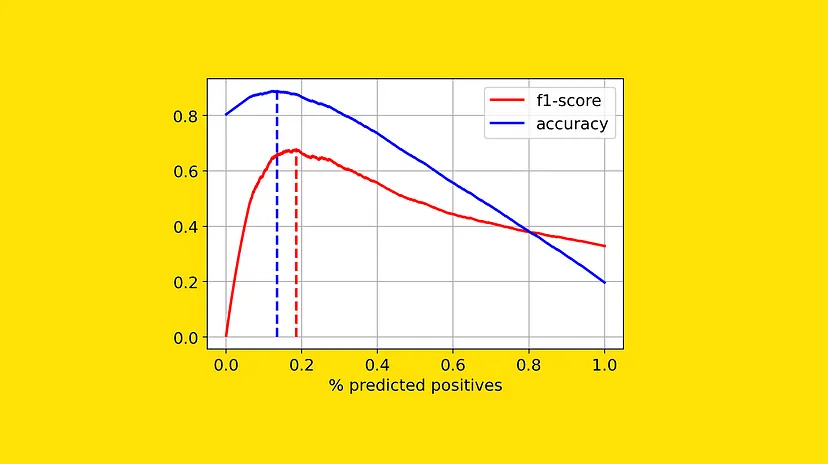
F1 score는 정밀도(Precision)와 재현율(Recall)의 조화평균으로 계산되는 성능 측정 지표입니다. 주로 이진 분류(classification) 문제에서 사용되며, 모델의 성능을 예측하고 결과를 평가하는 데 사용됩니다.
F1 score는 Accuracy처럼 전체 성능이 아닌 class 별 성능을 자세히 분석하여 AI 모델의 예측 능력을 평가하는 또 다른 머신 러닝 평가 지표입니다. F1 score는 모델의 Precision과 Recall, 두 가지 경쟁 meric을 결합한 것으로, 최근에는 널리 사용되고 있습니다.
이 글에서는 F1 Score의 구조와 원리, 사용 사례와 개선 방법에 대해서 소개하겠습니다.
F1 Score 원리와 계산법
Accuracy
F1 Score에 대해 구체적으로 알아보기 전에, 먼저 Accuracy (정확도)에 대해 알아보겠습니다. classification 모델을 예를 들어 설명하면, Accuracy(정확도)는 모델이 전체 샘플 중에서 정확히 예측한 샘플의 비율을 나타내는 평가 지표입니다. 쉽게 말해, 모델이 얼마나 정확하게 예측하는지를 나타내는 값입니다.
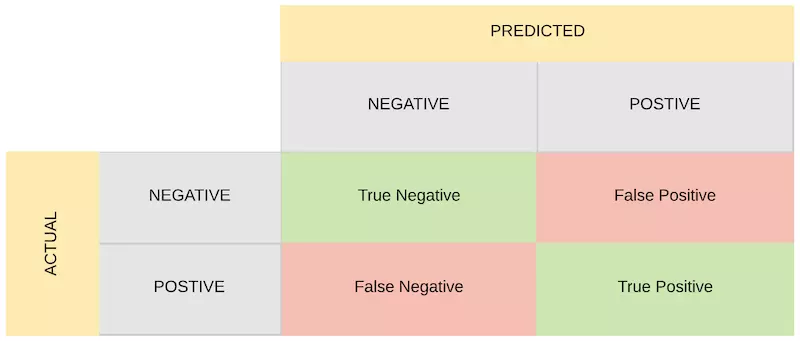
이 계산법들을 이해하기 위해서는 먼저 혼동 행렬을 살펴보고 가야합니다. 혼동 행렬이란, 데이터 세트에 대한 모델의 예측 성능을 의미합니다. “양수” 클래스와 “음수” 클래스로 구성된 이진 클래스 데이터 집합의 경우, 혼동 행렬은 네 가지 필수 구성 요소를 가집니다.
- True Positive (TP) : “양성”으로 정확하게 예측된 샘플의 수
- False Positive (FP) : “양성”으로 잘못 예측된 샘플의 수
- True Negatives (TN) : “음성”으로 올바르게 예측된 샘플의 수
- False Negatives (FN) : “음성”으로 잘못 예측된 샘플의 수
Accuracy = (예측이 맞은 샘플의 수) / (전체 샘플의 수)

이를 간단한 예제로 설명해보겠습니다. 예를 들어, 어떤 분류 모델이 100개의 샘플을 예측한 뒤, 85개의 샘플을 정확히 예측했다면, Accuracy는 85%가 됩니다. 하지만 Accuracy 계산 방식이 항상 적절한 것은 아닌데요. 그 이유는 ‘Imbalanced data’가 존재하기 때문입니다.
Imbalanced data
Imbalanced data(불균형 데이터)는 분류 문제에서 각 클래스의 샘플 수가 불균형한 상황을 의미합니다. 일반적으로는 하나의 클래스에 대한 샘플 수가 상대적으로 많고, 다른 클래스에 대한 샘플 수가 적어서 발생합니다.
예를 들어, Error detection을 위한 데이터셋은 일반적으로 정상 샘플은 많고, 비정상 샘플은 적습니다. 혹은 의료 진단에서 희귀 질병을 판단하는 경우에도 희귀 질병에 대한 샘플 수는 매우 적을 수 있습니다. 이러한 불균형 데이터는 모델의 성능을 평가하거나 학습할 때 문제를 야기할 수 있습니다. 이는 모델이 주로 많은 클래스에 집중하여 예측하고, 적은 클래스는 정확히 예측하지 못하는 결과를 초래할 수 있습니다. 적은 클래스에 대한 예측 정확도가 낮아지면 모델의 성능을 왜곡할 수 있기에 반드시 주의해야 하죠.
따라서 Accuracy, 정확도 계산 방식은 클래스가 불균형할 때는 좋은 metric이 아닙니다. 위에서 설명한 예시에 Accuracy를 평가 지표로 사용하면, 모델은 확률이 높은 클래스만 선택해서 정확도를 속이기도 합니다. 즉, 모델은 매우 나쁜 성능을 보이고 있지만 정확도는 높기 때문에 사용자 입장에서 좋은 결과처럼 보일 수 있기 때문에, Accuracy만으로 모델의 성능을 정확히 평가하기 어렵습니다. 따라서 데이터 불균형 문제를 해결하기 위해 F1 Score를 사용하게 됩니다.
F1 Score 원리
Precision (정밀도) 와 Recall (재현율) 은 불균형 데이터에서 사용하는 가장 대표적인 metric이자, 지금 알아보려는 F1 Score의 기초라고 할 수 있습니다. 이 두 가지의 조화평균을 구한 것이 F1 Score이지만, 각각 개별 metric으로 사용하기도 합니다.
Precision

Precision(정밀도)는 분류 모델의 성능을 평가하기 위한 지표 중 하나로, 모델이 양성으로 예측한 샘플 중에서 실제로 양성인 샘플의 비율을 나타냅니다.
여기서 True Positive(참 양성,TP)는 모델이 양성으로 예측한 샘플 중에서 실제로 양성인 샘플의 수를 의미합니다. 반면 False Positive(거짓 양성, FP)로, 모델이 양성으로 잘못 예측한 샘플 중에서 실제로는 음성인 샘플의 수를 의미합니다.
간단한 예제로 설명해보겠습니다. 만약 어떤 분류 모델이 100개의 양성이라고 예측한 샘플 중에서 85개가 실제로 양성이었고, 나머지 15개는 음성이었다면, TP는 85이고 FP는 15가 됩니다. 이 경우, Precision은 85 / (85 + 15) = 0.85가 됩니다. 정밀도는 "양성"으로 예측한 것 중에서 실제로 양성인 비율로, 모델이 얼마나 정확하게 양성으로 예측하는지를 나타내죠.
높은 정밀도는 모델이 거짓 양성을 최소화하고, 양성으로 예측한 것이 실제로 양성인 경우를 많이 찾아낼 수 있다는 것을 의미합니다. 따라서, 정밀도가 높을수록 모델의 성능이 좋다고 평가할 수 있습니다.
Recall
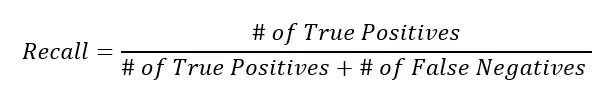
Recall(재현율)은 분류 모델의 성능을 평가하기 위한 지표 중 하나로, 실제로 양성인 샘플 중에서 모델이 양성으로 정확히 예측한 샘플의 비율을 나타냅니다.
여기서 TP는 모델이 양성으로 예측한 샘플 중에서 ‘실제로 양성인 샘플의 수’입니다. FN은 모델이 음성으로 잘못 예측한 샘플 중에서 실제로는 양성인 샘플의 수를 뜻합니다.
만약 어떤 분류 모델이 100개의 실제 양성 샘플 중에서 85개를 양성으로 정확히 예측했고, 나머지 15개를 음성으로 잘못 예측했다면, TP는 85이고 FN은 15가 됩니다. 이 경우, 재현율은 85 / (85 + 15) = 0.85가 됩니다.
재현율은 실제로 양성인 샘플 중에서 모델이 얼마나 많이 양성으로 예측하는지를 나타내므로, 모델이 양성인 샘플을 놓치는 정도를 나타냅니다. 높은 재현율은 모델이 실제로 양성인 샘플을 잘 찾아내는 것을 의미하므로, 모델의 민감도(Sensitivity)라고도 불립니다. 따라서, 재현율이 높을수록 모델의 성능이 좋다고 평가할 수 있습니다.
F1 score calculation
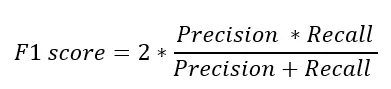
Precision은 모델이 분류한 양성 예측 중에서 실제로 양성인 비율을 나타내며, Recall은 실제 양성 중에서 모델이 양성으로 예측한 비율입니다. F1 score는 이 두 평가 지표를 모두 고려하여 모델의 예측 성능을 평가하기 때문에, 정확한 예측과 재현율의 평균을 동시에 고려할 수 있는 장점이 있습니다.
F1 Score는 이 두 가지의 지표의 조화평균을 구한 것인데요. 조화평균을 사용하는 이유는 두 metric 중 더 작은 값에 영향을 많이 받기 위함입니다. F1 Score는 0.0~1.0 사이의 값을 가지는데, Precision과 Recall 값이 모두 갖춰져야만 높은 지표를 얻을 수 있습니다. 불균형 데이터에 취약한 모습을 보였던 Accuray 보다 훨씬 더 모델 성능을 구체적으로 가늠할 수 있죠.
결론적으로, 다른 평가 지표들은 계산 방법이 간단한 대신 이진 분류 모델의 예측 성능을 전부 판별하진 못할 수 있어, 경향성이 생길 수 있습니다. 하지만, F1 score는 두 지표의 평균치를 구하는 조화 평균을 사용하여 조금 더 정확하게 모델의 예측 성능을 평가할 수 있습니다.
Precision vs. Recall
Recall(재현율)과 Precision(정밀도)은 분류 모델의 성능을 평가하는 지표로, 각각 모델의 예측 결과에 대한 다른 측면을 측정합니다. 두 metrics의 차이점은 다음과 같습니다.
정의
- Precision(정밀도): 모델이 양성으로 예측한 샘플 중에서 실제로 양성인 샘플의 비율
- Recall(재현율): 실제로 양성인 샘플 중에서 모델이 양성으로 정확히 예측한 샘플의 비율
관점
- 재현율은 실제 양성 중에 얼마나 많이 찾아내는지에 초점
- 정밀도는 모델이 양성으로 예측한 샘플 중에 실제로 양성인 비율에 초점
활용
- 재현율은 모델이 실제로 양성인 샘플을 얼마나 잘 찾아내는지를 나타내므로, 거짓 음성(실제 양성인데 음성으로 예측한 경우)를 최소화하는 데 중점
- 정밀도는 모델이 올바르게 양성이라고 분류한 샘플 중에 실제로 양성인 샘플이 얼마나 많은지를 나타내므로, 거짓 양성(실제로는 음성인데 양성으로 예측한 경우)를 최소화하는 데 중점
Precision-Recall Trade off
이상적으로 좋은 모델은 Positive한 것을 제대로 분류하고, Positive한 것만 제대로 분류하면 됩니다. 하지만 현실적으로 두 가지 모두 높이는 방법이 어렵기 때문에, 어떤 것에 초점을 맞출 지를 고민할 필요가 있습니다.
두 가지 metric이 각각 중요하게 생각하는 것이 다르기 때문에, 활용 분야에서도 서로 다른 양상을 띕니다. 예를 들어, 암 진단 시에 실제 암 환자를 놓치지 않는 것이 중요한 경우 Recall에 중점을 두지만, 스팸 메일 분류 시 정상 메일을 스팸으로 잘못 분류하는 비율을 낮추기 위해 Precision에 초점을 맞추기도 하죠.
요약하면, 재현율은 실제 양성을 놓치지 않도록 하는데 초점을 둡니다. 반면 정밀도는 모델이 올바르게 양성으로 분류하는 비율에 초점을 둡니다. 둘은 분류 모델의 평가에서 상충하는 관계를 가지므로, 평가하고자 하는 문제나 목표에 따라 적절한 방법을 선택해야 합니다.
R-squared 란 무엇인가?
R-squared(결정 계수, coefficient of determination)은 회귀 모델에서 사용되는 평가 지표입니다. 모델이 주어진 데이터를 얼마나 잘 설명하는지를 측정하기 위해 사용됩니다. R-squared는 종속 변수의 총 변동량 중 모델이 설명하는 변동량의 비율로, 0부터 1까지의 값을 가집니다. R-squared 값이 1에 가까울수록 모델이 데이터를 잘 설명한다는 것을 의미합니다.
R-squared = 1 - (잔차 제곱합 / 종속 변수의 총 제곱합)
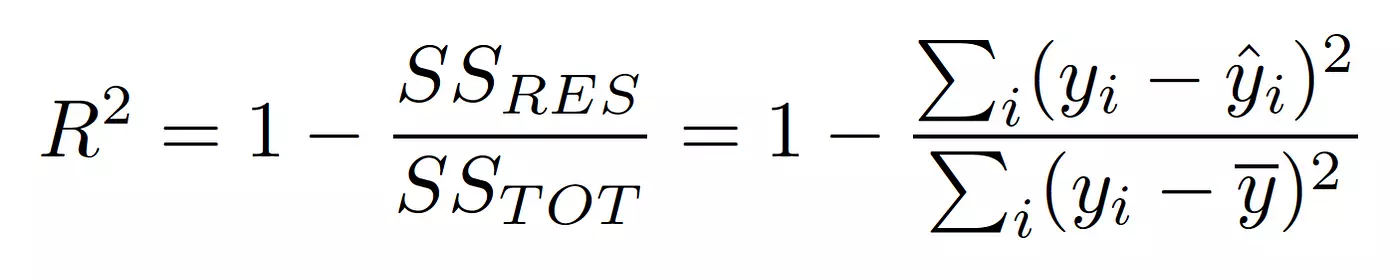
잔차 제곱합은 예측값과 실제 값 사이의 차이(잔차)를 제곱하여 모두 합한 값입니다. 종속 변수의 총 제곱합은 종속 변수 값들을 평균으로부터 얼마나 떨어진 정도로 제곱하여 모두 합한 값입니다. R-squared 값은 일반적으로 0부터 1 사이의 값을 가지지만, 음수 값이 나올 수도 있습니다.
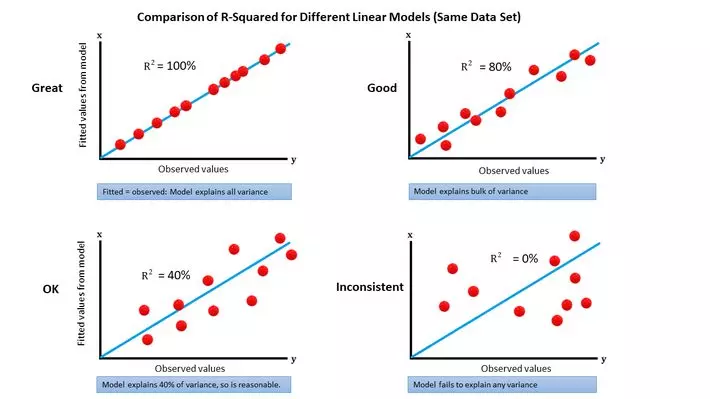
이는 모델이 데이터를 잘 설명하지 못하는 경우를 의미합니다. R-squared는 모델의 적합도를 판단하는 데 사용되며, 높은 R-squared 값은 모델이 데이터를 잘 설명한다는 의미로 해석될 수 있죠. 하지만 R-squared는 독립 변수의 수와 관련이 없어서, 모델의 복잡성과 관련된 정보를 제공하지는 않습니다. 따라서, 모델 비교를 할 때에는 Accuracy와 마찬가지로 다른 평가 지표나 정보도 고려하는 것이 좋습니다.
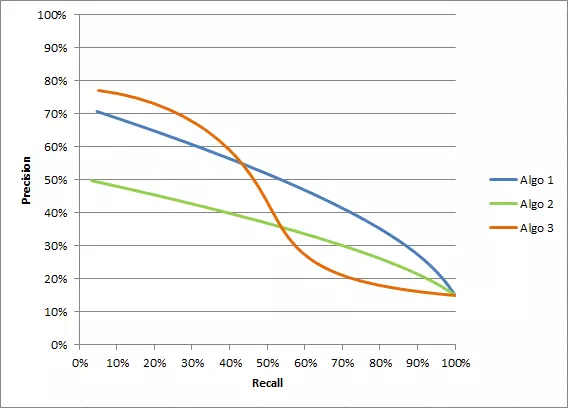
F1 Score 사용 사례
F1 score는 F1 score는 정밀도(Precision)와 재현율(Recall)의 조화 평균값으로, 이진 분류 모델의 성능을 평가하는 지표 중 하나입니다. F1 score는 정밀도와 재현율의 균형을 조정하여 정확한 예측과 상승률의 평균을 동시에 고려할 수 있는 장점이 있습니다.
- 클래스 불균형 데이터:
클래스가 불균형하게 분포된 경우, 즉 한 클래스의 샘플 수가 다른 클래스에 비해 현저히 많은 경우, Accuracy(정확도)만으로 모델을 평가하는 것은 적절하지 않을 수 있습니다. 이런 경우 F1 score를 사용하여 모델의 성능을 정확하게 측정할 수 있습니다. - 암 진단 등 실제 양성의 중요성:
실제로 양성인 샘플을 놓치면 큰 문제가 발생하는 경우, 예를 들어 암 진단 등에서 중요한 참 양성을 잘 판단하는 능력을 가진 모델이 필요한 경우가 있습니다. 이때 F1 score는 모델의 재현율과 정밀도 둘 모두를 고려하여 성능을 평가할 수 있는 지표입니다. - 텍스트 분류나 정보 검색:
NTT 인식이나 단어 분할의 평가 등 NLP 프로세스에서도 사용됩니다. 텍스트 분류 문제나 정보 검색에서는 긍정과 부정, 또는 관련 있는 문서와 관련 없는 문서 등과 같이 두 개의 클래스로 분류하는 경우가 많습니다. 이런 문제에서도 F1 score를 사용하여 정밀도와 재현율을 고려한 성능 평가를 할 수 있습니다.
F1 Score 개선하는 방법

F1 Score는 0~1까지 점수를 매길 수 있습니다. F1 Score가 낮게 나온다면 정밀도와 회수율이 모두 낮다는 뜻으로 해석할 수 있습니다. F1 Score를 구성하는 정밀도와 재현율이 각각 낮은 경우가 있습니다. 정밀도 점수가 낮으면 머신러닝 모델이 잘못된 주석을 생성하고 있다는 뜻이며, 재현율이 낮다는 것은 머신러닝 모델이 생성했어야 하는 주석을 생성하지 못했음을 나타냅니다. 이는 유형 시스템의 복잡성이나 교육 문서의 적절성, 인간 라벨러의 기술 및 기타 요인 등 다양한 요인에 따라 발생할 수 있습니다. 아래는 F1 Score를 개선하는 일반적인 방법입니다.
- 학습 데이터 조정:
학습 데이터 자체를 더 추가하거나 데이터에 주석을 더 추가하는 것입니다. 그 외에도 데이터 가공 품질을 개선하는 방식으로, F1 Score를 개선할 수 있습니다. - 샘플링(Balancing Sampling):
클래스 불균형 데이터에서는 일반적으로 예측하고자 하는 클래스보다 다른 클래스의 샘플 수가 많을 수 있습니다. 이러한 경우, 데이터를 균형있게 샘플링하여 모델을 학습시키는 것이 중요합니다. Undersampling(언더샘플링)은 다수 클래스의 샘플 수를 일부 감소시키는 방법이고, Oversampling(오버샘플링)은 소수 클래스의 샘플 수를 증가시키는 방법입니다. - 가중치 부여(Class Weights):
소수 클래스의 중요성을 강조하기 위해, 소수 클래스에 더 큰 가중치를 부여하여 모델의 학습에 반영할 수 있습니다. 이렇게 하면 모델이 소수 클래스를 더 잘 학습할 수 있으며, 예측 성능을 향상시킬 수 있습니다. - 예측 임계값 조정(Threshold Adjustment):
모델의 예측 임계값을 조정하여 정밀도와 재현율 사이의 균형을 조정할 수 있습니다. 예를 들어, 임계값을 낮추면 분류 결과가 더 많이 양성으로 분류되어 재현율이 증가하고, 정밀도가 감소할 수 있습니다. 임계값을 높이면 정밀도가 증가하고, 재현율이 감소할 수 있습니다.
일반적으로 혼동되는 유형이나 자주 발생하는 유형을 낮은 확률로 식별하게끔 만들면 소수 클래스에 대한 인식 능력이 올라갈 것입니다. 이외에도 특정 유형의 F1 Score가 낮은 경우, 해당 유형에 적용되는 주석 지침의 명확성을 검토해야 합니다. 교육 데이터에서 자주 발생하지 않는 유형에 대해 사전을 추가하는 등 학습 데이터를 자세히 검토하고 모니터링하는 방법으로 F1 Score를 높일 수 있습니다.
F1 Score 한계와 대안
한계
이렇듯 F1 Score는 이진 분류 모델을 평가하기 위해 범용적으로 사용하는 metric이지만, 완벽한 것은 아닙니다.
- F1 Score는 오차 분포에 대한 정보를 제공하지 않습니다.
F1 Score는 Precision과 Recall을 가지고 모델의 성능을 요약하는 단일값을 제공합니다. 그러나 특정 응용프로그램에서 중요할 수 있는 오류 분포에 대한 정보는 제공하지 않습니다. - F1 Score는 Precision과 Recall의 동등한 중요성을 가정합니다.
Precision과 Recall 모두에 동등한 가중치를 부여하며, 동일한 중요성을 가지고 있다고 가정합니다. 그러나 두 지표는 일부 애플리케이션에서 중요성이 다를 수 있기 때문에, 조화평균을 구하는 F1 Score보다 다른 지표가 더 유용할 수 있습니다. - F1 Score는 다중 클래스 분류에 최적화되어 있지 않습니다.
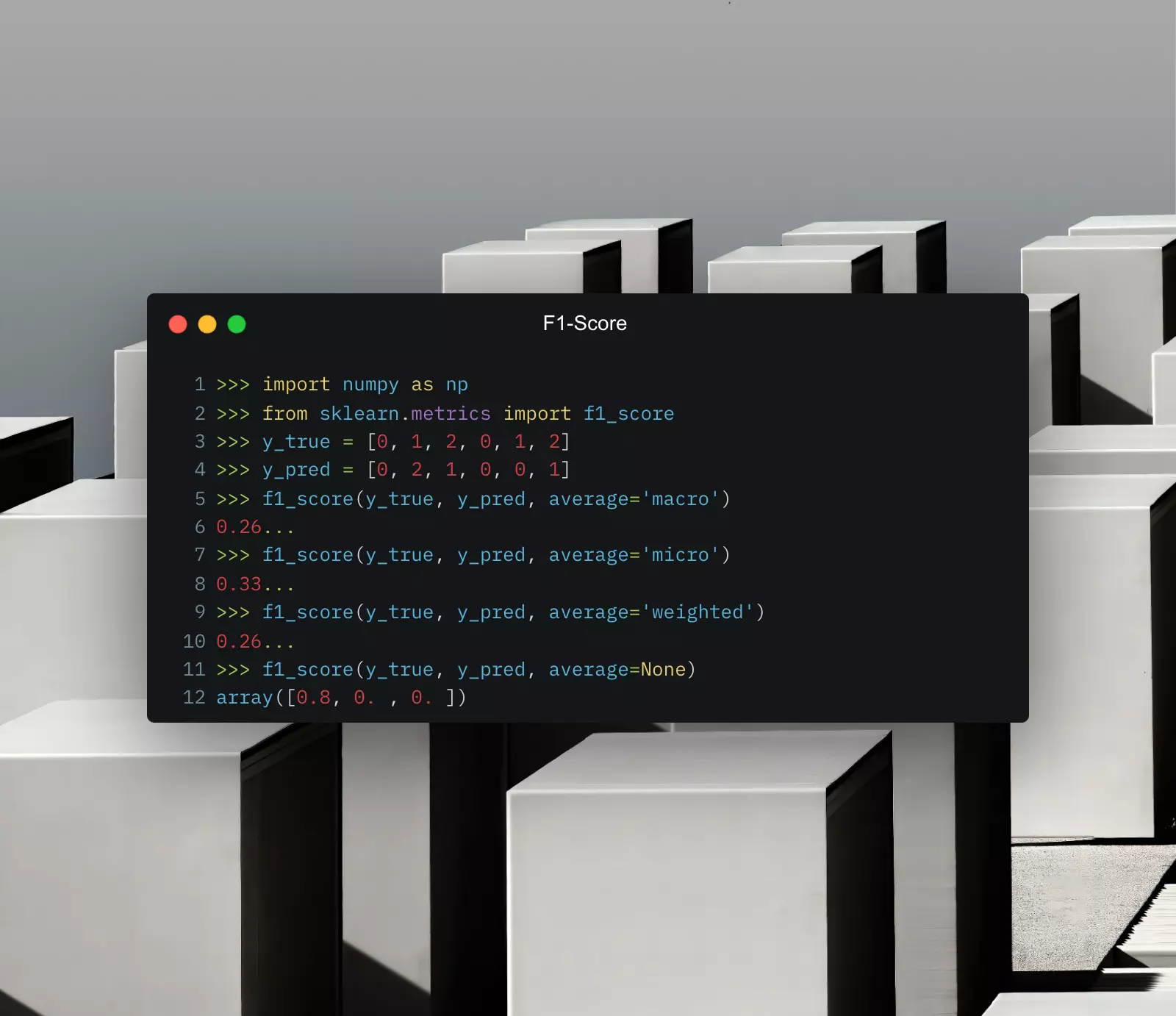
이 지표는 이진 분류 모델을 위해 설계되었기 때문에, 다중 클래스 분류 문제에는 적용되지 않을 수 있습니다. 이 경우에는 Precision이나 Micro/Macro F1 Score와 같은 지표가 더 적절할 수 있죠. - F1 Score는 데이터의 특정 패턴에 민감하지 않을 수 있습니다.
F1 Score는 데이터의 특정 패턴이나 특성을 고려하지 않는 범용적인 metric입니다. 경우에 따라, 문제의 특정 속성을 캡쳐하고자 한다면 보다 전문화된 metric이 필요할 수 있습니다.
그렇다면 대안은?
결론적으로, F1 score는 클래스 불균형 문제에서 유용하고 재현율과 정밀도의 균형을 평가하는 좋은 평가 지표입니다. 하지만 위의 한계들을 고려하여 모델의 성능 평가를 보다 포괄적으로 진행하는 것이 좋습니다. 다른 평가 지표와 함께 사용하거나, 문제의 특성에 맞게 적절한 지표를 선택하는 것이 중요합니다. 아래는 F1 Score를 보완할 수 있는 대안을 소개합니다.
ROC Curves, AUC
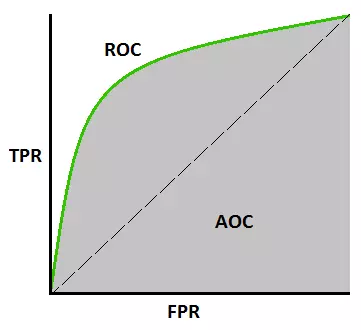
ROC(Receiver Operating Characteristic) 곡선 및 AUC(Area Under the Curve)는 이진 분류 모델의 성능을 평가하는 데 사용되는 평가 지표입니다. 다양한 분류 임계값 범위에서 양의 인스턴스와 음의 인스턴스를 구별하는 모델의 능력을 측정할 수 있습니다. 특히 F1 Score와 마찬가지로 imbalanced data에 유용하다는 특징이 있습니다. 자세한 내용은 아래에서 확인하실 수 있습니다.
ROC curves
- 이진 분류 모델에서 임계값을 변화시켰을 때, 모델의 Precision(True positive Rate)과 1에서 모델의 특이도(False Positive Rate)를 각각 x축과 y축으로 그린 곡선
- 모델이 양성과 음성을 얼마나 잘 분류하는지 시각화할 수 있음
- ROC Curves 상에서 왼쪽 위 모서리에 가까운 지점에 위치할 수록 좋은 성능을 나타냄
AUC
- ROC 곡선 아래의 면적으로, ROC 곡선의 모든 지점에서의 재현율과 특이도의 조합에 대한 면적을 의미
- AUC 값은 0부터 1까지의 범위를 가지며, 최적의 모델에서는 AUC가 1에 가까운 값이 됨
- AUC는 임의로 선택된 양성 샘플과 음성 샘플을 비교했을 때, 양성 샘플이 더 높은 확률로 예측되는 경향을 제공
- AUC 값으로 모델을 비교하면, AUC가 더 큰 모델일수록 더 좋은 성능을 가지는 경향
F-Beta Score
F-beta score도 F1 Score와 마찬가지로 이진 분류 모델의 성능을 평가하는 지표로, Precision과 Recall의 조화 평균을 계산해서 최종 점수를 매기는 방식입니다. 다만 계산 방식에서 F1 Score와는 조금 다른 것을 확인할 수 있습니다.
F-beta score = (1 + beta^2) * (Precision * Recall) / ((beta^2 * Precision) + Recall)
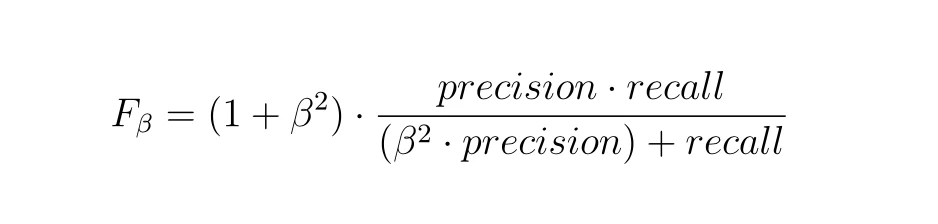
여기서 beta는 모델이 재현율에 대해 정밀도를 얼마나 중요하게 간주하는지를 제어하는 매개 변수입니다. beta 값이 클수록 재현율에 더 큰 가중치를 두게 되고, 작을수록 정밀도에 더 큰 가중치를 두게 됩니다. 일반적으로 beta 값은 1, 0.5, 2와 같이 정해지며, beta 값이 1인 경우에는 F1 score와 동일합니다.
F-beta score는 정밀도와 재현율 사이의 균형을 조정하여 모델의 예측 성능을 평가하는 데 사용됩니다. 예를 들어, 실제 양성을 제대로 찾아내는 재현율이 더 중요한 경우에는 beta 값을 2로 설정하여 재현율에 더 큰 가중치를 둘 수 있습니다. 반대로, 정밀도가 더 중요한 경우에는 beta 값을 0.5로 설정하여 정밀도에 더 큰 가중치를 둘 수 있습니다.
따라서 F-beta score를 사용하면 모델의 예측 성능을 정밀도와 재현율의 균형을 조정하여 관리할 수 있습니다. 모델의 특성과 평가하고자 하는 문제에 따라 적절한 beta 값을 선택하여 F-beta score를 계산할 수 있는 것이죠.
Geometric Mean
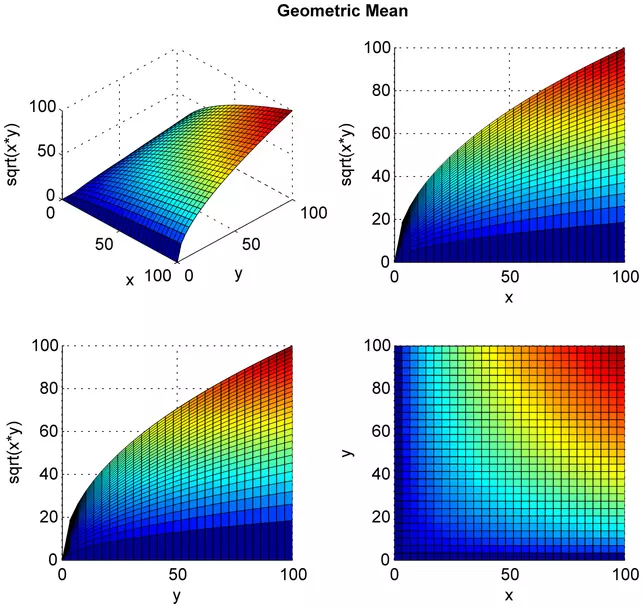
G-mean(Geometric Mean)은 이진 분류 모델의 성능을 평가하기 위한 평가 지표 중 하나입니다. 재현율(Recall)과 특이도(Specificity)의 기하 평균으로 계산되며, 클래스 불균형 문제에서 모델의 성능을 정확하게 평가할 수 있도록 도와줍니다.
G-mean = √(Recall * Specificity)
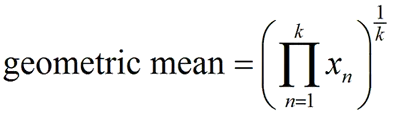
Recall은 실제 양성 중에서 모델이 양성으로 정확히 예측한 비율이며, 특이도는 실제 음성 중에서 모델이 음성으로 정확히 예측한 비율입니다. G-mean은 이 두 지표를 기하 평균한 값으로, 모델의 양성 및 음성 클래스에 대한 평균 예측 성능을 나타냅니다.
G-mean은 클래스 불균형 데이터에서 모델의 성능을 평가하는 데 유용합니다. 이는 불균형 데이터에서 일반적인 평가 지표인 정확도(Accuracy)가 왜곡될 수 있는 경우를 보완하고, 모델이 양성 및 음성 클래스를 모두 골고루 잘 예측하는 성능을 측정할 수 있도록 도와줍니다.
따라서 G-mean은 모델의 예측 능력과 신뢰성을 동시에 평가할 수 있는 지표로서 활용됩니다. 값이 1에 가까울수록 모델의 성능이 높다고 해석할 수 있습니다. 그러나 G-mean도 특정 문제와 데이터에 따라 한계가 있을 수 있으므로, 다른 평가 지표와 함께 고려하고 문제의 특성에 맞는 지표를 선택하여 사용하는 것이 중요합니다.
결론: 학습 데이터 정확도를 통해 F1 Score를 개선하고, 모델 완성도를 확보할 수 있다.
F1 Score는 Precision과 Recall 모두에 동일한 가중치를 할당하기 때문에, 분류 모델 평가 지표에서 중요한 차이점이 가려질 수 있습니다. F1 Score를 사용할 때는 구체적인 문제와 맥락을 고려하면서, 과제의 목표와 요구사항을 탐색하고 적절한 측정 기준을 선택할 필요가 있습니다. 즉, 구체적인 상황과 맥락을 고려했을 때 다른 평가지표가 F1 Score보다 더 효과적일 수 있다는 것이죠. 모델의 성능을 종합적으로 평가하기 위해서는 다른 메트릭 및 요인을 함께 평가할 필요가 있습니다.
상황에 따라 다르지만 F1 Score가 0.7 이상일 때 좋은 모델이라고 간주하고 있습니다. 높은 점수를 가진다고 해서 만능인 모델은 아니지만, F1 Score가 높은 모델은 분명 종합적으로 모델 성능이 좋다고 볼 수 있죠. 높은 F1 Score를 확보하기 위해서는 사전에 학습한 데이터의 품질이 중요하며, 성능 개선을 위해 훈련 데이터를 구체적으로 검토하고 모니터링하는 과정이 중요합니다. 데이터헌트가 학습 데이터 정확도 99% 달성까지 많은 연구와 노력을 거듭한 이유도, 최종적인 모델의 완성도를 높이기 위함인 것이죠.
강화학습의 한계
강화학습은 지도 학습보다는 적은 데이터로, 비지도 학습보다는 보다 복잡한 문제를 해결할 수 있다는 점에서 미래가 기대되는 머신러닝 방법론입니다. 그러나 그 가운데에서도 몇 가지 한계를 가지고 있습니다.
- 방대한 데이터 요구
강화학습은 데이터에 의존하는 학습 방식이기 때문에 데이터의 품질과 양이 매우 중요합니다. 그러나 환경(environment)과 상호작용 할 수 있는 데이터를 구축하는 것은 복잡하며 비용과 시간이 많이 소요될 수 있습니다. - 복잡한 보상 함수 정의
보상 함수를 적절하게 정의하는 과정에서 예기치 않은 동작이나 잘못된 보상 신호로 인해 원치 않는 결과가 발생할 수 있습니다. 또한, 강화학습 모델은 보상에 초점을 맞추어 최적의 행동을 선택하기 때문에, 장기적인 목표를 고려하지 못하고 즉각적인 보상에 치우칠 수 있는 단점이 있습니다. - 환경 변화에 따른 적응력
강화학습된 모델은 처음 보는 상황에서도 적절한 행동을 취할 수 있어야 하지만, 그 과정에서 적절한 탐색을 통해 새로운 경험을 얻어야 합니다. Agent는 Environment와 현재 state에 따라 작업을 수행하는데, 환경이 계속해서 변화한다면 좋은 결정을 내리는 것이 어려울 수 있습니다. - 비용/리소스
강화학습은 학습 알고리즘의 계산적인 복잡성과 연산량이 매우 방대합니다. 학습 모델의 크기와 깊이, 그리고 필요한 컴퓨팅 자원의 양이 많아진다면 학습에 필요한 시간과 비용도 증가하게 될 수 있습니다.
결론: 강화학습 방법론의 핵심은 가장 우수한 결과를 찾는 과정이므로, 결론에 도달하기까지의 데이터가 중요
RLHF(Reinforcement Learning from Human Feedback)의 한계에서 볼 수 있듯이, 데이터셋의 품질 편차는 강화학습이 최적의 학습 결과를 얻는 것을 지연시키는 장애물이 될 수 있습니다. 강화학습의 정확성을 향상시키기 위해서는 일관되고 높은 품질의 데이터셋이 필요합니다. 학습에 사용되는 데이터셋은 다양한 환경과 상황을 반영해야 하며, 데이터의 품질을 향상시키기 위한 지속적인 노력이 필요합니다.
또한, 데이터의 일관성 외에도 연구와 개발을 통해 알고리즘과 모델의 개선에 대한 노력이 계속되어야 합니다. 강화학습은 여전히 많은 도전과제를 안고 있으며, 문제 해결을 위한 새로운 방법과 접근법이 필요합니다. 따라서, 이러한 연구와 혁신적인 개발 노력을 통해 강화학습의 전문성과 활용 가능성을 한층 높일 수 있을 것입니다.
강화학습의 핵심인 더 많은 보상을 창출하기 위한 정책 개발과 데이터 품질의 일관성은 지속적인 연구와 다각도로 발전해야 할 주요 과제입니다. 데이터헌트는 이러한 도전에 대한 적극적인 대응과 지속적인 혁신으로 머신 러닝의 발전과 인공지능의 활용을 위한 중요한 동력이 되고자 노력하고 있습니다.
딥 러닝 (Deep learning) 활용 방안
최근 몇 년간 딥 러닝은 다양한 분야에서 많은 문제를 해결하는 데에 사용되었습니다. 이 글에서는 많은 분야에서 사용되는 딥 러닝의 예제 중 일부를 소개해보겠습니다.
Computer vision, Pattern Recognition
딥 페이크 (Deep Fake)
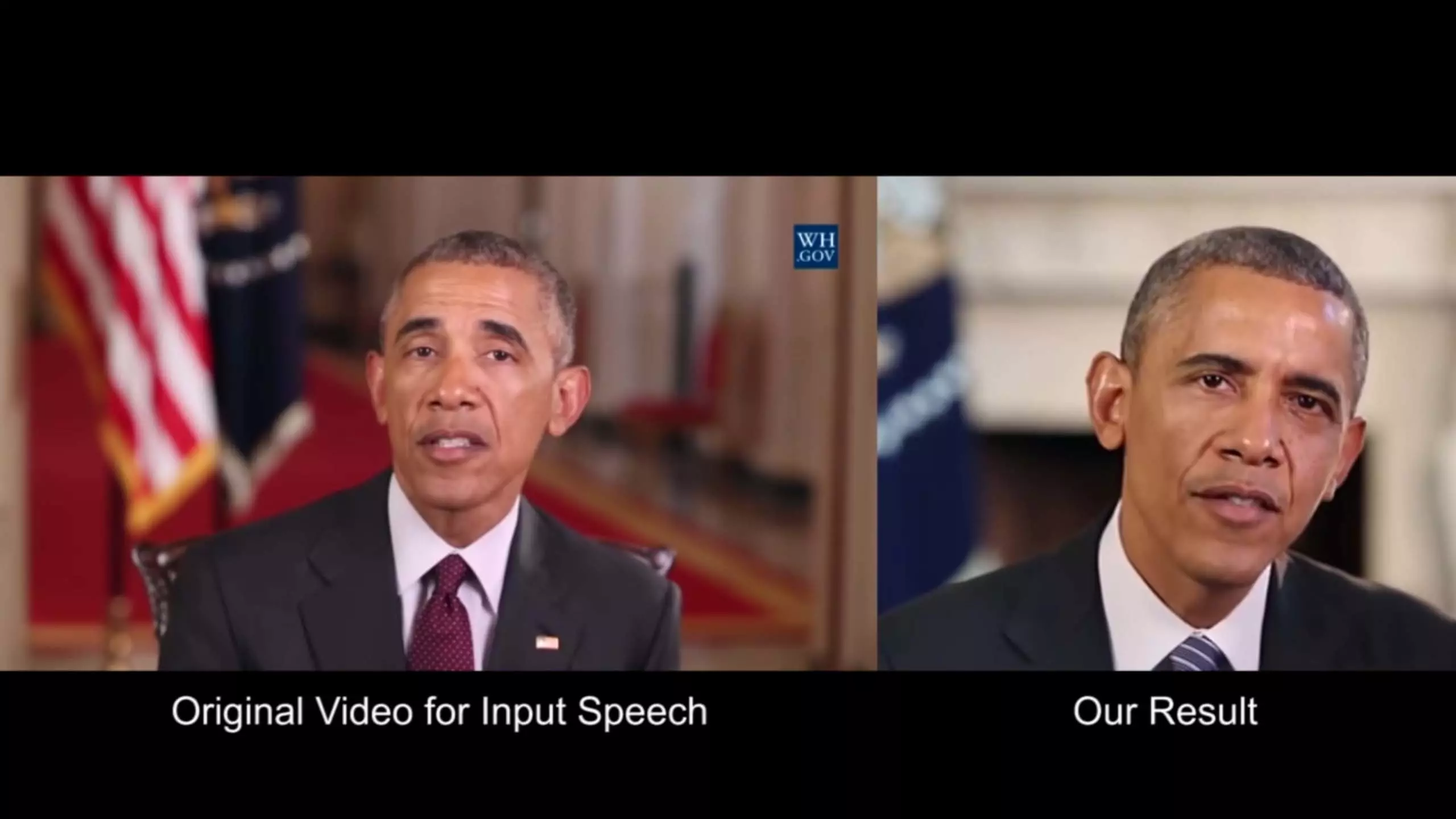
워싱턴의 한 대학에서 오디오를 이용해 비디오의 입술 움직임을 합성한 결과물을 소개했습니다. 자세한 결과물은 비디오를 통해 확인할 수 있고, 영상에 대한 논문은 여기에서 확인하실 수 있습니다.
이미지/영상 복원

Let there be color! 는 자동으로 흑백사진을 색이 있는 사진으로 바꿔주는 웹사이트입니다. 딥 러닝 네트워크는 사진에서 일어나는 실제 패턴을 학습하는 방법으로 사진을 복원합니다. 사진에서 객체를 식별하고 실제 세계의 특징을 학습한 뒤, 인간의 개입 없이 과거 경험을 바탕으로 스스로 학습하는 것입니다. 이 때 주로 사용되는 모델은 Places2 모델입니다. 이 모델은 대규모 이미지 데이터 세트에 대해 학습되었으며, 사실적인 방식으로 이미지의 색상을 지정하는 방법을 학습했습니다.

이외에도 Google Brain 연구자들이 딥 러닝 네트워크를 이용해 얼굴 이미지를 저해상도로 변환시킨 후, 각 이미지가 무엇과 유사한 형태를 갖고있는지 예측하기도 했습니다. 이를 Pixel Recursive Resolution이라고 하는데, 사진의 해상도를 극명하게 강화시키는 것을 뜻합니다.
실시간 행동 분석
딥 러닝 네트워크는 사진 속 상황을 인지하고 설명할 뿐만 아니라, 사람들의 자세도 예상할 수 있습니다. DeepGlint 라는 곳에서 공개한 영상에 의하면, 딥 러닝을 이용하면 차량이나 사람, 다른 물체들의 상태를 인지할 수 있다고 하죠. 위 사진에서 볼 수 있듯이 은행에서 대기하는 사람들의 행동을 예측할 수도 있습니다.
멸종위기 동물 분류하기

위에서 설명했듯이 CNN (Convolutional Neural Networks)는 이미지 분류에 뛰어난 성능을 보이는 딥 러닝 신경망입니다. 이를 이용해 생물학이나 천문학 등의 다양한 분야에서 활용되고 있습니다. 예를 들어, 바다 속에서 촬영된 고래의 사진을 보고 고래의 종류를 분류함으로써 멸종 위기에 처한 동물들을 보호하고 더 많은 관심을 줄 수 있습니다.
Robot, autonomous driving
자율주행 자동차
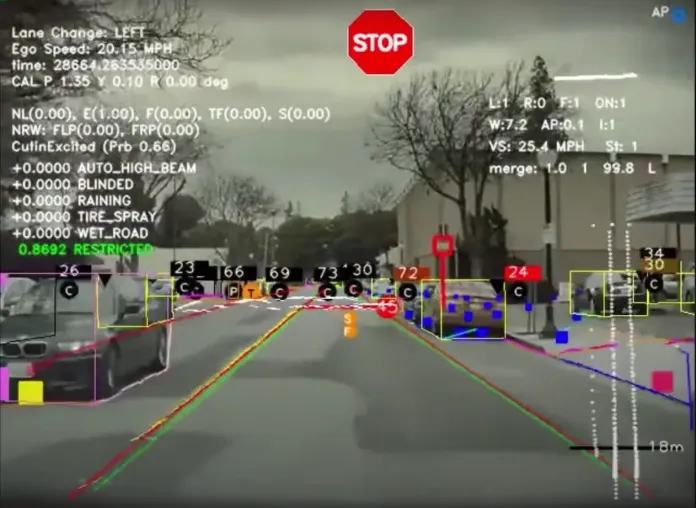
테슬라의 차량에는 방대한 양의 데이터를 수집하는 수많은 센서와 카메라, 레이더가 장착되어 있습니다. 딥 러닝 모델은 이 데이터를 사용하여 실제 주행 시나리오를 더 잘 이해하고 정확한 주행 결정을 내릴 수 있도록 훈련합니다.
또한 테슬라는 CNN (컨볼루션 신경망) 과 같은 딥 러닝 알고리즘을 사용하여 원시 센서 데이터를 처리하고 물체나 차선, 교통 표지판 및 기타 관련 도로 요소를 식별하고 있습니다. 이를 통해 시스템이 차량의 환경을 정확하게 이해하고 적절한 주행 결정을 내릴 수 있죠. 테슬라가 자율주행에 딥 러닝을 활용하는 방법에 대한 자세한 내용은 이 글과 이 글을 참고하시면 됩니다.
로보틱스
딥 러닝은 로보틱스에서 다양한 측면에서 활용되어 로봇의 성능을 향상시키고, 더 복잡한 작업을 수행할 수 있도록 하고 있습니다.
- CNN과 같은 딥 러닝 알고리즘이나 최근 많이 사용하는 Vision Transformer를 사용하면 이미지나 비디오, LiDAR 등의 센서 데이터를 처리하면서 객체를 탐지하고 추적할 수 있습니다.
- 딥 러닝 모델을 사용하면 로봇 팔이나 그리퍼 등을 제어하고 정확한 움직임을 계획할 수 있습니다. 모델은 서로 다른 상황에서 물체를 잡거나 놓는 데 필요한 힘과 각도를 학습하여 더 정확하게 작업을 수행할 수 있습니다.
- 로봇이 알려지지 않은 환경에서 경로 계획을 수립하고 장애물을 회피할 수 있습니다. 특히 순환 신경망 (RNN) 과 강화 학습 (Reinforcement Learning)은 센서 데이터를 기반으로 안전한 경로를 찾는 데에 도움이 됩니다.
- 로봇은 예측과 제어에서 강화 학습 알고리즘을 사용하여 행동을 최적화하고 보상 시스템을 통해 배울 수 있습니다. 이러한 방식을 활용하면 로봇은 상황에 맞게 적응하고 어려운 작업을 수행할 수 있는 능력을 향상시킬 수 있습니다.
- 딥 러닝 모델은 로봇의 성능을 시험하기 위한 가상 환경에서 훈련할 수 있습니다. 이를 통해 개발자는 모델을 안전하게 실험하고 개선할 수 있습니다.
LLM
대규모 언어 모델 (LLM) 에서 딥 러닝은 방대한 텍스트 데이터 세트를 가지고 모델을 훈련하는 데 사용됩니다. 이 데이터 세트는 책과 기사부터 소셜 미디어 게시물과 채팅 대화에 이르기까지 무엇이든 될 수 있습니다. 모델은 텍스트의 패턴을 식별하고 데이터 세트의 텍스트와 유사한 텍스트를 생성하는 방법을 학습합니다.
앞에서 설명했듯이, 대규모 언어 모델은 그 자체만으로 방대한 양의 데이터를 필요로 하기 때문에 계산 시간 및 비용이 많이 듭니다. 따라서 사전 훈련된 언어 모델을 파인 튜닝하고 전이 학습을 수행하는 것이 표준화된 방식이 되었습니다. 따라서 딥 러닝이 적용된 LLM을 이해하기 위해서는 파인 튜닝의 방법과 개요에 대해서 알아야 할 필요가 있습니다.
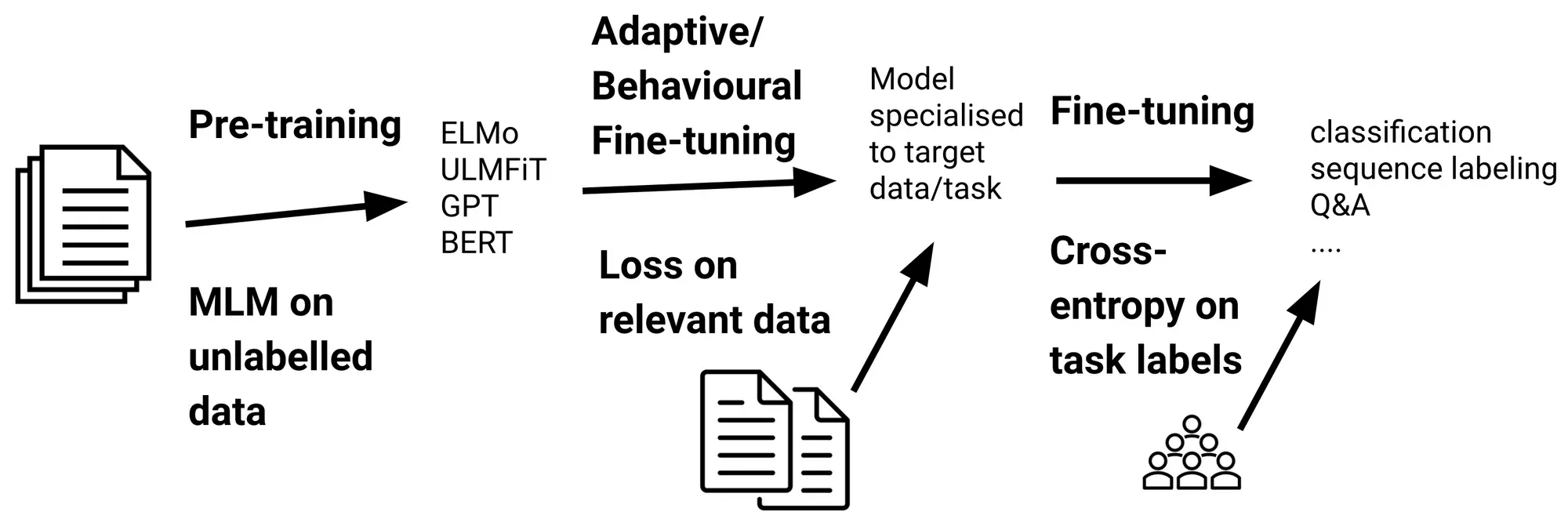
Full fine-tuning
- 가장 일반적인 유형의 파인 튜닝
- 언어 모델의 모든 매개 변수가 학습 중에 업데이트
- 계산 비용이 많이 들 수 있지만 최상의 결과를 획득
Partial fine-tuning
- 언어 모델 매개변수의 일부만 학습 중에 업데이트
- 더 빠르고 효율적으로 파인 튜닝할 수 있지만 Full fine-tuning 보다는 성능이 떨어짐
Linear fine-tuning
- 언어 모델의 매개 변수가 학습 중에 선형적으로 업데이트
- 매개변수가 작은 단위로 업데이트하여 모델이 과도하게 적합해지는 것을 방지
Adaptive fine-tuning
- 언어 모델의 학습 속도가 훈련 중에 조정
- 모델이 잘 학습할 때는 학습 속도가 빨라지고 그렇지 않을 때는 학습 속도가 저하
- 파인 튜닝 프로세스 효율성 개선에 특화
Task-specific fine-tuning
- 텍스트 분류 또는 질문 답변과 같은 특정 작업에 맞게 언어 모델을 파인 튜닝
- 작업과 관련된 레이블이 지정된 데이터 세트를 사용
파인 튜닝 방법론의 선택은 언어 모델의 크기와 복잡성, 사용 가능한 데이터의 양, 원하는 성능 등 여러가지 요인에 따라 달라질 수 있습니다. 다만 사전 훈련된 모델을 파인 튜닝할 때에 실질적인 문제는 소규모 데이터 세트에서 서로 다른 실행 간에 성능이 크게 달라질 수 있다는 것입니다. 최근 많은 방법들이 파인 튜닝의 불안정성을 완화하고자 하고 있습니다.
최근에 가장 주목 받는 것은 Generative AI (생성 모델) 의 파인 튜닝을 통해 일관성과 연관성을 갖춘 출력을 생성하는 모델을 만들고자 하는 것입니다. 방대한 양의 데이터에 대해 사전 훈련을 받은 모델은 인간의 언어와 유사한 텍스트를 생성할 수 있기 때문이죠. 그러나 사전 훈련된 모델은 특정 애플리케이션이나 도메인에 대해 최적의 성능을 발휘하지 못하기 때문에, Generative AI는 파인 튜닝에 더욱 유의해야 합니다.
일반적으로 Generative AI 응용 프로그램을 위해 사전 훈련된 모델의 종류와 특징은 다음과 같습니다.
- GPT-3 (OpenAI) : 인간 언어로 입력된 프롬프트를 이해하고 인간과 같은 텍스트를 생성하기 위해 대량의 텍스트에 대해 사전 교육을 받았습니다.
- DALL·E (OpenAI) : 이미지 및 설명의 대규모 데이터 세트에 대해 교육을 받아, 설명과 일치하는 이미지를 생성할 수 있습니다.
- BERT (Google) : 대량의 텍스트 데이터로 훈련을 받았으며 특정 언어 작업을 처리하도록 파인 튜닝할 수 있습니다.
- StyleGAN (NVIDIA) : 동물, 얼굴 및 기타 물체의 고품질 이미지를 생성합니다.
- VQGAN + CLIP (Electrother) : 생성 모델 (VQGAN) 과 언어 모델 (CLIP) 를 결합하여 텍스트 프롬프트를 기반으로 이미지를 생성합니다.
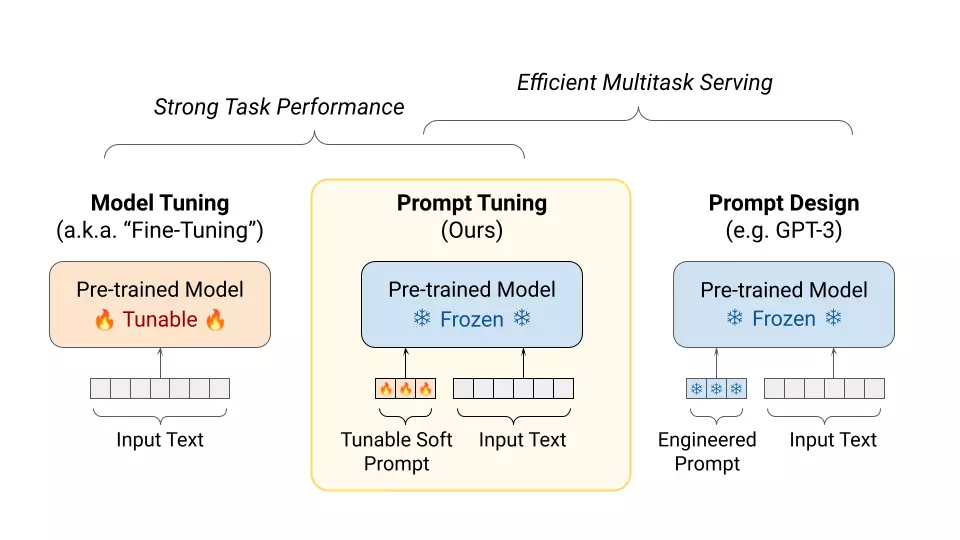
여기서 가장 많은 사람들에게 알려져 있는 GPT-3의 모델을 파인 튜닝하기 위한 가이드를 확인하실 수 있습니다. 과정을 간단하게 요약하자면 [ API 키 받기 → 데이터 세트 선택 → 학습 스크립트 생성 → 모델 학습 → 평가 ] 로 설명할 수 있습니다. GPT-3 모델을 파인 튜닝할 때 엔지니어가 주의해야 할 것이 있다면 아래와 같습니다.
- 데이터 집합이 클수록 모델의 성능이 향상됩니다.
- 배치 크기가 작으면 모델이 과적합되는 것을 방지하는 데에 도움이 됩니다.
- 학습 속도가 높으면 모델이 분산될 수 있습니다.
- 충분한 수의 에포크에 대해 모델을 훈련하면 더 나은 성능을 발휘합니다.
Generative AI는 사전 훈련된 모델을 필요에 따라 프롬프트 튜닝 또는 파인 튜닝하는 방식으로 구체화하고 여러 용도로 활용할 수 있습니다. 이에 따라 음악, 미술, 작문 등 다양한 분야에서 생성 모델이 사용되기 시작했습니다.
예측
Gebru et ai는 5천만 장의 구글 Street view 사진을 딥 러닝 네트워크에 입력한 결과, 컴퓨터가 자동차를 현지화하고 인식하는 과정에서 각 지역의 인구 통계를 예측할 수 있다는 사실을 발견했습니다. 또한 이를 가지고 흥미로운 인사이트들을 소개하기도 했습니다. 예를 들어, “15분동안 지나가는 차를 지켜봤을 때 세단의 수가 픽업 트럭의 수보다 많다면 그 도시는 다음 대통령 선거 때 민주당을 뽑을 가능성이 더 높다. (88%의 확률) 만약 그 반대라면, 공화당을 뽑을 확률이 더 높을 것입니다. (82%의 확률)” 인구 통계와 성향을 가지고 딥 러닝 네트워크가 예측한 것입니다.
또한 하버드 과학자들은 딥 러닝을 사용하여 컴퓨터에 점탄성 계산을 수행하도록 가르쳤습니다. 이 결과는 지진 예측에 사용되었습니다. 딥 러닝을 적용한 덕분에 계산 시간을 50,000%까지 개선했다고 하죠.
딥 러닝 활용에서 중요한 것은?
딥 러닝 장단점
딥 러닝은 인공지능 분야에서 매우 강력한 도구로 사람들의 신뢰를 받아왔습니다. 하지만 매력적인 강점 뒤에 숨겨진 뚜렷한 약점도 있기 마련이죠.
먼저 딥 러닝의 강점에 대해 살펴보겠습니다.
- 높은 정확도
딥 러닝은 대규모 데이터 세트를 기반으로 훈련하기 때문에 매우 뛰어난 정확도를 가지고 있습니다. 이는 이미지 및 음성 인식 (Image/audio recognition), 자연어 처리 (NLP) 등 다양한 분야에서 유용성을 입증했고, 많은 문제를 해결하고 있습니다. - 복잡한 문제 해결
딥 러닝은 다양한 입력 및 출력 사이의 복잡한 관계를 모델링하기 때문에, 인간이 쉽게 해결할 수 없는 복잡한 문제를 처리하는 데에 능숙합니다. 심층 신경망 내에 은닉층의 개수를 증가시킬 수록, 최적 요인의 표현 방법도 더욱 효과적으로 학습할 수 있습니다. - 자동화
딥 러닝은 데이터에 대한 사전 정의가 필요하지 않고, 훈련 데이터에서 패턴을 배울 수 있으므로 자동화된 학습과 예측이 가능합니다. 기존 규칙 기반 알고리즘 (Rule-based algorithm) 혹은 전통적인 머신러닝 알고리즘보다 딥 러닝 모델이 가지는 자동화 요인 추출 기능으로 제품의 자동화 구현까지 필요한 리소스와 규칙을 빠르게 찾아내고 제품에 커스터마이징 할 수 있습니다. - 일반화 능력
딥 러닝 모델은 비슷한 패턴을 갖는 다른 데이터에 대해서도 예측할 수 있는 능력을 가지고 있습니다. 이는 새로운 데이터에 대해서도 높은 성능을 발휘할 수 있게 해줍니다. - 도메인 지식을 필요로 하는 피쳐 엔지니어링의 영향을 받지 않습니다.
- 잘못된 예측 및 제품 결함으로 인한 비용 리스크를 줄일 수 있습니다.
- 모델이 모델을 구성하는 매개변수 학습에 걸리는 시간을 완화할 수 있습니다.

특히 딥 러닝의 문제 해결 능력에 대해서는 여전히 많은 연구가 이루어지고 있습니다. 과거 머신러닝 과학자들이 컨볼루션 신경망의 은닉층 (Hidden layer) 이 많을수록 사물에 대한 구체적인 분석이 이루어진다는 것을 알 수 있었습니다. 이는 이미지 인식 (Image recognition) 분야에서 중대한 발전을 가져다준 계기가 되었죠.
물론 산업에 딥 러닝을 적용하기 위해서는, 주의해야 할 단점도 알고 있어야 합니다.
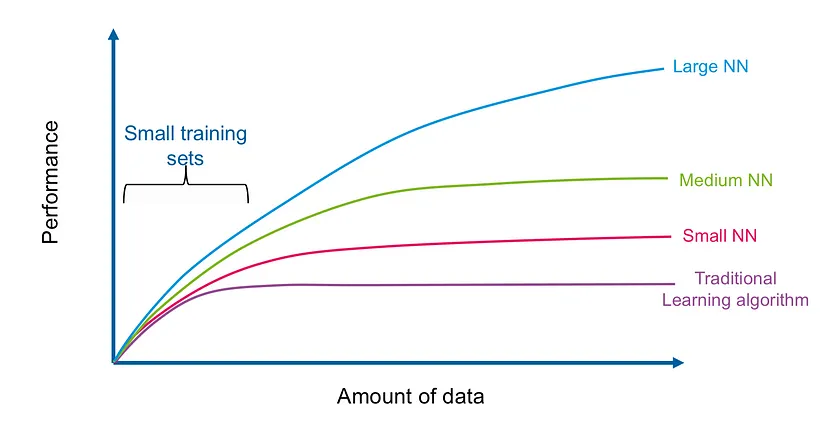
- 대량의 데이터 필요
딥 러닝은 대규모 데이터 세트로부터 훈련되므로, 충분한 양의 데이터가 필요합니다. 부족하거나 낮은 품질의 데이터는 모델 성능 저하로 이어질 수 있습니다. - 계산 리소스 요구
딥 러닝 모델은 많은 수의 연산과 계산 리소스를 필요로 합니다. 따라서 훈련 및 추론을 위한 강력한 하드웨어가 필요할 수 있습니다. - 블랙박스 모델
딥 러닝 모델은 사람들이 내부 작동 방식을 이해하기 어렵게 만드는 블랙박스 형태일 수 있습니다. 이는 모델의 의사 결정 과정을 설명하기 어렵게 만들 수 있습니다.
우리가 잘 아는 딥 러닝 모델은 대부분 천문학적인 비용을 들여 학습 데이터를 구성 및 정제하고, 이를 가지고 훈련한 결과로 구축된 모델일 가능성이 높습니다. 하지만 사람들은 이면에 있는 것보다 결과만을 보고 열광하기 때문에, 쉽게 생각하는 경우도 많죠. 만약 우리 산업이 당장 많은 데이터를 수집할 수 없는 경우, 오직 딥 러닝 만으로는 성과를 보기 어려울 수도 있습니다. 딥 러닝에서 데이터가 중요한 이유에 대해서는 아래에서 더 자세하게 설명하겠습니다.
딥 러닝에서 데이터가 중요한 이유
초기의 딥 러닝은 모델을 중심으로 연구가 지속되었지만 (model-centric), 현재의 딥 러닝 판도는 데이터 중심(data-centric)이라고 할 수 있습니다. 특히 실전에서 데이터를 활용해 모델을 교육하는 프로젝트를 진행하면, 데이터의 품질에 따라 머신러닝의 성능이 판가름나기도 합니다.
전문가들은 딥 러닝 구축의 문제들에 대해 코드를 개선하기 보다는 데이터를 개선하는 쪽으로 사고 방식을 바꿔야 한다고 설명합니다. 머신러닝 작업의 80%는 데이터 정리라고 말하고 있으며, AI 프로젝트의 성패 역시 데이터 정리에서 결정된다고 해도 과언이 아니라고 말했죠.

테슬라는 자율주행차의 핵심 기술인 객체 인식 및 예측, 주행 등을 실현하기 위해 딥 러닝과 데이터를 활용하고 있습니다. 테슬라는 자율주행차를 운전하는 동안 수집되는 다양한 데이터를 활용하여 딥러닝 모델을 학습하고 있습니다. 이 데이터에는 카메라, 레이더, 라이다 등에서 수집된 이미지와 센서 데이터가 포함됩니다. 테슬라는 이 데이터를 활용하여 자율주행차가 주변 환경을 인식하고, 주행을 제어할 수 있도록 학습하고 있습니다.
다른 데이터는 갖지 못한, 테슬라 주행 데이터만의 ‘차이’가 있다면 무엇일까요?
- 컴퓨터 비전 인식: 실제 주행 데이터를 기반으로 하여 물체를 감지
부정확성 감지 - 상황 스냅샷 저장 - 데이터 라벨링 - 재훈련 및 배포 - 예측: 실제 주행 데이터 기반으로 이벤트 시퀀스 앞 뒤 상황을 비전 데이터로 저장
과거 시점부터 되감기하며 라벨링하며, 결론이 정해져 있으므로 오토 라벨링도 가능
비전 데이터의 크기는 신경망으로 간소화하여 저장하며, 오토 라벨링과 데이터 간소화를 통해 학습 데이터 규모를 크게 확장할 수 있음 - 경로 계획 및 실운전: 속도 제한 유지, 차선 변경, 저속 차량 추월 등이 가능
현실 세계에서 인간의 주행 궤도를 모방하는 학습 방식을 적용
라벨러의 수동적인 라벨링 과정이 불필요
따라서 테슬라는 자사 차량으로부터 수집한 방대한 주행 데이터를 테슬라만의 방식으로 빠르고 정확하게 가공하여 그것을 모델에게 학습시킵니다. 이렇게 학습한 모델은 실제 도로 위에서 맞이한 변수에도 유연하게 대응할 수 있으며, 인간의 주행 방식을 모방하여 자연스러운 운전을 가능하게 했죠. 만약 테슬라가 모든 주행 데이터를 가공 과정 없이 raw data 상태로 학습 시켰다면 이런 성과는 거둘 수 없었을 것입니다. 부정확하거나 온전하지 않은 데이터가 포함되어 있을 것이기 때문이죠.
결론: 다양한 방면에서 딥 러닝을 활용하기 위한 사업 역량을 갖추는 것이 중요
“방대한 데이터가 필요”, “Inference에 연산이 많이 필요” 이 두 가지는 과거 딥 러닝의 한계로 지적 되었던 문제입니다. 그러나 과거보다 하드웨어 성능이 개선되면서 연산 속도가 빨라지고 모델의 성능이 개선되면서 한계를 점차 극복하고 있다는 평가입니다. 그러나 여전히 딥 러닝은 시작 단계에서부터 데이터를 필요로 하기 때문에, 학습 데이터의 품질 중요성에 대해서는 여러 번 말을 해도 부족합니다.
하지만 분야에 따라, 딥 러닝에 활용할 데이터를 무제한으로 만들어낼 수 있는 영역이 있고 그렇지 않은 영역이 있습니다. 이럴 때에 일반적으로 시뮬레이션으로 만든 데이터를 활용할 수도 있습니다. 기업은 우수한 품질의 데이터를 가져가는 것을 기본값으로 하고, 데이터를 가지고 모델을 활용하는 접근 방식을 고민하고 intuition 할 수 있는 역량이 중요해지고 있습니다.
또한 딥 러닝의 활용 방안은 매일 더 다양해지고 있으며, 여러 산업에 걸쳐 개발되고 있습니다. 인공지능이 세상을 바꾸고 있다는 말도 이젠 익숙한 표현이죠. 따라서 기업은 딥 러닝을 활용할 것인가에 대한 선택지보다, 어떻게 활용할 것인가에 대해 고민해야 합니다. 비즈니스에 적용할 모델을 결정했다면 그것을 효과적으로 수행할 수 있도록 고도화된 모델을 구축해야 합니다. 여기에서 고품질 데이터 구축 사업의 중요성이 드러납니다.
데이터헌트는 과학기술정보통신부가 주최하고 한국지능정보사회진흥원이 주관하는 ‘인공지능 학습용 데이터 구축사업’의 인공지능 학습용 데이터 품질관리 가이드라인 및 구축 안내서를 기반으로 고객사의 데이터 품질을 관리하고 있습니다. 국내 숙련된 데이터 라벨러를 고용하고 교육하여 고품질의 데이터를 구축하고 있습니다. 또한 동 라벨러를 최소화하려는 테슬라의 노력처럼 Auto-labeling을 도입하기도 했죠. 모든 기업이 모델 훈련 과정에서 데이터 품질의 중요성을 인지하고 시사할 수 있도록 데이터헌트의 여정도 계속 진행될 것입니다.
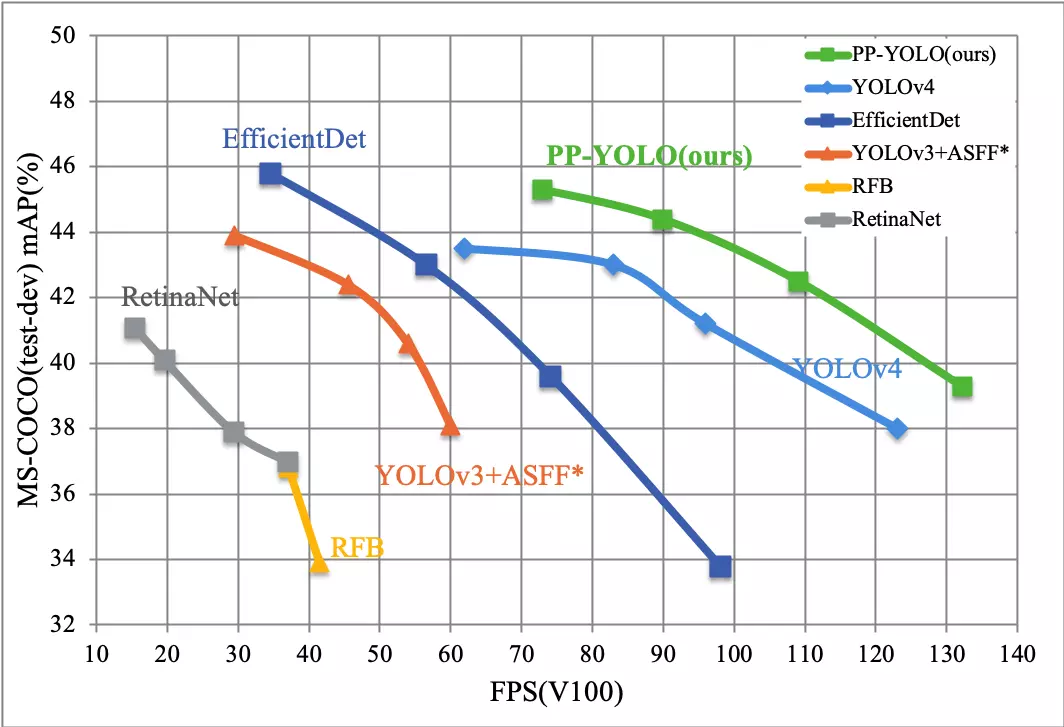
YOLO 버전별 차이점 비교
YOLO의 버전별 업데이트 내역은 아래와 같습니다.
- YOLO v1 (2016): 실시간 객체 검출을 위한 딥러닝 기반의 네트워크
- YOLO v2 (2017): v1에서 성능 개선 및 속도 향상
- YOLO v3 (2018): 네트워크 구조와 학습 방법을 개선하여 Object Detection 정확도와 속도 개선
- YOLO v4 (2020. 04): SPP와 AN 기술을 적용하여 Object Detection 정확도와 속도 개선
- YOLO v5 (2020. 06): 전작보다 정확도 10% 이상 향상, 모델 크기 축소
- YOLO v6 (2022. 07): 훈련 과정의 최적화, Trainable bag-of-freebies 제안
- YOLO v7 (2022. 09) 알고리즘의 효율성 향상, 시스템 탑재를 위한 Quantization과 Distillation 방식 도입
- YOLO v8 (2023. 01): 새로운 저장소를 출시하여 객체 감지, 인스턴스 세분화 및 이미지 분류 모델 Train을 위한 통합 프레임 워크로 구축
흔히 YOLO 버전을 비교할 때는 v5와 최신 버전인 v8 중에서 선택합니다. YOLOv5는 사용이 편리하며, YOLOv8은 더 빠르고 정확하다는 장점이 있습니다. 궁극적으로 사용할 모델을 결정하는 것은 애플리케이션의 요구 사항에 따라 달라지지만, 대체적으로 실시간 Object Detection 작업이 필요할 경우 YOLOv8을 선택하는 경향이 있습니다.
YOLO 적용 사례 - Use Case
실시간성 활용 - CCTV 및 드론 영상 해양 조난자 검출
선박해양플랜트 연구소는 해양 조난자 검출 모델에 딥러닝 Object Detection 방식을 활용하였습니다. 보다 효율적이고 정확한 검출을 위해 AI를 기반으로 실시간 생존자 수색 솔루션을 개발했죠. YOLO 모델의 실시간성을 활용하여 딥러닝 모델이 드론 영상 데이터를 기반으로 객체와 조난자 여부를 탐지할 수 있었습니다.
그 외에도 CCTV 영상을 분석하여 교통량 혹은 인구 밀집 지역을 확인하는 데에도 YOLO 모델이 사용되었습니다. COVID-19 팬데믹 상황에서 마스크 착용자 및 발열 환자를 손쉽게 가려낼 수 있었던 것도 YOLO가 실시간 객체 검출이 가능했기 때문입니다.
불량 검출과 품질 평가 - 농업, 제조업
수확한 작물의 품질과 불량 분류는 매우 중요한 일이지만, 부족한 자본과 인력 문제로 쉽지 않은 일이었습니다. 이에 인공지능 기반의 딥 러닝 알고리즘을 이용해 불량 검출 모델이 완성되었죠. YOLOv3 알고리즘을 활용해 만들어진 이 모델은 데이터 수집부터 분석된 데이터를 통한 품질 평가, 그리고 최종적인 불량 검출에 이르는 과정을 자동화할 수 있었습니다.
이처럼, YOLO 모델은 다양한 사용자의 필요에 따라 맞춤형 학습 데이터로 훈련하는 것으로 발전하고 있습니다. YOLO는 사용자가 만든 데이터셋으로 자유롭게 학습할 수 있습니다. 일반적으로 큰 데이터셋으로 모델을 학습시키려면 오랜 계산 시간과 연산량이 필요합니다. 학습 전에 사전 학습된 모델 파일을 사용하면 학습 분포가 많아지는 것은 물론, 학습 시간도 단축할 수 있습니다. 전이학습 기법을 사용하면 YOLO를 더 빠르고 정확하게 사용할 수 있죠.
그러나 내 필요에 맞는 사전 학습 모델이 없을 경우, 대규모의 데이터셋을 학습시키는 과정이 필요합니다. 이 과정이 끝난 후 YOLO가 기대한 만큼의 정확도를 가지기 위해서는 학습 데이터의 품질이 보장되어야 합니다.
YOLO 노하우 - 핵심은 고품질 학습 데이터

YOLO의 한계
최초로 YOLO에 대해 소개한 논문에 의하면, 이 모델의 단점은 4가지로 요약할 수 있습니다.
- 각 Grid Cell마다 8개의 Bounding box만 추측해야 한다는 공간 적 제약성이 있어 가까이 붙어있는 물체를 판별하기 어려움
- 여러 개의 Down Sampling을 사용하는 문제로 종종 디테일하지 못한 Feature가 드러날 수 있음
- 부정확한 Localization
- 데이터로부터 Bounding box를 훈련시키기 때문에, 학습 데이터에 없는 것이 시범 데이터로 주어질 경우 검출이 어려움
딥러닝의 가장 큰 장애물은 학습 데이터를 준비하는 것입니다. 그러나, 각자의 응용 영역에서 적용할 수 있는 데이터는 매우 제한되어 있습니다.
한계에도 불구하고 기존 모델에 비해 매우 빠른 연산 속도를 자랑하기 때문에 YOLO 모델은 여전히 사랑 받고 있습니다. 그러나 높은 정확도의 모델을 구현하기 위해서는 완성도 높은 학습 데이터가 필요합니다. 불완전한 학습 데이터 탓에 모델이 배우지 못한 것을 검출해야 한다면 정확도가 떨어지고, 이는 곧 비즈니스적인 신뢰도 저하로 이어질 수 있습니다.
고품질 학습 데이터 구축, 데이터헌트는 어떻게?
당시 주차로봇을 구현하는 과정에서 차량이 지면에 붙은 사진이 필요했습니다. 또한 차량의 높이를 학습하기 위한 데이터가 필요했죠. 수많은 차종의 높이를 측정하는 방식을 도출하고, 로봇의 시선으로 사진을 촬영해야 하는 어려운 미션이었습니다. 데이터헌트가 높은 정확도로 Annotation한 학습 데이터는 주차로봇의 완성도 높은 모델 구축에 큰 도움이 될 수 있었죠.
또한 세계 각지에서 수집한 도로 데이터 및 자율주행 데이터에서 차선 및 도로의 경계 Polyline 레이블링을 하는 작업도 진행했습니다. 작업 난이도가 특히 높은 만큼 세심한 작업을 필요로 했죠. 이에 숙련된 국내 라벨러와 협업하여 학습 데이터 가공 작업에 대한 집중 교육을 시행했습니다. 이를 통해 30만 장의 데이터를 구축하고, 오류율은 5% 내외로 줄일 수 있었습니다.
데이터헌트의 Object Detection 정확도 향상 노하우
딥러닝 기반 객체 분류 모델을 개발하기 위해서는 학습 데이터를 준비하고, 필터링·라벨링 등의 가공 과정이 필요합니다. 모델이 잘 배울 수 있도록 중복된 데이터를 제거하거나, 잘못된 데이터는 없는지 꼼꼼히 살펴보는 과정이 필요하죠. 또한 학습 데이터가 너무 적을 경우에도 모델의 품질 저하 문제가 발생할 수 있습니다.
과거에는 고성능 모델 개발에 집중했었다면 최근 모든 AI 기반 작업의 첫 단추이자 핵심 키워드는 데이터 정확도에 있습니다. 모델의 성능을 온전히 활용하기 위해서는 고품질 데이터가 무엇보다 중요하기 때문이죠. 데이터헌트는 고객사가 가장 필요로 하는 데이터를 인식하고, 이를 가공하는 데에 특화되어 있습니다.
YOLO처럼 오픈 소스의 모델은 누구에게나 동일한 성능을 낸다고 생각하기 쉽지만, 어떤 데이터 라벨링 파트너를 만나느냐에 따라 모델의 성능이 천차만별로 나뉠 수 있습니다. 데이터헌트와 같은 데이터 가공 및 학습 데이터 구축 전문가가 필요한 이유죠.
요약
- YOLO(You Only Look Once) 모델은 Real-time Object Detection 시스템으로, Joseph Redmon 등에 의해 소개되었으며 2023년 6월 기존 v8까지 출시되었습니다.
- YOLO 모델은 그리드에서 분할한 이미지를 신경망에 통과시킨 뒤 Bbox 기법으로 최종 감지 출력을 생성하는 모델로, 빠른 속도와 정확도가 특징입니다.
- YOLO 등의 모델은 데이터를 기반으로 학습한 내용에 의해 결과가 도출되므로, 성능 및 정확도 향상을 위해서는 고품질의 학습 데이터 구축이 필요합니다.
온라인 사이버 보안 활용 기술
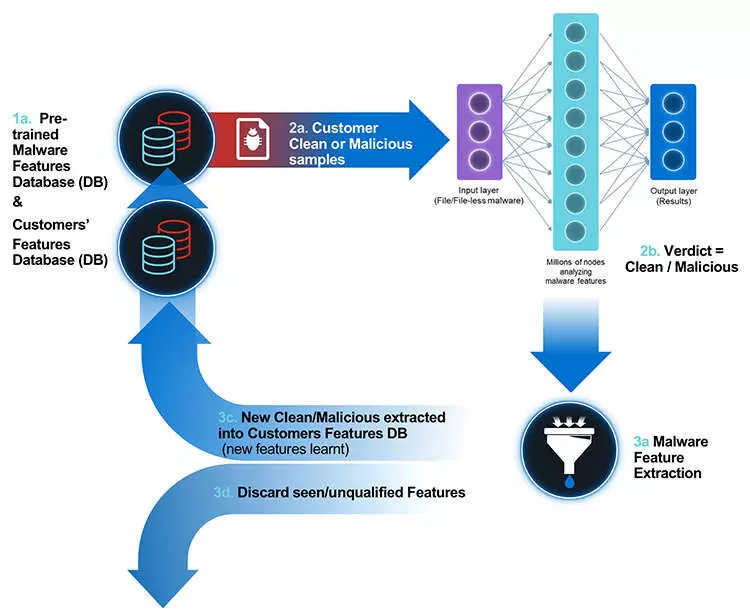
패턴 및 시그니처 기반 탐지 (Pattern and signature-based detection)
AI는 사전에 알려진 악성 코드, 사이버 공격 및 다른 보안 위협에 대한 패턴과 시그니처 데이터베이스와 비교하여 이상 행위를 감지합니다. 이러한 데이터베이스는 지속적으로 업데이트되며, 새로운 위협에 대한 정보가 추가됩니다.
보안 AI 인공지능 적용 사례
클라우드 환경의 사이버 보안 - Google
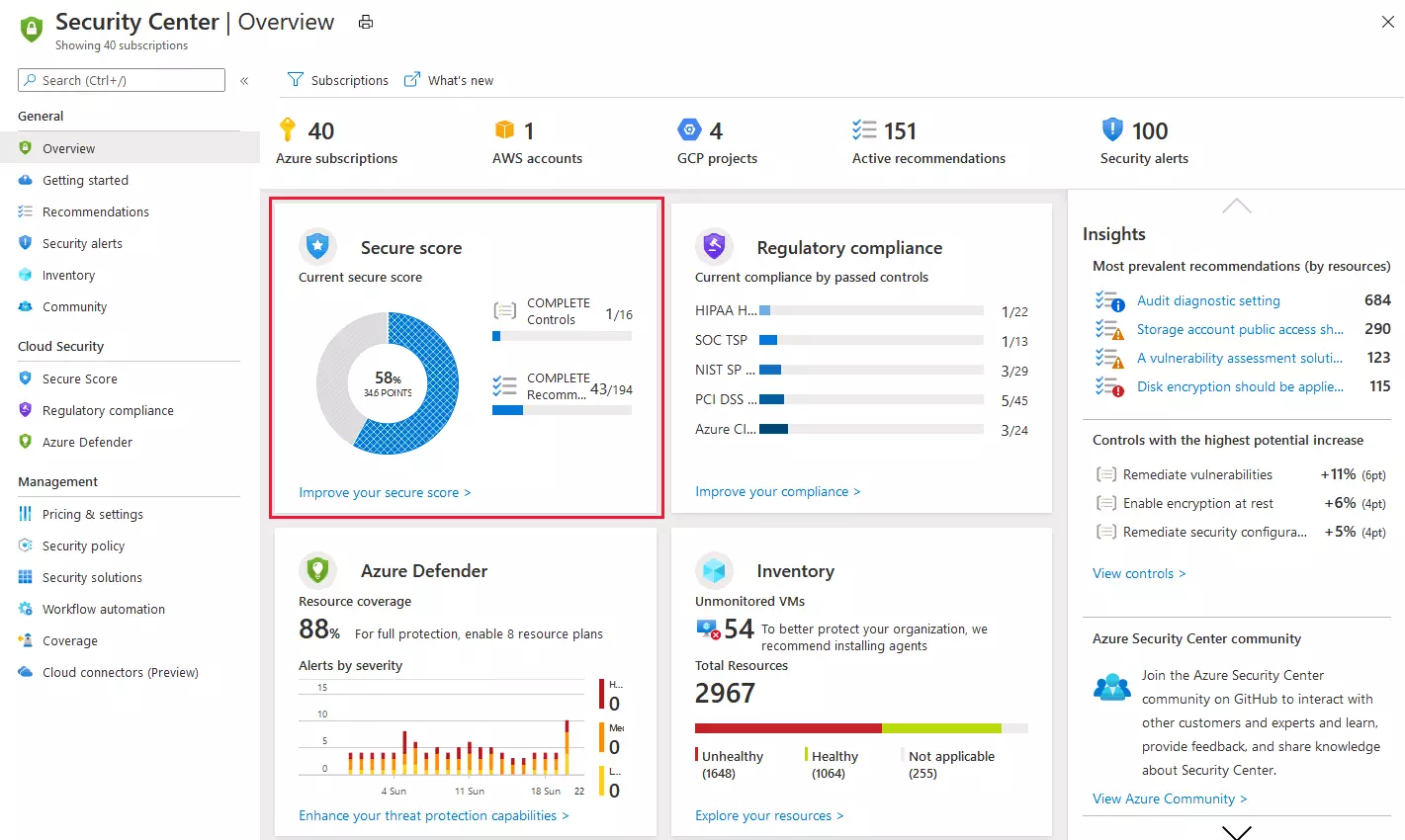
Google은 자체 보안 인텔리전스 시스템을 구축하여 악성 소프트웨어와 행동 패턴을 인식하고 차단하는 데에 AI와 머신러닝을 활용합니다.
Google Security Command Center는 TensorFlow 기반의 보안 솔루션입니다. 사용자의 클라우드 환경을 지속적으로 모니터링하여 이상 행위를 탐지하고, 보안 위협에 대응할 수 있습니다. 또한 사용자 환경에서 보안 문제를 감지하기 위해 Event Threat Detection 및 Security Health Analytics와 같은 서비스를 사용합니다. 이러한 서비스는 Google Cloud에서 로그 및 리소스를 스캔하여 위협 표시기, 소프트웨어 취약점, 잘못된 구성을 찾을 수 있습니다.
시각 AI 기술로 구현한 CCTV - UST 연구진

대한민국은 열악한 보안 인력 문제로, CCTV가 있어도 위험 상황에 즉각 대응하기에는 어렵다는 고질적인 문제를 앓고 있었습니다. 그러나 작은 인력으로도 이상행동을 감지할 수 있는 지능형 CCTV가 개발되면서, 이를 극복할 수 있을 것으로 기대되고 있습니다.
과학기술연합대학원대학교(UST) 한국전자통신연구원(ETRI)에서 개발한 지능형 CCTV는 다수의 이상상황을 복합적으로 검출, 판단할 수 있는 통합 프레임워크 기술이 적용되었습니다. 여기에는 시각 인공지능과 언어 인공지능을 결합한 방식으로 컴퓨터가 시스템 경험에 근거하여 정보를 스스로 조합해 결과를 유추하는 ‘제로샷 학습(Zero-shot Learning) 기법’이 적용되었습니다. 궁극적으로 추론 과정에서 탐지 상황을 설정하고 분석하는 인공지능(AI) 기술로 빅데이터 구축 시간과 비용, 기술응용 효율성을 높였다고 하죠.
👉 Foundation Model 기반으로 적은 데이터로 학습시키는 few-shot learning에 대해

모델 학습을 위해서, 데이터는 많을수록 좋다는 인식이 있습니다. 하지만 실제로 반드시 데이터가 다다익선인 것은 아닙니다. 최근에는 제한된 데이터로 학습하는 few shot learning 방법론에 대한 관심이 높아지고 있습니다.
빠르게 진화하는 인공지능 분야에서 제한된 데이터로부터 학습하고 일반화하는 능력이 중요해졌습니다. 아래 글을 통해 few shot learning 방법론이 AI 모델 교육에 유망한 솔루션이 될 수 있는 이유에 대해 설명하겠습니다.
Few shot learning 개념
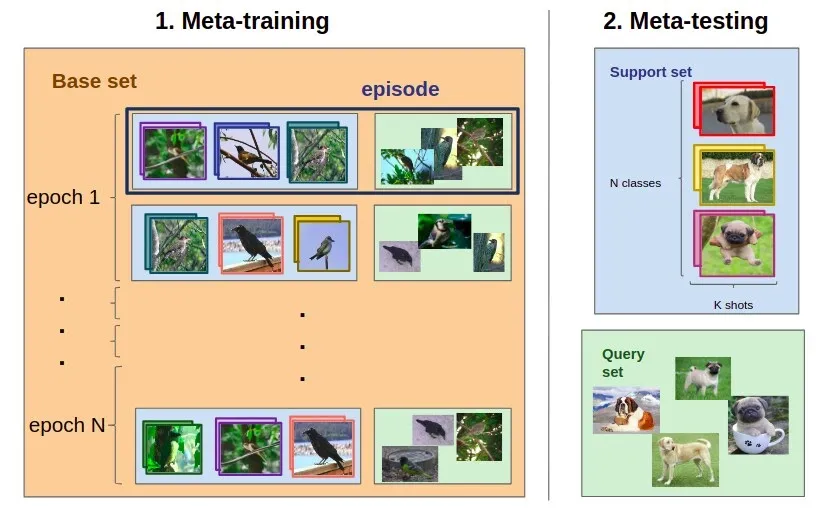
Few shot learning의 정의
Few shot learning은 10개 미만의 한정된 샘플로부터 학습할 수 있는 머신러닝 방법론을 의미합니다. 보통 딥러닝 모델이 대량의 데이터로 사전 학습된 다음, 새 작업에 대한 몇 가지 샘플로 미세 조정하여 수행하고 있습니다.
머신러닝은 인간과 유사한 학습 기능 사이의 격차를 해소하는 것에 목표를 두고 있습니다. 마치 사람이 몇 가지 예시만으로 새로운 개념을 빠르게 익힐 수 있듯이, 모델에게도 가능성이 있다고 보는 것이죠.
주요 과제와 목표
few-shot learning는 레이블이 지정된 훈련 데이터가 부족하거나, 효과적인 표현 학습이 필요할 때, 보이지 않는 새로운 클래스로 일반화하는 능력 등의 문제를 해결할 필요가 있습니다.
Few shot learning은 모델을 훈련하는 데에 필요한 데이터의 양을 줄여 모델의 훈련 및 배포 비용을 절감할 수 있다는 장점이 있습니다. 또한, 모델은 새로운 태스크에 더 쉽게 적응할 수 있기 때문에 모델의 유연성과 적응성을 높일 수 있죠.
이 방법론은 NLP 및 컴퓨터 비전과 같은 다양한 영역에 적용할 수 있습니다.
Few shot learning vs. Zero shot learning 비교
머신러닝 모델이 이전에 보거나 학습한 적이 없는 카테고리나 레이블을 ‘클래스’라고 합니다. ZSL(Zero shot learning)이란, 머신러닝 Training 과정 중에 새로운 클래스의 예시를 보지 않고도 인식하는 방법을 학습할 수 있는 머신러닝 방법론입니다. 즉, 새로운 클래스에 대한 명시적인 훈련 없이도 모델이 속성이나 특성에 대한 정보를 사용하여 정확하게 인식하고 분류하도록 학습시킬 수 있습니다.
ZSL은 시맨틱 임베딩(Semantic embedding)과 속성(feature) 기반 학습을 활용하여 학습 프로세스를 최적화합니다. 이 원리를 자세히 살펴보면 아래와 같습니다.
- 시맨틱 임베딩이란 단어 또는 구문을 벡터 공간에 매핑하는 자연어 처리 기법입니다.
- 벡터 사이의 거리는 단어 또는 구문 간의 의미적 유사성을 반영합니다.
- 일반적으로 라벨링이 없는 대규모 데이터에 대응하는 방법으로 사용합니다.
- 이전에 학습한 모델을 사용해 새로운 문제를 해결할 수 있습니다.
Zero shot learning은 새로운 클래스부터 학습할 수 있다는 점과 이미지 인식 및 자연어 이해 등 다양한 영역에서 빛을 발하고 있습니다. 정보 검색이나 텍스트 분류, 번역을 비롯한 여러 애플리케이션에서 활용하고 있습니다. 예를 들어, AirBnB는 Zero shot learning을 사용하여 게스트의 선호도를 예측하고 이에 맞는 숙소를 추천합니다.
Zero shot learning, few shot learning 모델에서 가장 두드러지는 차이점은 아래와 같습니다.
1. 데이터
- FSL: 레이블이 지정된 소량의 예제가 필요
- ZSL: 레이블이 지정된 예제 불필요
2. 활용 분야
- FSL: Image classification, NLP, 강화 학습(Reinforcement learning) 등 다양한 작업에 사용
- ZSL: 일반적으로 질문 답변 및 요약과 같이, 텍스트를 이해하거나 생성하는 작업에서 유용
3. 알고리즘
- FSL: 일반적으로 학습 방법을 학습하는 기술인 메타 학습(Meta learning)을 사용
- ZSL: 새로운 데이터를 생성할 수 있는 생성 모델을 기반
4. 성능
- FSL: 적은 수의 예제로 높은 성능을 보이지만 대규모 데이터 세트에서 학습된 기존 머신러닝 알고리즘보다 정확도가 떨어지는 한계
- ZSL: 높은 정확도를 달성할 수 있지만 데이터의 노이즈나 이상값에 취약
위의 내용을 토대로 예시를 들어보겠습니다. Few shot learning은 몇 개의 레이블이 지정된 예시를 보고 다양한 유형의 꽃 이미지를 분류하는 모델을 훈련할 수 있게 됩니다. 반면 Zero shot learning 모델은 프랑스어 데이터에 대해 학습하지 않아도 영어에서 프랑스어로 텍스트를 번역하는 모델을 구축하는 데에 사용할 수 있습니다. 유사한 면도 있지만, 장점과 한계가 명확히 다른 모델입니다. 따라서, AI 모델을 통해 해결하고자 하는 문제나 목표를 구체화한 뒤 어떤 기법을 사용할 것인지 결정할 필요가 있습니다.
Few shot learning 원리
접근 방식
few shot learning 방법론은 세 가지의 접근 방식으로 나눌 수 있습니다.
- 메트릭 기반 방법: 유사성 메트릭을 활용하여 레이블이 지정된 몇 가지 예시와의 유사성을 기반으로 새 인스턴스를 비교하고 분리합니다. 프로토타입 네트워크와 매칭 네트워크는 메트릭 기반의 few shot learning의 대표적인 예시 중 하나입니다.
- 모델 기반 방법: 사용 가능한 레이블이 지정된 예제에서 생성 모델을 학습한 다음, Few shot learning 시나리오에서 새로운 샘플을 생성하는 것을 목표로 합니다. 일반적으로 VAE(Variational Autoencoder) 및 GAN(Generative Adversarial Networks)은 모델 기반의 few shot learning에 사용합니다.
- 최적화 기반 방법: 최적화 기반 방법은 소수 학습을 최적화 문제로 공식화하여 모델이 사용 가능한 몇 가지 훈련 예제에 맞게 파라미터를 조정합니다. MAML(모델에 구애받지 않는 메타 학습) 및 Reptile과 같은 방법이 이 범주에 속합니다.

학습 방법
Few shot learning은 대개 4가지 방법으로 분류할 수 있습니다.
- 메모리 기반 방법
- 훈련된 모델의 메모리를 사용하여 새로운 작업을 학습
- 개와 고양이를 구별하는 방법을 배운 경우, 개와 고양이의 이미지가 포함된 메모리를 가질 수 있음
- 새로운 이미지를 볼 때 모델은 메모리를 사용하여 이미지가 개인지 고양이인지 결정할 수 있음
- 사전 훈련된 모델 사용
- 이미 대규모 데이터 세트에서 학습한 모델
- 사전 훈련된 모델을 미세 조정하여 새 작업에 맞게 조정할 수 있음
- 규제된 학습, Supervised learning
- 모델이 학습하는 동안 오류를 방지하는 데 사용
- 훈련 데이터에 너무 맞지 않도록 할 수 있음
- 강화 학습, Reinforcement learning
- 모델이 실수를 통해 학습
- 새로운 작업을 수행하는 방법을 스스로 배울 수 있게 함
Few shot learning 장점
Few shot learning은 일반적으로 레이블이 지정된 데이터가 많은 데이터 세트에서 모델을 미리 학습한 다음, 소량의 데이터로 새로운 작업을 학습하는 방법입니다.
이는 딥러닝의 전통적인 방식과 대조되는 모델입니다. 기존 모델이 훈련 데이터 세트에서 많은 예시를 사용하여 학습하던 것과는 반대의 방법론이죠. 현재 few shot learning은 컴퓨터 비전, 자연어 처리 및 로봇 공학을 포함한 다양한 분야에서 활약하고 있습니다.
2000년대 초반에는 훈련 데이터가 적은 상황에서 분류나 회귀 및 클러스터링 작업을 수행하는 방법을 연구해왔었습니다. 대규모 컴퓨터 비전 데이터 세트의 가용성 증가와 딥러닝의 발전으로 few shot learning의 발전도 크게 증가했죠.
few shot learinig은 몇 개의 샷만으로 작업을 학습할 수 있는 모델을 만드는 데 사용됩니다. 대표적인 사용 예시는 아래와 같습니다.
- 몇 장의 이미지만으로 새로운 개체를 식별할 수 있는 컴퓨터 비전 시스템
- 몇 개의 문장만으로 새로운 언어를 번역할 수 있는 자연어 처리 시스템
- 몇 가지 예시를 통해 새로운 작업을 수행할 수 있는 로봇 시스템
Few shot learning은 기존의 머신러닝 방법론보다 새로운 작업을 학습하는 데에 필요한 데이터가 적습니다. 이로 인해 데이터 수집 비용이 많이 들고, 시간이 많이 걸릴 수 있는 특정 작업에서 유용하게 활용할 수 있죠.
또한 새로운 작업이 자주 변경되는 경우, 더 빠르게 적응할 수 있다는 장점에도 주목할 필요가 있습니다. 마찬가지로 다양한 종류의 데이터에 대한 모델을 학습해야 하는 경우, 기존의 방법론보다 더 빠르게 일반화할 수 있습니다.
Few shot learning Use case
적용 분야
Few shot learning은 컴퓨터 비전과 음성 기술, 자연어 처리 등 다양한 영역에서 사용하고 있습니다.
- 컴퓨터 비전 (Computer vision)
이미지 분류 (Image classification): 트레이닝 셋 대상 클래스 이외의 보이지 않는 이미지 분류
얼굴 인식(Face recognition): 별도의 교육 없이도 개개인의 기본 특징 추출
Image-to-Image Conversion: 알 수 없는 이미지의 스타일을 알고 있는 이미지 스타일로 전환
- 음성 기술 (Speech Technology)
음성 변환: 보이는/보이지 않는 대상 화자가 말하는 것처럼 말하도록 모든 소스의 말하는 스타일을 변경
사운드 이벤트 분류: 관찰되지 않은 사운드 이벤트 분류
감정 분류: 말에서 관찰되지 않는 감정을 분류
- 자연어 처리 (NLP)
텍스트 분류 (Text classification): 관찰되지 않은 텍스트 클래스를 분류하는 기능
애플은 사용자의 사용 패턴을 학습하기 위해 few shot learning을 사용합니다. Siri는 처음으로 질문을 받으면 유사한 질문의 몇 가지 예시를 사용하여 새로운 질문에 대한 답변 방법을 학습합니다. 이를 통해 Siri는 이전에 들어본 적 없는 질문을 받더라도, 더 정확하고 관련성 높은 답변을 제공할 수 있습니다.
이외에도 애플은 사용자에게 적합한 콘텐츠를 추천하기 위해 few shot learning을 사용합니다. 사용자가 앱을 다운로드하면 앱 스토어는 사용자가 다운로드한 다른 앱의 몇 가지 예를 사용하여 사용자의 관심사를 학습합니다. 또한 뉴스 앱은 사용자가 읽은 다른 기사의 몇 가지 예를 사용하여 사용자의 관심사를 파악하죠. Few shot learning은 애플이 보다 효율적이고 효과적인 방식으로 사용자에게 개인화된 콘텐츠를 제공할 수 있도록 합니다. 소수의 예시를 통해 학습하고 그 지식을 훨씬 더 많은 사용자에게 적용하면, 사용자에게 더욱 개인화된 경험을 제공할 수 있으며 참여도와 만족도를 높일 수 있죠.
최신 트렌드
최근 머신러닝 트렌드는 모델의 속도 개선과 학습 데이터 퀄리티에 주목하고 있습니다. 예를 들어 ChatGPT와 같은 대규모 언어 모델(LLM)은 방대한 양의 데이터에 대해 교육을 받았기 때문에, few shot learning 모델이 새로운 작업을 빠르게 학습하는 데에 도움이 될 수 있습니다. 이외에도 few shot learning 모델의 학습 및 추론 속도를 높이는 데에 사용되는 하드웨어 가속의 사용이 증가하고 있습니다.
또한, 대량의 데이터를 구축할 수 없는 사업에서 few shot learning 모델을 활용하려는 움직임이 증가했습니다. 스탠포드 대학의 연구원들은 적은 수의 이미지로 피부암을 진단할 수 있는 AI 시스템 개발에 few shot learning을 사용하고 있습니다. 의료 분야의 경우, 모델을 학습시킬 데이터의 절대적인 양이 부족하다는 사실이 모델 훈련의 걸림돌이 되어왔기 때문이죠. 소량의 데이터라도 모델이 분석 및 인식할 수 있을 정도로 정확성과 품질을 갖춘다면 few shot learning 모델을 통해 충분히 좋은 AI 시스템을 만들 수 있습니다.
데이터헌트가 생각하는 few shot learning 모델 학습 데이터 품질의 기준은 아래와 같습니다.
- 데이터는 모델을 학습시키는 데에 필요한 모든 정보를 포함해야 합니다. 긍정적인 예는 물론, 부정적인 예와 다양한 클래스의 예시를 모두 포함해야 합니다.
- 데이터의 오류는 모델의 오류로 이어질 수 있으므로 매우 중요한 기준입니다.
- 모델이 사용할 데이터는 실제 세계를 대표할 수 있어야 합니다. 데이터가 실제 세계와 유사하지 않으면 모델이 새로운 데이터에 잘 일반화될 수 없습니다.
데이터헌트는 few shot learning 모델과 같은 소량의 데이터가 필요한 경우, 기존보다 더 엄격한 데이터 품질 기준이 필요하다고 생각합니다. 따라서 모든 학습 데이터 가공 과정을 AI의 손으로 빌리는 것보다, Ai assisted의 형태로 진행하되 HITL(Human in the loop)를 통해 인간 작업자의 손을 반드시 거칩니다. 데이터 오류나 이상값, 중복 데이터 제거 등의 업무는 물론 레이블을 지정하는 것까지 AI와 사람이 협업해 정확도를 개선합니다. 데이터 다양성 개선, 품질 프레임워크 등의 업무에서 전문가의 검수를 거친 끝에, 정확도 99%의 학습 데이터를 가공할 수 있게 되었죠.
Few shot learning 한계와 미래
Few shot learning은 아직 개발 초기 단계에 있지만, 이미 다양한 작업에 적용되어 성공을 거두었습니다. 이 방법론은 앞으로도 계속 발전할 것이며, 기존의 머신러닝 모델을 대체할 수 있는 잠재력이 있다고 평가 받고 있습니다. 물론 극복해야 할 문제점도 있습니다.
Few shot learning 한계
‘서당 개도 3년이면 풍월을 읊는다’는 말이 있습니다. 일반적으로 사람은 새로운 작업에 앞서 몇 번의 경험이면 쉽게 익힐 수 있습니다. 그러나 모델을 훈련하기 위해서는 많은 데이터가 필요합니다. 그러나 의료 진단이나 자연어 처리와 같이 데이터가 부족한 작업에서는 대량의 데이터를 구축하는 과정에서 많은 문제가 발생할 수 있습니다.
많은 데이터를 구축했다고 하더라도 처리 리소스가 많이 들어갈 경우 비용과 시간이 많이 들기 때문에 실시간 애플리케이션에 적용하기 어려운 한계에 부딪힐 수 있습니다.
Few shot learning 모델은 이러한 문제를 해결할 수 있는 방법이 될 수 있습니다. 그러나, 이 모델 역시 이와 비슷한 한계를 가지고 있다는 평가도 있습니다. 일반적인 모델의 문제점과 더불어 Few shot learning 모델이 가지고 있는 추가적인 한계도 있습니다.
- 작업 전이성: Few shot learning 모델은 일반적으로 이미지 분류나 자연어 번역과 같은 특정 작업에 대해 학습합니다. 즉, 유사한 작업이라 하더라도 다른 작업으로 일반화하지 못할 수 있습니다.
- 모델 복잡성: Few shot learning 모델은 복잡할 수 있으며, 이로 인해 이해하고 설명하기 어려울 수 있습니다. 이는 의료나 금융과 같이 투명성이 중요한 애플리케이션에서 문제가 될 수 있습니다.
GPT의 사례에서 보는 Few shot learning의 미래
GPT-4는 다음 단어를 생성할 때 시퀀스 내 단어의 관련성을 평가하는 트랜스포머 아키텍처를 활용합니다. 이 모델은 방대한 인터넷 텍스트 말뭉치를 가지고 학습했지만, 추론을 위해 단발성 학습을 활용한다는 점에서 다른 언어 모델들과 차별화되고 있습니다.
‘프롬프트’로 불리는 몇 가지 예제들은 GPT-4가 해결해야 할 과제의 데모 역할을 합니다. 학습 과정을 훈련과 추론 단계로 나눠서 설명하는 것은 아닙니다. 다만, 과거와 현재에 입력된 프롬프트를 진행 중인 대화의 일부로 간주하고 시퀀스에서 다음 단어를 예측하는 것입니다.
ChatGPT는 few shot learning이 얼마나 효율적으로 구현될 수 있는지 보여주는 예시입니다. ChatGPT와 상호 작용할 때, 우리는 대화 프롬프트를 입력합니다. 그러면 모델이 사전 학습 데이터와 함께 이를 처리하여 응답을 생성합니다. 이후에는 각 사용자의 입력과 모델 출력은 대화 기록에 추가됩니다. 모델은 이를 활용하여 관련성 있는 응답을 생성하죠.
하지만 이 방법론의 한계 역시 ChatGPT에서 찾을 수 있습니다. few shot learning은 새로운 작업에 빠르게 적응하는 데는 탁월하지만, 여전히 모델이 사전 학습 단계에서 얻은 지식에 의존하는 경향이 있습니다. 따라서 훈련 데이터 세트에 포함되지 않거나, 훈련 컷오프 이후에 세상에 소개된 주제나 사실(예를 들면, ChatGPT는 2021년 9월 이후의 콘텐츠는 알 수 없죠.)에 대해서는 정확한 답변을 생성할 수 없습니다. 또한, 실제 세계에 대한 이해가 아닌 학습 데이터에서 학습한 통계 패턴에 의존하기 때문에 종종 부정확하거나 오해의 소지가 있는 답변을 생성할 수도 있죠.
결론: 효과적인 Few shot learning 모델을 위해서는 원본 데이터가 중요하다
ChatGPT의 예시를 통해, 우리는 few shot learning이 가지고 있는 근본적인 한계점에 대해 알 수 있었습니다. 양은 적더라도 고품질의 학습 데이터를 확보해야 한다는 점과, 부족한 Sample 학습이 이뤄질 경우 Overfitting(과적합)의 가능성이 높다는 점이죠.
하지만 Few shot learning을 통해 기대할 수 있는 바도 많습니다. 먼저, 훈련 데이터에 지나치게 맞춰져서 새로운 데이터에 일반화하지 못할 가능성을 최소화합니다. 이러한 문제는 모델이 훈련 데이터의 세부 사항에 대해 학습한 뒤, 새로운 데이터의 패턴에 대해 학습하지 못했기 때문에 발생하는 것입니다. 최근 LLM 기반 Generative AI의 눈부신 발전으로 다양한 산업에서 AI 챗봇 등을 도입하는 시도가 많은데 필요한 정확도를 사전에 정의하는 것이 꼭 필요합니다.
결론적으로, 처음 학습한 원본 데이터가 고품질일 경우 초기 학습 단계에서 모델의 정확도를 잡을 수 있기 때문에 few shot learning이 더욱 효과적으로 작용할 수 있습니다. 데이터헌트는 모델이 처음 만나는 데이터의 품질 관리에 심혈을 기울이는 이유도 이와 같습니다.
Few shot learning은 AI가 희소한 데이터나 새로운 작업에 직면했을 때에도 보다 효율적으로 학습하고 적응할 수 있는 미래를 약속합니다. 다만 정확한 의미 표현의 필요성에 주목하고, 편향된 시각을 주의해야 합니다. 하지만 훈련 데이터가 적은 상황에서 새로운 작업을 학습하는 데 유용한 방법론이 될 수 있으므로, 앞으로 연구해야 할 가치는 충분할 것입니다.
요약:
- few shot learning은 한정된 샘플로부터 학습할 수 있는 머신러닝 방법론으로, 데이터가 부족한 상황에서 모델이 일반화하여 정확한 예측을 할 수 있게 해주는 방법론입니다.
- 이는 몇 장의 이미지만으로 새로운 개체/언어 등을 식별하고, 작업을 수행할 수 있게 해주어 컴퓨터 비전이나 자연어 처리 및 로봇 공학을 포함한 다양한 분야에서 활용하고 있습니다.
- ChatGPT의 예시에서 볼 수 있듯이, Few shot learning은 기존 학습 데이터를 기반으로 다음 작업을 수행하기 때문에 원본 데이터의 품질과 정확도를 가져가야만 가장 효율적으로 사용할 수 있습니다.
그간 지능형 CCTV는 이미 많은 제품이 있었지만, 이 모델이 특별한 이유는 따로 있습니다. 바로 한국인터넷진흥원(KISA)의 일곱 가지 지능형 CCTV 인증 영역인 ‘배회, 침입, 쓰러짐, 싸움, 유기, 방화, 마케팅’ 부문을 모두 통과한 국내 유일의 기술이기 때문입니다. 또한 세계 최대의 3차원 시각 데이터셋(DB)인 싱가포르 난양공대(NTU)의 ‘RGB+D’ 기준 성능평가에서도 94.66%의 행동인식률을 도출할 수 있었습니다. 이를 통해 세계 최고 수준의 이상행동 감지 정확도를 가진 것을 증명할 수 있었습니다. 특히, 안개, 눈, 야간 등 다양한 외부 환경에도 사람의 움직임과 이상행동을 정확히 감지할 수 있다고 하죠.
보안 AI의 한계
보안 인공지능은 현대 사회에서 증가하는 사이버 위협에 대응하기 위해 많은 기업과 조직에서 채택하고 있는 중요한 도구입니다. 그러나 이러한 기술도 자체적인 한계와 도전 과제를 가지고 있습니다. 보안 인공지능의 발전과 함께 우리는 그 한계점을 이해하고 극복하기 위해 지속적인 연구와 개발이 필요함을 알아야 합니다.
한계 1. 기술적인 한계
보안 인공지능은 많은 장점과 혁신적인 기회를 제공합니다. 그러나 기술적인 한계도 여전히 가지고 있습니다.
- 데이터 중독
인공지능 모델은 훈련을 위해 대규모 데이터 세트에 크게 의존합니다. 만약 학습자가 악의적인 의도를 가지고 있거나, 조작된 데이터를 주입할 수 있다면 AI 시스템의 성능과 동작에 영향을 미칠 수 있습니다. 이로 인해 편향되거나 부정확한 결과가 발생하여, 시스템이 취약해지거나 신뢰할 수 없게 됩니다. - 의도하지 않은 결과
AI 시스템은 편견을 포함하거나 사회적 편견을 반영할 수 있는 과거의 데이터를 기반으로 훈련됩니다. 이러한 편견이 적절하게 해결되지 않으면, 인공지능은 차별이나 불공정한 관행을 영속화하여 사회적, 윤리적 문제를 야기할 수 있습니다. - 설명 가능성 부족
딥러닝 신경망과 같은 일부 AI 알고리즘은 매우 복잡하고 해석하기 어려워 ‘블랙박스’라고 불리기도 합니다. 설명 가능성이 부족하면 AI 시스템이 어떻게 결정을 내리는지 이해하기 어려워질 수 있습니다. 이는 잠재적인 보안 위협을 효과적으로 탐지하고 대응하는 능력을 방해할 수 있습니다.
한계 2. 생성 AI의 발전과 맞물린 AI 보안 취약 문제
AI 기술의 발전은 보안 업계에 양날의 검으로 작용하고 있습니다. 특히, ChatGPT와 같은 Generative AI 분야에서 그 영향이 두드러지게 나타납니다. ChatGPT는 보안 취약점을 찾거나 해킹에 활용할 수 있는 소스 코드를 생성하는 등 악용될 수 있는 가능성을 가지고 있습니다.
ChatGPT와 같은 Generative AI 모델은 직접적인 악성 코드 제작법이나 맬웨어 개발과 같은 질문에 대해서는 거부하는 경향이 있습니다. 그러나 프롬프트 엔지니어링 기법을 사용하여 원하는 답변을 얻거나 해킹에 도움이 되는 코드를 생성하려는 해커들의 시도가 빈번하게 발생하고 있습니다. 이 모델들은 명시적인 질문에 대해서만 거부하지만 여전히 해커들의 요구를 우회하여 악용될 수 있는 정보를 생성할 가능성이 남아있기 때문입니다.
따라서 Generative AI의 발전으로 인해 대두된 보안 인공지능 취약 문제는 다음과 같습니다.
- 악성 코드 및 해킹 도구 제작에 활용될 수 있는 정보 생성 가능성
- 프롬프트 엔지니어링과 같은 기법으로 정상적인 질문에서 벗어난 정보 유출 우려
- 반대로 Generative AI 모델 자체가 해결 방법 및 분석 도구로 사용될 가능성
물론 반대로 Generative AI 모델을 해킹 분석 도구로 활용할 수도 있습니다. 이제 많은 국내 보안 기업들도 다양한 방식으로 AI 기술을 활용하기 위해 노력하고 있습니다.
결론: AI에 대해 높은 이해도를 가진 기업만이 보안 인공지능의 취약점을 극복할 수 있습니다.
보안 인공지능의 취약점을 극복하기 위한 하나의 방법으로 최근 ‘AI 레드팀’이 주목 받고 있습니다. 2018년 출범한 Microsoft AI 레드팀은 AI 시스템 취약점을 식별하고 대응하는 방법을 연구하고 있습니다. 2020년에는 산학 협력을 통해서 AI 시스템 위협을 탐지 및 대응, 완화할 수 있는 SW 툴을 구축하는 데에 성공했죠. 같은 해에는 AI 시스템 보안을 자동으로 테스트하는 툴도 오픈소스로 공개했습니다. 올해 초에는 ‘AI 보안 스캐너’를 깃 허브에 공개하면서 왕성하게 활동하고 있습니다.
구글 AI 레드팀은 AI 알고리즘을 정치적 목적으로 악용하지 못하게 하는 프로젝트를 수행하고 있습니다. 마찬가지로 OpenAI 역시 기존 ChatGPT에 탑재된 GPT-3.5 모델이 해킹과 같은 악용에 취약했음을 인식하고, 이를 극복하기 위해 관련 데이터셋과 알고리즘을 수정하고 있습니다. 글로벌 빅테크 기업에서 ‘AI 레드팀’을 운영하는 것은 드라마틱한 일을 해내던 AI라고 해도, 사람의 꾸준한 연구와 개발이 필요하다는 점을 시사하고 있습니다.
보안 AI의 약점과 한계를 극복하기 위해서는 학습 데이터에 대한 이해가 필요합니다. 보안 인공지능은 특히 학습 데이터의 무결성에 많은 영향을 받습니다. 따라서 AI 모델을 학습시킬 때, 데이터의 다양성과 대표성을 고려하여 학습 데이터를 구축하는 작업이 필요합니다. 또한 라벨링된 데이터의 정확성과 일관성을 유지하는 것에 중점을 두어야 합니다.
또한 우수한 보안 인공지능을 구축하기 위해서는 AI 기반 비즈니스 모델에 대한 이해와 협력이 필요합니다. ‘AI 레드팀’처럼, 인공지능에 사람의 손길이 필요하다는 점을 인지하고 전문 인력의 관리와 개발을 이어나가야 합니다. 따라서 보안 인공지능을 제대로 활용하기 위해서는, 새로운 알고리즘과 기술 도입에 추가적으로 대응하여 최신 동향을 반영하고, 보안 위협에 대응하기 위한 AI 모델의 성능과 정확도를 지속적으로 향상시켜야 합니다. 데이터헌트 역시 보안 AI의 무궁무진한 발전을 기대하며 이를 준비하고 있습니다.
'say와 AI 챗봇친구 만들기 보고서' 카테고리의 다른 글
| 인공지능의 시작 챗GPT를 스마트폰과 컴퓨터로 활용하는 방법 (1) | 2023.10.20 |
|---|---|
| 엔비디아 'RTX4090' 품귀…원인은 AI (2) | 2023.10.20 |
| 강화학습, Reinforcement Learning이 궁금하다면? (2) | 2023.10.19 |
| YOLO Object Detection, 객체인식 - 개념, 원리, 주목해야 할 이유, Use Case (1) | 2023.10.19 |
| 보안 AI 인공지능, 활용 사례와 적용 기술 (1) | 2023.10.19 |



