

현대 사회에서 사이버 위협은 기업과 개인의 안전을 심각하게 위협하는 문제로 부상하고 있습니다. 이에 따라 보안 인공지능은 더욱 중요한 역할을 수행하고 있으며, 다양한 산업 분야에서 활용되고 있습니다. 이 글에서는 보안 인공지능이 필요한 이유와 적용된 기술, 실제 적용 사례, 그리고 장점과 한계에 대해 다루어보려 합니다.
보안 AI 인공지능이 필요한 이유
오프라인 위험 대응
보안 인공지능은 오프라인에서 벌어질 수 있는 더 많은 위험에 대응할 수 있습니다. 예를 들어 CCTV 영상을 모니터링하거나 경보에 대응하는 등, 현재 보안 요원이 수행하는 많은 작업을 자동화하는 데에 사용할 수 있습니다. 범죄가 발생할 가능성이 있는 장소와 시간 등 잠재적인 위험을 예측하여 정보를 주기도 하죠. 또한 비즈니스의 특정 요구사항에 맞게 보안 경고를 맞춤 설정하거나, 개인의 위험 프로필에 맞는 보안 조치를 추천받을 수 있습니다.
사이버 보안 위협 대응
최근 오프라인의 위험 뿐만 아니라 사이버 공간에서의 위협도 많은 문제점으로 대두되고 있습니다. 수없이 많은 사이버 보안 위험 사례를 처리하기 위해서는 많은 인력이 필요합니다. 그러나 이것이 가능한 전문 인력이 부족할 경우, 기업별로 보안 격차가 드러날 수밖에 없습니다. 따라서 보안 툴에 AI를 적용하여 확장 가능한 설루션을 구축하면, 이러한 문제점을 극복할 수 있습니다.
또한 위험 자동 탐지나 위험에 대한 자동 대응, 소프트웨어 패치 또는 업데이트 등의 반복적인 작업을 자동화하면 인간의 작업 시간을 축소할 수 있게 됩니다. AI는 대량의 데이터를 실시간 분석하는 데에 특화되어 있기 때문에, 이를 기반으로 인간 분석가보다 더 빠르고 정확하게 잠재적인 위험을 식별할 수 있죠.
👉데이터 관리부터 머신러닝 시스템 개발과 서비스 운영을 하나의 서비스로 제공하는 MLOps란?
MLOps 란? - 정의, 구성요소, 레벨별 프로세스, Use case
MLOps 를 시작하기 위한 A to Z 가이드
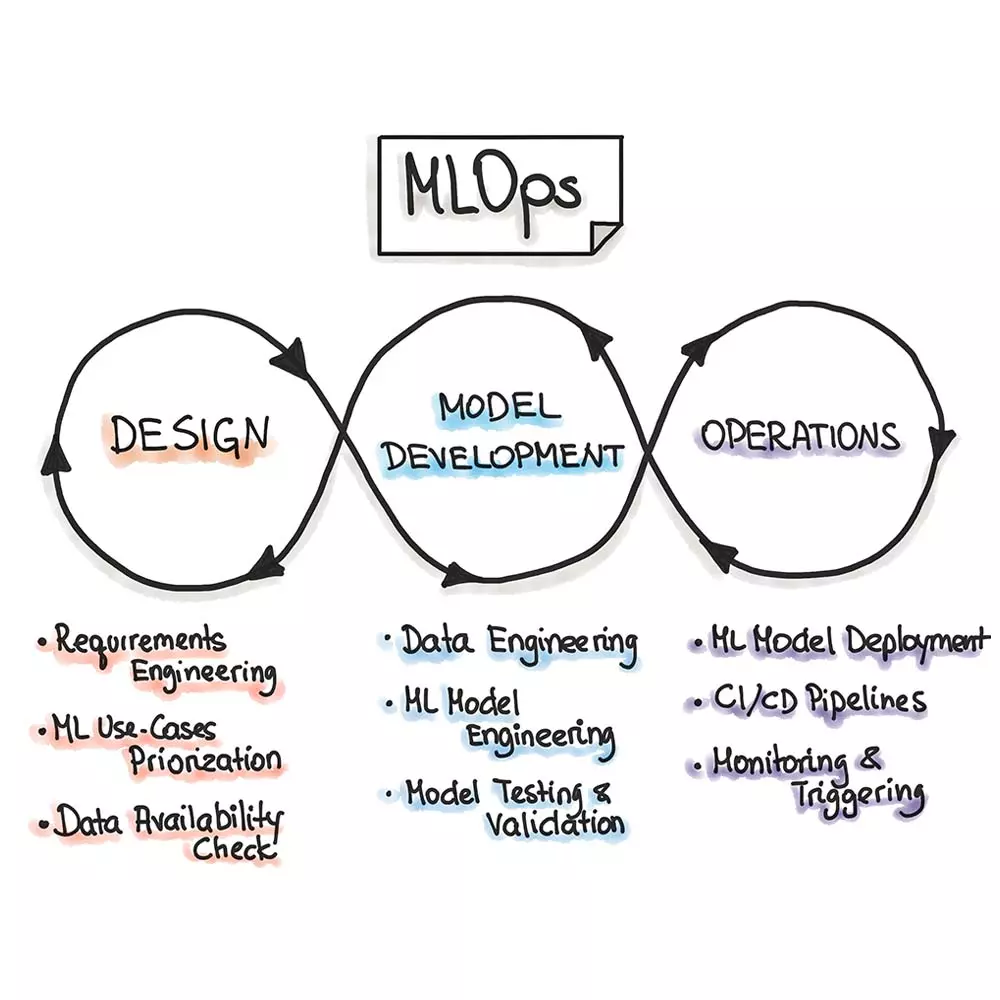
이번 콘텐츠는 MLOps란 무엇이며, 어떻게 구성되어 있는지, 레벨 별로 프로세스는 어떻게 다르며, 어디에 쓰이는지를 총망라해서 정리해 보았습니다.
이후에는 주요 MLOps 플랫폼을 소개하고 비교하는 시간을 가지도록 하겠습니다.
MLOps란 무엇인가?
MLOps 정의
MLOps (Machine Learning Operations)는 Machine Learning, ML과 Operations, Ops의 합성어로, 머신러닝 모델을 안정적이고 효율적으로 배포 및 유지 관리하는 것을 목표로 하는 패러다임입니다. 머신러닝 시스템을 위한 지속적인 통합, 지속적인 배포, 지속적인 학습을 구현하고 자동화하는 기술을 의미합니다.

MLOps는 머신러닝, 소프트웨어 엔지니어링, 데이터 엔지니어링의 분야를 활용하는 엔지니어링 사례를 의미합니다. MLOps는 개발과 운영 간의 격차를 해소하여 머신러닝 시스템을 생산하는 것을 목표로 하죠. 기본적으로, MLOps는 머신러닝 제품의 생성을 촉진하는 것을 목표로 합니다. 이 목표를 위해 자동화, 워크플로 조정, 버전 관리를 수행하는 플랫폼이라고 할 수 있습니다. 이외에도 지속적인 교육 및 평가와 메타 데이터 추적 및 로깅, 지속적인 모니터링과 피드백 루프를 통해 모델 및 코드를 개선하는 과정을 수행합니다.
즉, MLOps는 데이터 과학자와 운영 전문가 간의 협업 및 커뮤니케이션을 통해 아래와 같은 목표를 수행하고자 합니다.
- 배포 및 자동화
- 거버넌스 및 규정 준수
- 확장성
- 협업
- 모니터링 및 관리
- 재현성
MLOps 구성요소
MLOps는 크게 ML(학습) 단계와 Ops(운영) 단계로 나눌 수 있습니다.
ML 단계에서는 데이터 수집, 전처리, 모델 구축, 학습, 평가 등의 과정이 이루어집니다. Ops에서는 ML 단계에서 완성된 모델의 배포, 모니터링, 테스트 등을 수행할 수 있습니다. MLOps는 머신러닝 엔지니어링, 데이터 엔지니어링, 클라우드, 인프라 등을 모두 포함하는 개념이라고 할 수 있죠
머신러닝 시스템을 프로덕션 환경에서 적용 및 운영하기 위해서는 좋은 모델을 구축하는 것이 능사는 아닙니다. 머신러닝 모델이 MLOps 시스템의 핵심이기는 하지만, 보다 거시적인 관점에서 봤을 때 데이터와 인프라를 포함한 모든 시스템이 유기적으로 돌아가는 것이 중요합니다.
MLOps를 다루는 과정에서, 조직은 몇 가지 난관에 부딪힐 수 있습니다.
- 동일한 데이터와 코드를 사용하더라도 머신러닝 실험의 결과를 재현하기 어려울 수 있습니다. 머신러닝 모델은 데이터나 코드의 작은 변경에도 민감하게 반응하기 때문입니다.
- 머신러닝 모델을 훈련하고 평가하기 위해서는 많은 양의 데이터가 필요합니다. 종종 이런 데이터의 수집이나 정리, 준비 과정에서 어려움을 겪기도 합니다.
- 특수 하드웨어와 소프트웨어가 필요한 경우가 많기 때문에, 머신러닝 모델은 프로덕션 환경에 배포하기 어려울 수 있습니다.
- 머신러닝 모델이 예상대로 작동하는지 확인하기 위해 프로덕션 환경에서 모니터링이 필요합니다.
이러한 어려움에도 불구하고 MLOps는 조직이 ML 투자를 최대한 활용할 수 있도록 도와주는 중요한 분야입니다. 조직은 MLOps를 신중하게 계획하고 구현함으로써 ML 모델의 재현성, 신뢰성 및 성능을 개선할 수 있습니다.
단계

따라서, 모든 머신러닝 프로젝트에는 다음과 같은 스텝을 수반해야 합니다.
- Data Extraction (데이터 추출) : 데이터 소스에서 관련 데이터 추출
- Data Analysis (데이터 분석) : 데이터의 이해를 위한 탐사적 데이터 분석(EDA) 수행, 모델에 필요한 데이터 이해
- Data Preparation (데이터 준비) : 데이터의 학습, 검증, 테스트 세트 분할
- Model Training(모델 학습) : 다양한 알고리즘 구현, 하이퍼 파라미터 조정 및 적용하여 학습된 모델 구축
- Model Evaluation (모델 평가) : holdout test set에서 모델을 평가
- Model Validation(모델 검증) : 기준치 이상의 모델 성능 검증 및 배포에 적합한 수준인지 검수
- Model Serving(모델 서빙)
- Model Monitoring(모델 모니터링)
ML Lifecycle을 다루는 내용을 보면, 이름만 조금씩 다를 뿐 위와 같은 내용을 다루고 있다는 것을 알 수 있습니다.
MLOps 레벨별 프로세스
Google은 수동 적용 단계부터, ML과 CI/CD Pipeline을 모두 자동화하는 단계까지 성숙도를 세 단계의 레벨로 나누어서 평가하고 있습니다.
- MLOps 수준 0: 수동 프로세스
- MLOps 수준 1: ML pipeline 자동화
- MLOps 수준 2: CI/CD Pipeline 자동화
MLOps LV 0
MLOps 수준 0 프로세스에서는 데이터 분석과 데이터 준비, 모델 학습 및 검증을 포함한 모든 단계가 수동으로 이루어집니다. 각 단계를 수동으로 실행하고, 한 단계에서 다음 단계로 전환하는 것 역시 수동으로 이루어집니다. 이 단계에서는 ML과 운영이 단절되어 있으며, 이로 인해 학습과 서비스 간의 간극이 발생하기도 합니다. 일반적으로 새 모델 버전은 1년에 두어 번만 배포하며, 프로덕션 환경에서는 권장되지 않는 성숙도입니다.
하지만 MLOps 레벨 0이 완벽하게 나쁜 것은 아니죠. 소규모 프로젝트 또는 내부 용도로 ML 모델을 개발 및 배포하는 데에는 유효할 수 있습니다. 다만 안정성과 확장성이 중요한 프로덕션 환경에서는 적합하지 않을 수 있습니다. 프로덕션 환경에서 더 나은 MLOps가 필요하다는 것을 느꼈다면, 다양한 리소스를 통해 더 높은 성숙도의 MLOps로 성장할 수 있습니다.
MLOps LV 1
MLOps 레벨 1은 머신러닝 실험 단계를 자동화하여 빠르게 실험을 반복하고, 전체 pipeline을 프로덕션으로 전환할 수 있는 준비 상태를 의미합니다. 이 레벨에는 몇 가지 특성이 있습니다.
- 실험-운영 대칭성: 개발 또는 실험 환경에서 사용되는 pipeline 구현이 사전 프로덕션 및 프로덕션 환경에서도 사용됩니다.
- 컴포넌트 및 pipeline을 위한 모듈화된 코드: 컴포넌트의 소스 코드는 모듈화되고 이상적으로는 컨테이너화되어야 합니다.
- 프로덕션 환경의 ML pipeline은 새로운 데이터로 학습된 새로운 모델에 예측 서비스를 지속적으로 제공합니다. 모델 배포 단계는 자동화됩니다.
- 레벨 1에서는 전체 학습 pipeline을 배포하고, 이 pipeline은 자동으로 반복적으로 실행되어 학습된 모델을 예측 서비스로 제공합니다.
간단히 말하자면 MLOps 레벨 1은 머신러닝 실험과 pipeline을 자동화하여 실험을 반복합니다. 또한 프로덕션 환경에서 모델을 학습하고, 배포하는 작업을 더 쉽게 수행할 수 있는 것을 의미합니다.
MLOps LV 2
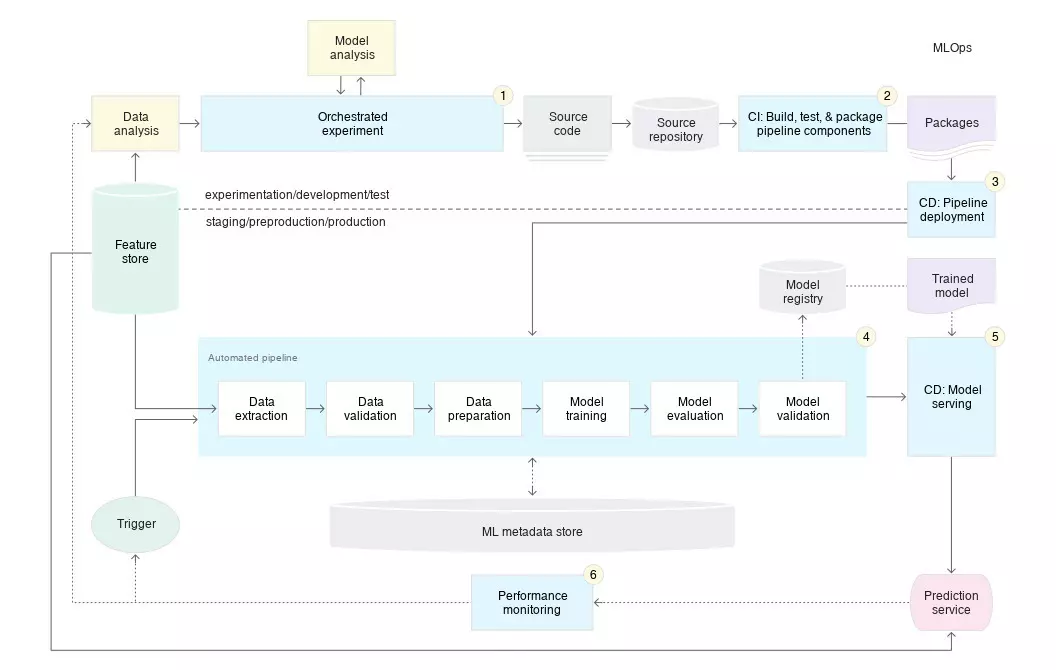
프로덕션 단계에서 Pipeline을 빠르고 안정적으로 업데이트하기 위해서는, 자동화된 CI/CD 시스템이 필요합니다. 이 자동화된 시스템을 사용하면 데이터 과학자가 AI를 개발함에 있어 특성 추출, 모델 아키텍처, 초매개변수에 대한 새로운 아이디어를 빠르게 살릴 수 있습니다.
이 MLOps의 Pipeline 구성 단계를 요약하면 다음과 같습니다.
- 개발 및 실험: 새로운 ML 알고리즘과 모델링 기법을 반복적으로 시도합니다. 이 단계의 결과물은 ML pipeline 단계의 소스 코드이며, 소스 리포지토리에 푸시됩니다.
- pipeline 지속적 통합(CI): 소스 코드를 빌드하고 다양한 테스트를 실행합니다. 이후 단계에서 배포할 pipeline 구성 요소(패키지, 실행 파일 및 아티팩트)을 목표로 합니다.
- pipeline 지속적 배포(CD): CI 단계에서 생성된 아티팩트를 대상 환경에 배포하고, 모델의 새로운 구현이 포함된 pipeline을 출력합니다.
- 자동 트리거링: 일정에 따라 또는 트리거에 대한 응답으로 프로덕션 환경에서 pipeline을 자동으로 실행합니다.
학습된 모델을 배포한 후에는 라이브 데이터를 기반으로 모델 성능에 대한 통계를 수집해야 합니다. 모니터링 결과를 통해, pipeline을 실행하거나 새로운 실험 주기를 찾을 수 있는 계기를 얻을 수 있죠.
프로덕션 환경에서 머신러닝을 구현한다고 해서, 모델이 예측용 API로 배포되는 것은 아닙니다. 대신 새로운 모델이 재학습 및 배포하는 과정을 자동화할 수 있도록 머신러닝 pipeline 배포를 의미합니다. 지속적 통합과 지속적 배포 시스템을 설정하면, 새로운 ML pipeline 구현을 자동으로 테스트하고 배포할 수 있습니다. MLOps 레벨 3에서는 데이터 및 비즈니스 환경의 빠른 변화에 적극적으로 대응할 수 있게 됩니다.
MLOps 비교
MLOps vs. DevOps
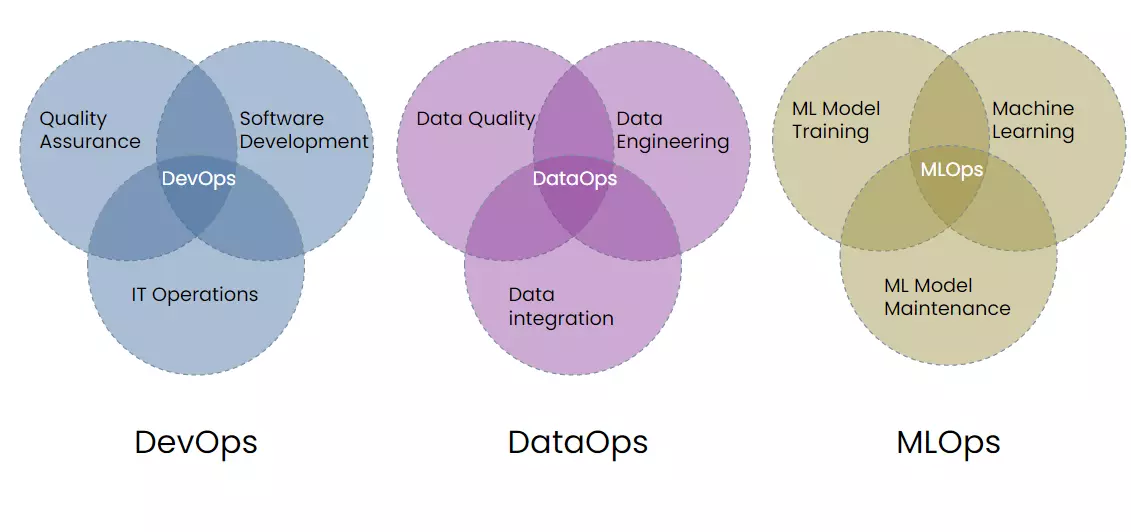
DevOps는 대규모 소프트웨어 시스템 개발 및 운영에 널리 사용하는 방식입니다. 개발 주기 단축, 배포 속도 증가, 안정적인 출시 등의 이점을 가지고 지속적인 통합과 지속적인 배포를 목적으로 합니다.
MLOps의 원칙 자체가 DevOps에서 파생되었기 때문에, 두 개념은 기본적으로 유사합니다. 하지만 실행 방식이 상당히 다릅니다.
- 머신러닝 모델은 지속적으로 업데이트되고 개선되며, 빠르고 쉽게 결과를 재현할 수 있어야 하기 때문에 MLOps는 DevOps보다 실험적입니다.
- MLOps에는 하이브리드 팀이 필요합니다. 머신러닝 프로젝트에는 일반적으로 데이터 분석 및 모델링 전문가인 데이터 과학자와 프로덕션급 소프트웨어 구축 및 배포 전문가인 소프트웨어 엔지니어가 함께 참여하기 때문입니다.
- 머신러닝 모델은 기존 소프트웨어 개발보다 더 복잡하기 때문에, MLOps에서는 더 많은 테스트가 필요합니다.
- 새 버전이 나올 때마다 머신러닝 모델을 수동으로 배포하고 업데이트하는 것은 불가능에 가깝습니다. 따라서 MLOps는 자동화된 배포 과정을 필수로 합니다.
- 프로덕션 환경의 ML 모델은 시간이 지남에 따라 성능이 저하될 수 있습니다. 학습되는 데이터가 변경되거나 모델 자체가 구식이 될 수 있기 때문입니다.
- 모델이 예상대로 작동하는지 확인하고, 문제를 조기에 발견하기 위해 운영 중인 머신러닝 모델은 지속적인 모니터링이 필요합니다.
MLOps vs. LLMOps
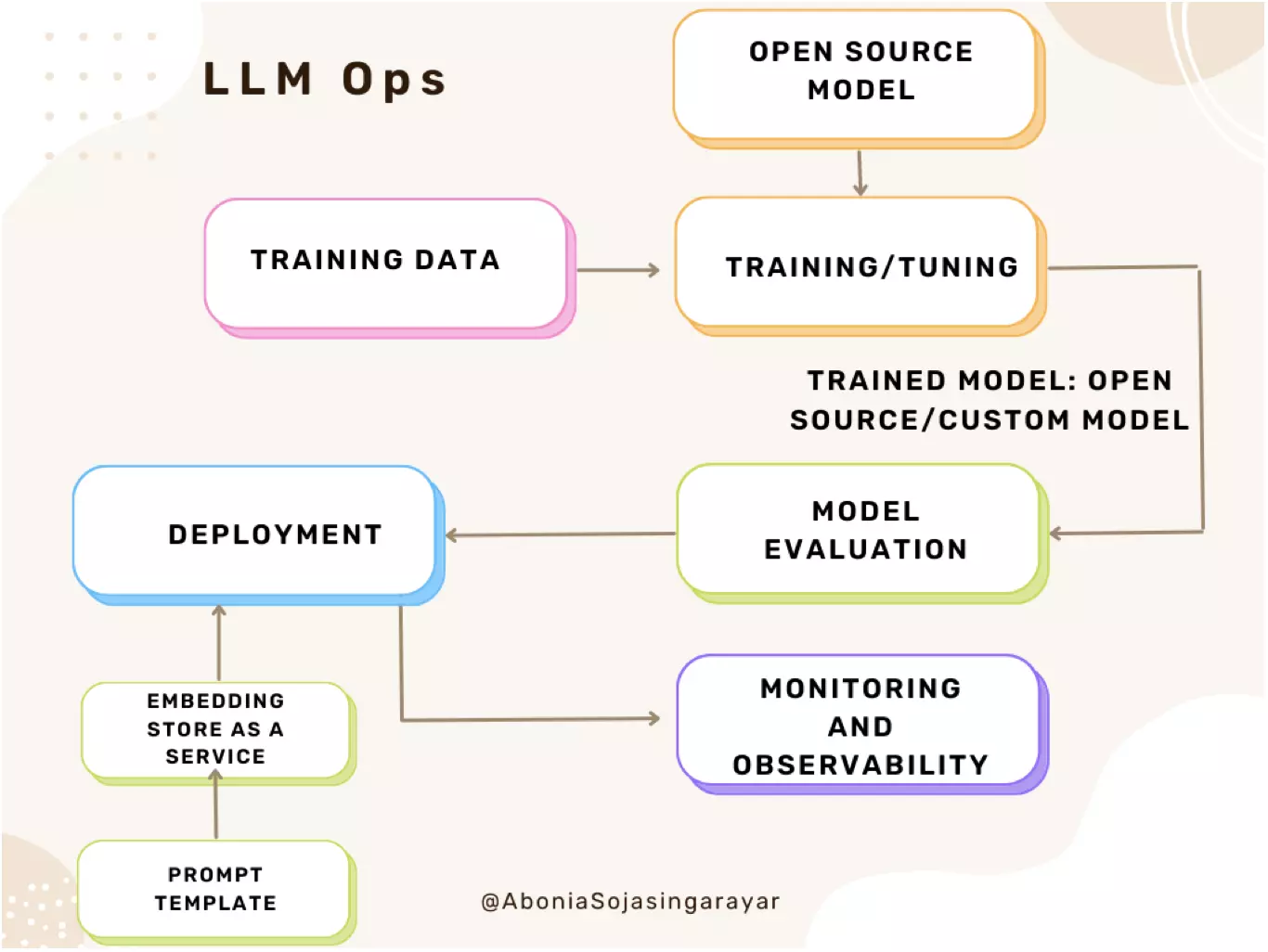
LLMOps (Large Language Model Operations) 이란, 대규모 언어 모델의 훈련이나 조정, 배포 및 모니터링을 위한 MLOps의 확장입니다. LLMOps는 MLOps 접근 방식과는 다소 다른 점이 있습니다.
- 컴퓨팅 리소스: 대규모 언어 모델의 훈련 및 조정을 위해서는 일반적으로 대규모 데이터 세트에 훨씬 더 많은 계산을 수행해야 합니다. 이 프로세스의 속도를 높이려면 더 빠른 데이터 병렬 작업을 수행할 수 있는 특수 하드웨어가 필요합니다.
- 전이 학습 (Transfer learning): 처음부터 새로 생성하거나 훈련하는 머신러닝 모델과는 달리, 대부분의 대규모 언어 모델은 기본 모델에서 시작하여 특정 도메인에서의 성능을 개선하기 위해 새로운 데이터로 세부 조정하는 과정을 거칩니다. 이 과정을 통해 더 작은 데이터와 컴퓨팅 리소스로 특정 애플리케이션의 성능을 극대화할 수 있죠.
- 사람의 피드백: LLM 작업은 매우 개방적이므로 애플리케이션 최종 사용자의 피드백은 LLM 성능 평가에 매우 중요한 지표입니다. LLMOps pipeline으로 이 피드백 루프를 통합하면, 학습한 대규모 언어 모델의 성능을 향상시킬 수 있습니다.
- 초매개변수 조정: 기존 머신러닝에서 초매개변수 튜닝은 정확도 또는 기타 지표 개선에 중점을 두고 있습니다. LLM의 경우, 튜닝은 트레이닝 및 추론의 비용과 컴퓨팅 성능 요구 사항을 줄이기 위함이었죠. 기존 머신러닝과 LLM은 튜닝 프로세스를 추적하고 최적화할 수 있지만, 서로 다른 부분에 목표가 있다는 점이 다릅니다.
- 성능 지표: 기존 모델에도 명확한 성능 지표가 있었고, 매우 간단하게 계산할 수 있었습니다. 그러나 LLM을 평가할 때는 추가적인 구현 고려 사항이 적용됩니다. 예를 들어 BLEU(Bilingual Evaluation Understudy) 및 ROGUE(Recall-Oriented Understudy for Gisting Evaluation) 처럼, 완전히 다른 표준 지표 및 점수가 적용됩니다.
MLOps Use cases
기업 내에 AI를 도입하며 겪는 어려움 중 하나는 머신러닝 모델 교육과 관련이 있습니다. 머신러닝 모델은 데이터 변화에 민감하며, 까다로운 재현 조건을 가지고 있습니다. 연구 당시에는 정상적으로 작동했던 모델이 실제 상용화되는 과정에서 성능이 떨어지는 경우가 발생하죠. 이런 과정을 극복하기 위한 개념이 MLOps입니다. MLOps는 모델 실험 및 개발을 용이하게 하며, 모델 개발부터 배포까지 모든 과정을 하나의 Pipeline으로 연결합니다.
이 글에서는 MLOps를 통해 얻을 수 있는 Business value 세 가지를 소제목으로 사용 사례를 소개합니다.
목적 1. 예측 정확도 최적화
승차 공유 솔루션 우버(Uber) 비즈니스의 핵심은 운전자의 도착 시간이나 위치를 추정하는 것부터, 사용자의 요구와 운전자의 공급에 따라 여행 요금을 결정하는 데에 있습니다. 우버는 ‘미켈란젤로’라는 내부 서비스형 머신러닝 플랫폼을 구축하여 머신러닝 모델을 운영합니다. 이러한 MLops 로드맵은 우버가 데이터 중심의 결정을 내리는 것을 돕습니다.
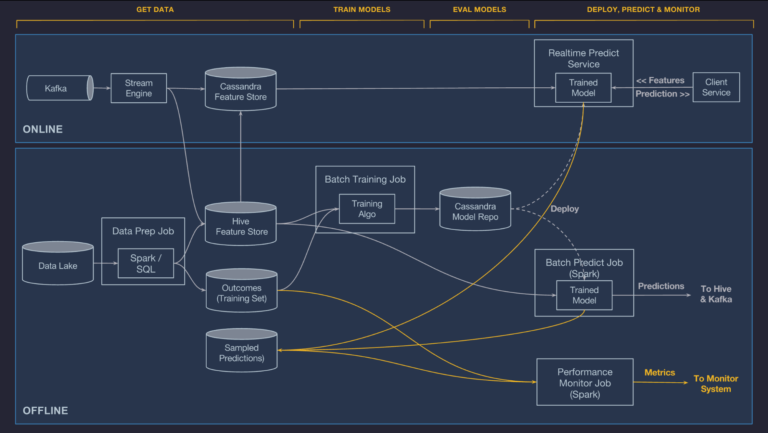
- 온라인/오프라인 예측: 실시간/비실시간 예측을 제공해야 하는 모델에 대해 이 모드를 구현합니다. 예측 서비스는 실시간 추론을 위해 클라이언트의 개별 혹은 일괄 예측 요청을 수락합니다. 또한 배포된 모델은 클라이언트 요청이 있을 때마다, 혹은 반복 일정에 따라 오프라인/배치 예측을 생성할 수 있습니다. 이는 연속적인 데이터 흐름을 파악해야 하는 실시간 서비스 뿐만 아니라 내부 비즈니스 요구에도 유용합니다.
- 모델의 성능 모니터링: 팀 또는 시스템이 이상 징후를 발견할 수 있도록 시간 경과에 따른 메트릭 특성 및 예측 분포를 게시합니다. 데이터 pipeline에서 생성된 관측치에 참여하여, 모델의 예측이 맞는지 여부를 관찰합니다. 또한 모델의 성능을 측정하는 데에 필요한 메트릭을 기반으로 모델의 정확도를 측정합니다. 내부 데이터 모니터링 시스템 Data Quality Monitor(DQM)을 사용하여 규모에 맞게 데이터 품질을 모니터링하기도 합니다.
- 반복 및 모델 수명 주기 관리: 우버는 운영 중인 모델의 라이프사이클을 관리하고, 해당 모델의 성능 및 메트릭을 운영 팀의 경고 및 모니터링 툴에 통합했습니다. 또한 배치 데이터 pipeline, 교육 작업, 배치 예측 작업, 배치 및 온라인 컨테이너 모두에 모델 배포를 조정하는 워크플로우 시스템을 포함시켰습니다.
- 모델 거버넌스: 데이터 및 모델 계통에 대한 감사 및 추적 기능이 포함되어 있습니다. 미켈란젤로는 모델이 실험을 통해 취하는 경로를 확인하고, 모델이 어떤 데이터 세트에 교육을 받았는지 추적하고, 어떤 모델이 특정 비즈니스 사례를 위해 프로덕션에 구현되었는지 이해할 수 있습니다. 또한 이 플랫폼에는 특정 모델의 수명이나 데이터셋 관리에 참여한 다양한 사용자를 확인할 수 있습니다.
넷플릭스에서 머신러닝을 위한 활용 사례는 어렵지 않게 찾을 수 있습니다. 넷플릭스에서 수행하는 대부분의 작업은 개인화를 통해 사용자의 환경을 최적화해야 하는 비즈니스 요구사항을 중심으로 이루어집니다. 예를 들어 회원의 홈페이지를 개인화하고, 볼만한 콘텐츠를 추천해 주는 것과 동시에 각 콘텐츠에 관련이 있을 수 있는 작품을 표시해 주는 것이죠. 핵심은 사용자가 보기 전에 보고 싶은 것을 예측하는 것에 있습니다.
우버와 유사하게 넷플릭스는 온라인 뿐만 아니라 오프라인 모드에서 모델을 배포합니다. 그 외에도 모델이 온라인 예측 서비스에 배치되지만, 실시간 추론을 수행할 필요가 없는 경우도 수행해야 합니다. 이를 통해 온라인 예측 서비스와 더불어 고객 요청에 대한 시스템의 응답성을 높일 수 있죠.

넷플릭스 팀은 머신러닝 모델을 교육하고 데이터를 효과적으로 관리하여 데이터 과학자가 신속하게 실험할 수 있도록 지원합니다. 이를 위해 오픈소스 머신러닝 프레임워크에 구애받지 않는 메타플로우를 구축하고 사용하죠. Metaflow API를 사용하면 머신러닝 워크로드가 AWS 클라우드 인프라 서비스와 원활하게 상호작용할 수 있다는 장점이 있습니다.
이외에도 넷플릭스는 내부 자동 모니터링 및 알림 도구를 사용하여 불량 데이터 품질을 모니터링하고, 데이터 이동을 감지할 수 있습니다. 또한 넷플릭스에서 구현한 ‘Runaway’ 툴은 프로덕션에서 오래된 모델을 모니터링하고, 머신러닝 팀에 경고를 전하기도 합니다. Runaway가 생성한 모델 모니터링 타임라인을 통해 팀은 모델 문제 해결 원인 파악 및 잠재적인 문제를 발견할 수 있습니다.
이외에도 Runaway는 아티팩트 및 모델 계보를 포함한 모델 관련 정보를 추적할 수 있는 저장소를 포함하고 있습니다. 넷플릭스의 개인화 인프라 팀의 수석 소프트웨어 엔지니어인 Liping Peng에 따르면, Runaway는 머신러닝 팀에 모델 구조와 메타 데이터를 검색하고 시각화할 수 있다고 합니다. 즉, 프로덕션 또는 프로덕션에 배포하려는 모델을 쉽게 이해할 수 있는 사용자 인터페이스를 제공하는 것이죠.
목적 2. 프로세스 자동화 및 간소화
1인당 생성 데이터가 증가함에 따라 수집되는 데이터의 양은 기하급수적으로 늘었습니다. 하지만 실제 문제 해결을 위해 머신러닝을 적용하고자 하면 여러 어려움에 부딪히게 됩니다. 머신러닝 엔지니어가 완성된 모델을 전달했을 때, 작업 환경 차이나 패키지 및 구조 이해 등의 문제로 배포 과정에서 새로운 문제를 겪을 수도 있습니다. 이 과정에서 MLOps는 협업 프로세스를 자동화하고 간소화를 가능하게 합니다.
Merck Research Labs는 백신 연구 및 발견을 가속화하기 위해 MLOps를 구현했습니다. 그들은 제약 및 의료 분야에서 머신러닝 기반 혁신을 추진하기 위해 다방면으로 연구하고 있었지만, 여러 문제점을 겪고 있었죠. 장기간 진행된 연구 프로젝트 동안, DevOps 팀과 머신러닝 팀은 단절되어 있었습니다. 원활하지 않은 협업 탓에 기술 불일치와 머신러닝 라이프사이클의 비효율이 대두되고 있었죠. 결국 모델 구축에 필요한 시간과 비용이 모두 증가하는 악순환에 부딪혔습니다.
Merck Research Labs는 MLOps 구축을 통해 이 문제를 해결할 수 있었습니다. 복합 이미지를 자동으로 선별하는 처리 기능을 구현했으며, 정밀한 자동화를 통해 머신러닝 운영을 간소화할 수 있었습니다. 또한 연구자가 선택한 iDE를 자유롭게 사용할 수 있도록 설정하여 기술 제한 문제를 해결했습니다.
MLOps는 CI/CD를 기본으로 한 프로세스 자동화를 가장 기본적인 목적으로 합니다. Continuous Integration은 Code와 Components 뿐만 아니라 데이터, 데이터 스키마, 모델에 대한 테스트와 검증 결과를 요구합니다. Continuous Delivery는 단일 소프트웨어 패키지가 아니라 머신러닝 학습 pipeline 전체를 배포하는 것을 전제로 합니다. MLOps는 이 모든 과정을 하나의 Pipeline 시스템에 구현하는 것을 목표로 합니다.
모바일 소프트웨어 회사인 PadSquad는 글로벌 고객에게 제공하는 광고의 성능을 향상하고자 했습니다. 소비자가 부담하는 미디어 비용을 축소하기 위해 MLOps 플랫폼을 구현했죠. 그들은 AI 개발 세스 효율에 어려움을 겪고 있었으며, 핵심 작업보다 운영에 더 많은 시간을 할애하는 문제를 겪고 있었습니다.
PadSquad가 구현한 자동화된 머신러닝 pipeline은 전체 머신러닝 라이프사이클을 지원하고, 고급 기능 엔지니어링 기능을 보장합니다. 이는 DevOps를 추상화한 결과물이었죠. 결과적으로 MLOps 구현은 그들이 연구에서 배포까지, AI 애플리케이션 개발 프로세스를 간소화하는 데에 결정적인 역할을 했습니다.
특히 머신러닝 개발 및 배포와 관련된 운영 측면을 자동화하는 데에 큰 도움을 받았습니다. PadSquad 소속 데이터 과학자들은 비즈니스 로직에 집중할 수 있게 되었죠. 더 빠른 GTM을 구현할 수 있었으며, 더 나은 경험과 참여로 향상된 광고 성과를 이룩했습니다.
👉 대표적인 MLops 비교 분석
MLOps 비교 - SageMaker, Kubeflow, MLflow, WandB, Tensorflow Extended
MLOps 플랫폼 분석 및 비교

마지막 MLOps 가이드인 정의, 구조, 레벨화된 프로세스 및 사용 사례 콘텐츠에 이어 주요 MLOps를 소개하고 장단점을 비교해 보겠습니다.
MLOps를 사용해야 하는 이유
MLOps 채택의 이점
MLOps는 기계 학습, DevOps 및 데이터 엔지니어링의 조합입니다. 사람, 프로세스, 기술을 통합하여 프로덕션 환경에서 기계 학습 시스템을 배포하고 관리하는 데 도움을 줍니다. 새로운 분야임에도 불구하고 최근에는 많은 조직에서 관심이 높아지고 있습니다.
MLOps를 채택한 조직이 얻을 수 있는 이점은 다음과 같습니다.
- 속도 및 효율성 향상: MLOps는 조직 전체에서 사용할 수 있는 표준화된 프로세스 및 도구 세트를 제공합니다. 이를 통해 기계 학습 개발 및 배포 프로세스의 속도와 효율성을 높일 수 있습니다 .
- 향상된 품질 및 안정성: MLOps는 모델을 지속적으로 모니터링하고 테스트할 수 있으며 프레임워크 와 새 모델을 프로덕션에 배포하는 프로세스를 자동화할 수 있습니다. 이는 기계 학습 모델의 품질 과 안정성을 향상시키는 데 큰 도움이 될 수 있습니다 .
- 비용 절감: 조직은 기계 학습 개발 및 배포와 관련된 비용을 줄일 수 있습니다. 개발 프로세스를 간소화하고 수동 개입의 필요성을 줄이면 기계 학습 배포를 더 쉽게 확장할 수 있기 때문입니다.
- MLOps는 기계 학습 수명 주기에 관련된 모든 사람을 위한 공통 프레임워크를 제공합니다. 이를 통해 데이터 과학자, 엔지니어, 운영팀 등 조직 내 여러 팀 간의 협업을 개선하는 데 도움이 될 수 있습니다.
- 기계 학습 수명 주기에 대한 더 나은 가시성을 통해 문제를 더 일찍 식별하고 해결할 수 있습니다. 이는 더 나은 모델 성능과 위험 감소로 이어집니다.
- 지속적인 모니터링 및 감사를 위한 프레임워크를 통해 기계 학습 시스템의 보안을 강화할 수 있습니다. MLOps는 중요한 데이터를 보호하고 기계 학습 시스템에 대한 무단 액세스를 방지하는 데 도움이 됩니다.
MLOps를 채택해야 할 시기인 이유
1인당 생산되는 데이터의 양은 기하급수적으로 증가하고 있습니다. 생성되는 데이터의 양이 증가함에 따라 전통적인 기계 학습 접근 방식을 압도적으로 생각하는 사람들의 수도 늘어나고 있습니다. MLOps는 이 상황에 대한 최상의 설루션입니다.
실시간 의사결정에 대한 필요성도 점점 커지고 있습니다. 오늘날의 조직은 실시간으로 의사결정을 내릴 수 있어야 합니다. 이러한 결정을 지원하는 기계 학습을 구축하려면 기계 학습 팀이 빠르고 쉽게 배포할 수 있는 모델을 제공해야 합니다. CI/CD(지속적 통합 및 배포)를 위한 프레임워크를 제공함으로써 MLOps를 채택하는 조직은 실시간 통찰력에 더 빠르게 대응할 수 있습니다.
지금 MLOps를 채택하면 어떤 조직이 가장 큰 혜택을 얻을 수 있나요?
- MLOps는 데이터 기반 조직에서 기계 학습 모델을 더욱 쉽게 구축, 배포, 관리할 수 있도록 하여 데이터에서 더 많은 가치를 얻을 수 있도록 해줍니다.
- MLOps는 기계 학습 모델 관리를 위한 확장 가능하고 안정적인 프레임워크를 제공합니다. 따라서 기계 학습 배포를 확장하려는 조직에 큰 도움이 될 수 있습니다.
- MLOps는 표준화된 프로세스 및 도구 세트를 제공합니다. 조직의 비즈니스가 실시간 의사 결정을 기반으로 하거나 더 빠르고 효율적인 기계 학습 모델을 제공해야 하는 경우 MLOps를 채택해야 합니다.
많은 경쟁업체가 이미 MLOps를 채택하고 이를 사용하여 경쟁 우위를 확보하고 있습니다. 아직 MLOps를 사용하고 있지 않다면 오늘 채택하는 것이 좋습니다. MLOps는 데이터에서 더 많은 가치를 얻고, 기계 학습 모델을 빠르고 효율적으로 사용할 수 있도록 지원하며, 모델 배포를 확장할 수 있는 좋은 기회를 제공합니다.
MLOps 플랫폼 비교
아마존 세이지메이커
Amazon SageMaker는 Amazon Web Service(AWS) 퍼블릭 클라우드의 관리형 서비스입니다. 예측 분석 애플리케이션을 위한 기계 학습 모델을 구축, 교육 및 배포하는 데 도움이 되는 도구를 제공합니다. 이러한 통합 도구는 노동 집약적인 수동 프로세스를 자동화하는 동시에 인적 오류와 하드웨어 비용을 줄이는 이점이 있습니다.

AWS SageMaker는 기계 학습 모델링을 준비, 훈련, 배포의 3단계로 단순화합니다.
- AI 모델 준비 및 구축: Amazon SageMaker에는 데이터 세트를 훈련하기 위한 다양한 기계 학습 알고리즘이 함께 제공됩니다. 여기에는 감독되지 않은 기계 학습 알고리즘도 포함됩니다. 이를 통해 모델의 정확성, 규모 및 속도를 향상시킬 수 있습니다.
- 훈련 및 튜닝: 모델 훈련을 수행하는 개발자는 Amazon S3 버킷의 데이터 위치와 선호하는 인스턴스 유형을 지정한 다음 훈련 프로세스를 시작합니다. SageMaker는 알고리즘을 최적화하기 위해 매개변수와 하이퍼 매개변수를 찾는 자동 모델 튜닝을 제공합니다.
- 배포 및 분석: 모델을 배포할 준비가 되면 클라우드 인프라를 자동으로 운영하고 확장하세요. SageMaker는 배포 및 모니터링, 보안 패치 적용, AWS 자동 크기 조정, 앱 연결을 위한 HTTPS 엔드포인트 등을 수행할 수 있습니다. 개발자는 생산 성능 변화를 추적하고 Amazon CloudWatch 지표에서 경보를 트리거할 수 있습니다.
AWS SageMaker는 다양한 산업 분야에서 활용됩니다. SageMaker Studio의 자동화 도구는 사용자가 기계 학습 모델을 자동으로 디버그, 관리 및 추적하는 데 도움이 됩니다. 150개 이상의 사전 구축된 설루션을 사용하면 모델을 빠르게 구현하고 기계 학습 워크플로를 개선할 수 있습니다.
구글 큐브플로우
프로덕션급 솔루션을 구축할 때 조직은 여러 가지 복잡한 문제에 직면합니다. 예를 들어 교육 및 평가를 위한 파이프라인을 설정하는 데 많은 시간을 소비할 수 있습니다. 기계 학습 모델의 실험 및 버전 관리를 추적하는 것은 리소스 집약적일 수 있으며 기계 학습 구성 요소의 출력을 추적하고 재현하는 데 어려움을 겪을 수 있습니다.
Google Cloud의 Kubeflow는 머신러닝 시스템 구축을 위한 오픈소스 도구 키트입니다. Kubeflow는 비용과 시간을 줄이기 위해 머신러닝 워크플로를 구축하는 데 특화되어 있습니다. 이 플랫폼은 기계 학습 파이프라인을 구축하고 실험하려는 데이터 과학자를 위해 설계되었지만 프로덕션 등급 서비스를 위해 다양한 환경에서 기계 학습 시스템을 개발하고 테스트해야 하는 엔지니어와 운영 팀에게도 효율적입니다.
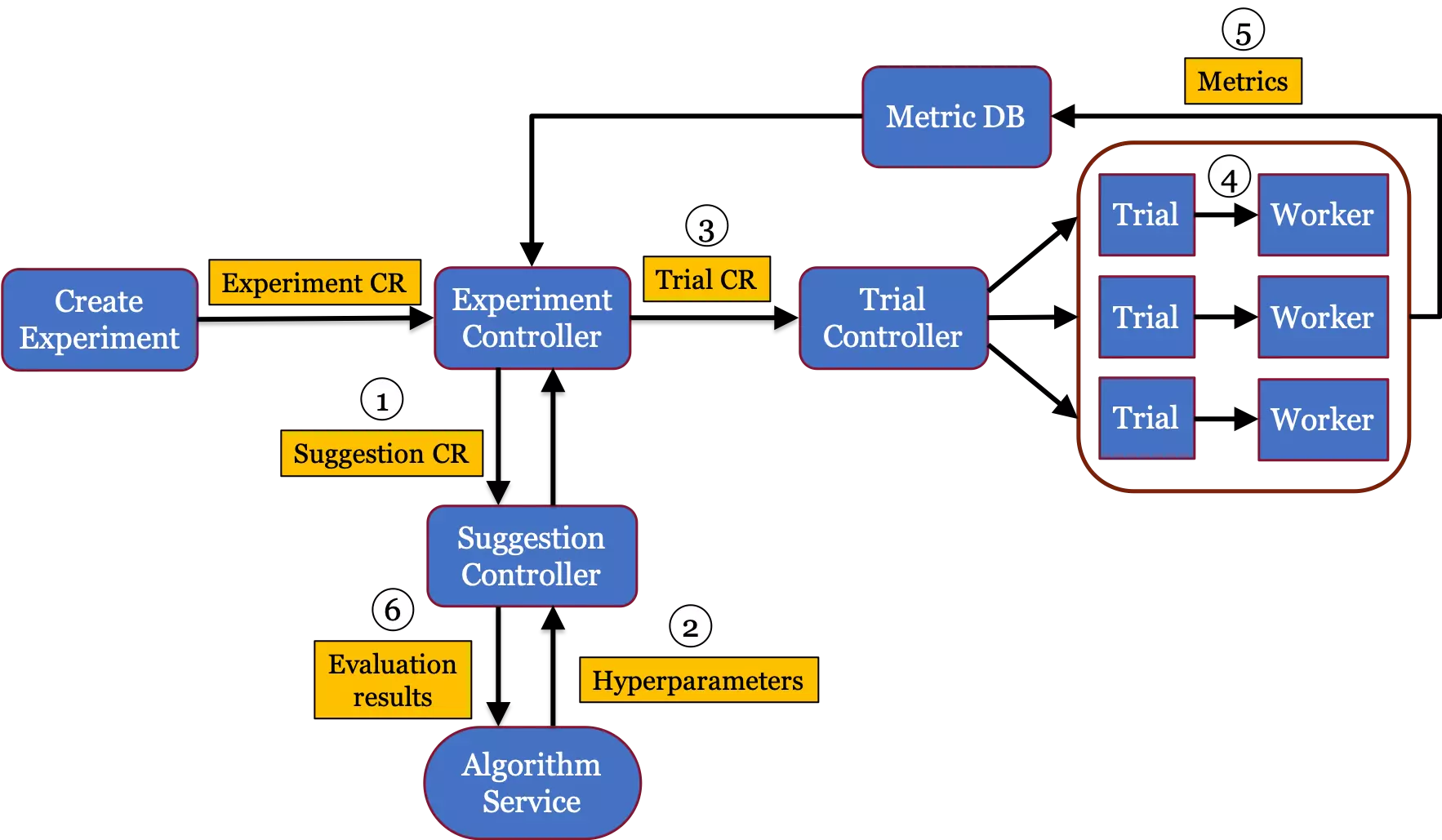
다음은 Kubeflow 플랫폼을 사용하면 얻을 수 있는 이점입니다.
- 대규모로 기계 학습 시스템 배포 및 관리: Kubeflow의 핵심 사용자 여정(CUJ)은 엔드투엔드 워크플로를 위한 소프트웨어 솔루션입니다. 즉, 모델을 쉽게 구축, 교육, 배포, 개발하고 파이프라인을 생성, 실행 및 탐색할 수 있습니다. .
- 머신러닝 모델을 통한 학습 및 실험: Kubeflow는 모델 학습을 위한 안정적인 소프트웨어 하위 시스템을 제공합니다.
- 엔드 투 엔드 하이브리드 및 멀티 클라우드 기계 학습 워크로드: Kubeflow는 하이브리드 및 멀티 클라우드 이식성에서 기계 학습 모델을 개발해야 하는 요구 사항을 충족합니다.
- 훈련 중 모델 초매개변수 조정: 초매개변수 조정은 모델 성능 및 정확도를 통해 수행됩니다 . Kubeflow에서는 자동화된 초매개변수 튜너(Katib)를 사용하여 이를 쉽게 수행할 수 있습니다. 이는 계산 시간을 줄일 뿐만 아니라 모델 개선을 위한 시간과 리소스도 절약합니다.
- 머신러닝을 위한 지속적 통합 및 배포(CI/CD): Kubeflow Pipelines를 사용하면 재현 가능한 워크플로를 만들 수 있습니다.
하지만 Kuberflow는 네임스페이스 공간인 Kubernetes 환경을 관리하고 유지하는 역할을 담당합니다. 이는 일부 조직에서는 어렵고 복잡할 수 있습니다. 또한 Kubeflow를 기존 인프라에 통합할 때 조직에서는 사용하던 도구가 Kubeflow와 호환되지 않는다는 사실을 발견하는 경우가 많습니다.
모든 MLOps는 특정 솔루션을 적용하기 전에 조직의 요구 사항과 기능을 신중하게 평가해야 합니다.
MLflow
MLflow는 엔드투엔드 ML 수명주기를 관리하기 위한 오픈 소스 플랫폼입니다. MLflow는 라이브러리 및 언어에 구애받지 않으며 클라우드를 포함한 모든 환경에서 동일하게 작동합니다. 오픈 소스이기 때문에 확장성이 뛰어나며 조직이 1명이든 1,000명 이상이든 상관없이 유용하도록 설계되었습니다. MLflow 플랫폼은 MLflow 추적, MLflow 프로젝트, MLflow 모델 및 MLflow 모델 레지스트리 구성 요소로 구성됩니다.
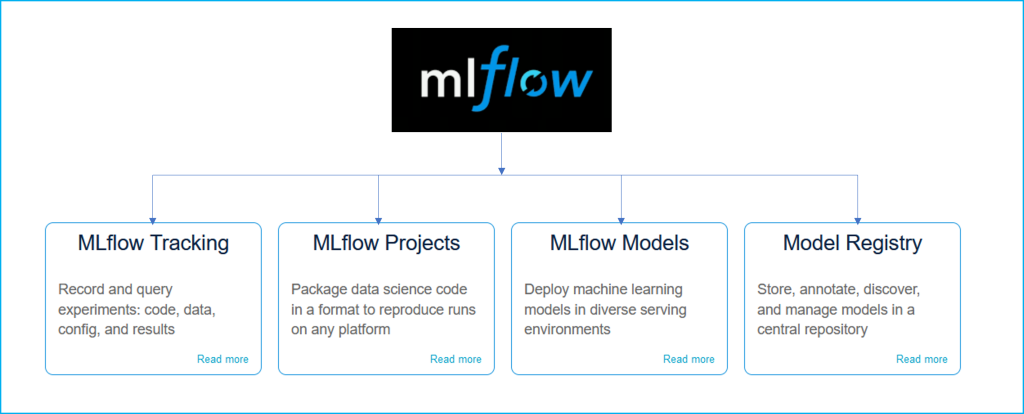
mlflow의 주목할만한 기능은 다음과 같습니다.
- MLflow 추적 : 실험 기록을 추적하고 매개변수와 결과를 비교합니다.
- MLflow 프로젝트 : ML 코드를 재사용 및 재구현 가능한 형식으로 패키징하여 다른 데이터 과학자와 공유하거나 프로덕션으로 이동합니다.
- MLflow 모델 : 다양한 ML 라이브러리로 생성된 모델을 관리하고 다양한 모델 제공 및 추론 플랫폼에 배포합니다.
- MLflow Registry : 중앙 모델 저장소를 제공하여 단일 MLflow 모델의 전체 수명주기를 공동으로 관리합니다. 이러한 관리 작업에는 모델 버전 관리, 모델 단계 전환 및 주석이 포함됩니다.

MLflow는 모델을 훈련하고 재현한 후 다양한 도구(Tensor flow, Scikiy-Learn..)를 사용하여 모델이 입력을 받으면 추론 결과를 다양한 환경(Docker, Spark, Kubenetes..)에 배포하는 표준 역할을 합니다. 정해진 양식.
- ML 모델에 대한 패키징 형식 제공: ML 모델 파일이 있는 모든 디렉터리를 사용할 수 있습니다.
- 재현성을 위한 종속성 정의: ML 모델 구성에서 Konda 환경과 같은 종속성에 대한 정보를 제공할 수 있습니다.
- 모델 생성 유틸리티: 모든 프레임워크의 모델을 MLflow 형식으로 저장합니다.
- 배포 API: CLI/python/R/Java 등 배포 API를 제공합니다.
텐서플로우 확장
Tensor Flow Extension(TFX)은 TensorFlow를 기반으로 하는 Google의 프로덕션 규모 머신러닝 플랫폼입니다. TensorFlow Extension 파이프라인은 확장 가능하고 재현 가능한 머신러닝 워크플로를 구축하기 위한 도구라고 합니다. 여기에는 데이터 변환 및 처리, 기능 추출, 모델 교육, 성능 평가 등을 수행하는 구성 요소가 포함됩니다. TFX 파이프라인의 기본 구성요소 중 하나는 데이터 전처리, 탐색, 모니터링에서 중요한 역할을 하는 TensorFlow 데이터 검증(TFDV)입니다.
TensorFlow 확장 기능:
- TensorFlow Extension을 사용하면 Apache Airflow, Apache Beam, Kubeflow Pipelines와 같은 여러 플랫폼에서 기계 학습 워크플로를 조정할 수 있습니다.
- TensorFlow Extension은 머신러닝 훈련 스크립트의 일부로 사용할 수 있는 표준 구성요소 세트입니다. 여기에는 쉬운 프로세스 구축을 가능하게 하는 기능이 포함되어 있습니다. 또한 고급 작업을 수행하거나 기계 학습 실험을 모델링, 교육 및 관리하는 데 도움이 되는 기계 학습 파이프라인을 구현하기 위한 구성 요소도 포함되어 있습니다.

TFDV는 데이터 세트를 탐색, 시각화 및 정리하는 데 필수적인 기능을 제공합니다. 데이터를 검사하여 데이터 유형, 범주 및 범위를 자동으로 추론하여 이상값과 누락된 값을 식별하는 데 도움을 줍니다. 또한 데이터 세트를 이해하는 데 도움이 되는 시각화 도구를 제공하여 패턴, 이상값 및 잠재적인 문제를 더 쉽게 찾아낼 수 있습니다. 훈련된 스키마 및 통계에 대해 수신 데이터를 지속적으로 평가함으로써 TFDV는 잠재적인 데이터 문제에 대해 경고하거나 새 데이터에 대한 모델을 재훈련해야 함을 나타낼 수 있습니다.
WandB - 가중치 및 편향
WandB, Weights and Biases는 "개발자가 더 나은 모델을 더 빠르게 구축할 수 있게 해주는 ML 플랫폼"입니다. 하이퍼 매개변수 조정, 데이터 세트 및 모델 버전 관리, 교육 모니터링을 지원하고 클라우드에서 실험을 관리하는 편의성을 제공합니다.

WandB는 5가지 주요 기능을 제공하여 ML 수명주기를 단순화하고 ML 엔지니어의 삶을 더 쉽게 만드는 엔드 투 엔드 MLOps 플랫폼입니다.
- 실험: 기계 학습 모델 실험을 추적하기 위한 대시보드입니다.
- 아티팩트 : 데이터 세트 버전 관리 및 모델 버전 관리.
- 테이블 : W&B로 시각화하고 쿼리하기 위해 데이터를 기록하는 데 사용됩니다.
- Sweeps : 하이퍼 매개변수를 자동으로 조정하여 최적화합니다.
- 보고서 : 실험을 문서화하고 공동작업자와 공유합니다.
위의 5가지 기능을 사용하면 여러 사람과 협업하고 프로젝트를 효율적으로 관리할 수 있습니다. 또한 여러 프레임워크와 결합할 수 있어 확장성이 높다는 장점도 있습니다. 이번 글에서는 모델을 훈련하면서 모델 훈련 로그를 추적하고 이를 대시보드에 시각화하는 실험을 소개하겠습니다. 이를 통해 훈련이 잘 진행되고 있는지 빠르게 확인할 수 있습니다.
올바른 MLOps 플랫폼을 선택하는 방법
각 플랫폼에는 고유한 장단점이 있으므로 올바른 플랫폼을 선택하기 전에 세부 사항을 자세히 살펴보는 것이 좋습니다.
아마존 세이지메이커
장점
- 자체 컴퓨팅 리소스(인스턴스) 제공
- 다양한 기능 제공
- Autopilot - 표 형식 데이터에 대해 다양한 모델을 자동으로 찾고 학습하여 최적의 모델을 도출하는 서비스입니다.
- Canvas - 제공하는 모델을 사용하여 모델을 쉽게 배우고, 시각화하고, 공유할 수 있게 해주는 서비스
- 명확화 - 설명 가능한 AI(XAI) 기술을 활용하여 데이터의 각 속성이 결과에 어떤 영향을 미쳤는지 쉽게 이해할 수 있습니다.
- 사용자 편의성 향상을 위해 노코드, 로우코드 수준에서 다양한 기능 제공
- 잘 작성된 문서
- 많은 예제가 포함된 자세한 문서
- AWS의 다른 서비스와 쉽게 통합
- AWS는 약 70%의 지배적인 한국 시장 점유율을 보유하고 있습니다(기사). 너무 많은 서비스가 AWS 생태계에 의존하기 때문에 SageMaker는 다른 MLOps 서비스에 비해 호환성이 가장 높기 때문에 쉽게 사용할 수 있고 선호됩니다.
- 데이터 세트 구축을 포함한 MLOps 전체 패키지
- SageMaker Ground Truth는 플랫폼 내에서 데이터 구축도 제공합니다.
단점
- EC2, S3, ECR 등 AWS 시스템에 대한 이해 필요
- AWS를 처음 사용하는 경우 EC2, S3, ECR과 같은 AWS의 다른 서비스와 IAM과 같은 개념에 익숙해져야 합니다.
- 상대적으로 비싸다
- 자체 인스턴스를 제공하지만 비용이 많이 들 수 있습니다. 예를 들어, NVIDIA V100이 8개 포함된 p3.16xlarge 인스턴스의 경우 시간당 약 28달러가 청구됩니다(가격표 참고: 자체 서버를 구입하는 경우 손익분기점은 약 3~4개월입니다).
구글 Kubeflow, Vertex AI
장점
- 자체 컴퓨팅 리소스 제공(GCP)
- SageMaker보다 사용 가능한 컴퓨팅 리소스에 대한 더 많은 옵션
- 다양한 기능 제공
- Vertex AI Matching Engine - 대규모 확장성과 짧은 지연 시간을 갖춘 벡터 검색 서비스
- Vertex explainable AI - SageMaker Clarify와 마찬가지로 XAI 기술을 통해 모델 및 데이터 분석이 가능합니다.
- Generative AI Studio - PaLM 2, Imagen, Codey 등을 포함한 Google의 최신 세대 모델에 즉시 액세스하고 쉽게 배우고 배포할 수 있습니다.
- 이전에 Google에서 관리하던 오픈소스 Kubeflow는 TFX 도입을 통해 기존 MLOps 사용자에게 비교적 친숙해졌습니다.
- 평균적으로 SageMaker보다 비용이 저렴함( 문서 )
- 잘 작성된 문서
단점
- 모델 배포 시 작은 통신 패킷 크기 제한으로 인해 고해상도 이미지나 긴 오디오 파일을 처리하기가 어렵습니다.
- 사용하지 않을 때에도 발생하는 기본 비용이 있으므로 매우 가벼운 서비스는 다른 플랫폼보다 비용이 많이 들 수 있습니다.
MLflow
장점
- 플랫폼이 아닌 오픈 소스 라이브러리, 배우기 쉽고 사용이 간편함
- 훈련 설정, 실험 결과 등 정보를 깔끔하게 시각화합니다.
- 무료
단점
- 클라우드를 활용하지 않기 때문에 오케스트레이션이 필요하지 않습니다.
- 오케스트레이션(Orchestration)이란 작업에 필요한 리소스를 자동으로 조정 및 할당하고, 클라우드 컴퓨터의 비정상 종료 등 리소스에 문제가 발생할 경우 자동으로 새로운 리소스를 할당하고 환경을 구성하는 것을 의미합니다.
- 보안 설정을 다양화할 수 없음
- 하나의 프로젝트에서도 구성원마다 다른 접근권한을 부여해야 하는 경우는 처리할 수 없습니다.
- 추가 컴퓨팅 리소스 필요
완드 B
장점
- Python에서 약간의 추가 코드로 높은 유용성
- 훈련 설정, 실험 결과 등 정보를 깔끔하게 시각화합니다.
- 서비스 시작 선택권 제공
- 서비스가 제공되는 클라우드(프리미엄)에서 서비스를 사용하거나, 자신의 컴퓨터에서 서비스를 시작할 수 있습니다.
단점
- 제한된 사용: Python에서만 사용 가능
- 모델 배포 기능을 제공하지 않습니다.
MLOps 플랫폼 도입 시 고려해야 할 사항
초기 데이터 품질 설계
MLOps 도입을 고려하고 있다면 설계 초기에 데이터 품질을 고려해야 합니다. 데이터 품질이 중요한 이유는 다음과 같습니다.
- 데이터 품질이 좋지 않으면 모델의 의사결정 능력에 부정적인 영향을 미칩니다. 또한, 눈에 띄지 않는 문제는 잘못된 결론으로 이어질 수 있으며 문제를 해결하는 데 비용과 자원을 낭비할 수 있습니다. 궁극적으로 이해관계자의 신뢰는 부정적인 영향을 받을 수 있습니다.
- 소비자가 인식하는 데이터 품질 문제를 해결하려는 시도는 팀의 시간을 낭비하고 생산성과 사기를 서서히 저하시키는 근본적인 문제가 될 수 있습니다.
이는 낮은 데이터 품질이 기계 학습 모델 개발과 운영 팀 모두에 부정적인 영향을 미칠 수 있기 때문입니다.
데이터헌트의 관점
모델 데이터는 MLOps의 완성도에 큰 영향을 미치므로 데이터 품질부터 준비까지 모든 작업을 수행하고 있는지 확인하는 것이 중요합니다. DataHunt는 기계 학습 수명 주기 전반에 걸쳐 인공 지능을 활용하여 고품질 MLOps를 구축하는 데 도움을 줄 수 있습니다. 이 프로세스는 데이터 품질에 대한 세심한 평가, 입력 데이터 분석으로 시작되며, 설계 단계에서 철저함을 원칙으로 합니다.

DataHunt는 어떻게 99% 정확도의 고품질 데이터를 구축했나요?
- 국내 최초 AI 보조 주석 : 국내 최초 AI를 접목한 HITL(Human in the loop) 데이터 처리 서비스 출시
- AI 자동 라벨링을 통해 다른 프로젝트보다 2배 빠르게 프로젝트 제공: AI 기반 라벨링을 자동화하여 프로젝트 시간을 최대 2배 단축합니다.
- 업계 최고의 정확도: AI 기술, 다중 검증 프로세스, 차별화된 처리 인력으로 구현되는 업계 최고의 99% 이상의 데이터 정확도
- 최고 수준의 개발 및 운영 인력 : 카카오, 쿠팡, IBM, LG 등 IT 기업의 핵심 인재와 B2G/B2B 프로젝트 경험이 풍부한 운영 인력으로 구성된 개발 인력.
DataHunt는 서비스 2년 차에 1,000만 건이 넘는 데이터 처리 및 구축 사례를 남겼습니다. 또한 2022년에는 AI 학습을 위한 4개의 NIA 데이터 구축 프로젝트에도 참여했습니다. 4년 연속 데이터 바우처 제공업체로 2020년 모범 사례로 선정되는 영예를 안았습니다. 다양한 국가 지원 사업 경험을 통해 우리는 매년 성장하는 회사로 성장했습니다.
요약: MLOps 플랫폼을 채택할 때 초기 데이터 설계에 대해 내려야 할 중요한 결정이 있습니다.
- MLOps를 사용하면 기계 학습 모델을 더 쉽게 구축, 배포, 관리할 수 있으며 안정적인 프레임워크를 구성해야 할 때 큰 이점을 얻을 수 있습니다.
- 전 세계적으로 경쟁력 있는 MLOps 플랫폼을 분석할 때 이들 플랫폼은 모두 전체 워크플로/프로세스를 중앙 집중화하는 능력, 결과 재현성, 배포, 모니터링 및 테스트의 용이성을 공통적으로 갖고 있습니다.
- 완전한 MLOps를 구축하려면 초기 데이터를 올바르게 얻는 것이 중요합니다. 열악한 데이터 품질은 이해관계자의 신뢰를 약화시키고 모델 개발 및 모니터링 중에 비용과 자원을 낭비합니다.
목적 3. 고객 경험 향상

홀리데이 엑스트라(Holiday Extra) 머신러닝의 핵심적인 용도는 타깃 맞춤 광고를 통한 고객 경험 개인화, 서비스 가격 자동화, 통화 처리 자동화와 같은 고객 의사 결정 최적화입니다. 홀리데이 엑스트라 머신러닝의 모델 배포 및 확장 과정은 다음과 같습니다.
- 머신러닝 모델을 개발하기 위한 코드가 쿠키 커터로 구성, 템플릿화되어 회사의 Github 저장소로 푸시
- 모델링 라이브러리는 Scikit-learn을 사용
- 데이터 변환은 모델 코드 내에 사용자 지정 트랜스포머를 사용하여 사이킷 학습 pipeline을 구성 - Github로 저장된 모델 코드는 Google 클라우드 스토리지(GCS)로 복제하고, AI 플랫폼을 사용하여 모델을 학습
- 모델 파일과 메타 데이터가 GCS로 반환
- 모델 평가 후, AI 플랫폼은 올바른 데이터 스키마로 호출할 수 있는 엔드포인트로 예측 서비스를 제공 - 머신러닝 프록시로 클라이언트의 요청을 인터페이스
- 이는 AI 플랫폼이 예상하는 데이터 스키마를 정의하여 다른 서비스가 예상 데이터 스키마로 엔드 포인트를 쿼리할 수 있도록 설계 - 데이터 과학 팀은 라이프사이클 관리에 대한 승인 프로세스가 처리될 수 있도록 협력
- 거버넌스를 위해 Google AI Platform에서 모을 추적할 수 있도록, 모든 교육과 성능 세부 정보 및 버전을 관리합니다.
인도의 스타벅스는 데이터 중심 전략을 적용하여 매출을 향상했습니다. 통합 데이터 및 분석 플랫폼을 사용하여 다양한 채널에서 로열티 데이터를 수집하고 분석했죠. 스타벅스 인디아는 마이크로세그먼트의 마케팅 분석을 통해 지출 패턴에 따른 고객층을 식별했습니다. 이에 따라 구매를 반복할 수 있는 고객층을 찾아냈죠.
데이터 중심의 충성도 전략 프로그램을 통해, Starbucks india는 목표로 하는 캠페인에서 더 높은 수익을 얻을 수 있었습니다. 또한 고객 이탈 감소 효과와 더불어, 사전 보존에 도움이 되는 비활동 트리거를 탐색할 수 있었죠.
MLOps 프로세스를 구현하기 전 고민해야 할 과제는?
성공적인 MLOps를 구현하기 위해서는 왜 이 과정이 필요한 것인지에 대한 고민이 필요합니다. 즉, 비즈니스 목표에 따른 구현을 계획할 필요가 있습니다.
구글은 MLOps 성숙도에 따라 단계를 나누었습니다. MLOps의 가장 궁극적인 모습은 2단계의 모습이지만, 모든 조직에 해당하는 것은 아닙니다. 위에서 언급했듯 소규모프로젝트 또는 내부 용도로 머신러닝 모델을 개발/배포할 경우 레벨 0도 유효할 수 있습니다. 또한 새로운 머신러닝 모델을 개발하기보다는, 새 데이터 기반의 모델을 배포하는 것이 익숙한 그룹에게는 레벨 1이 적합합니다. 따라서 다른 사용자가 설루션을 구현한 방식을 마냥 따라 하는 것보다는 필요한 결과에 맞게 최적화할 수 있도록 계획하는 것이 필요합니다.
단순히 데이터를 수집하고 저장하기 위해 MLOps를 구축하는 것은 비효율적일 수 있습니다. 플랫폼 설계에 앞서, 데이터 품질에 대해 먼저 생각할 필요가 있습니다. 귀사의 데이터 품질 평가 프로세스를 점검하고, 입력 데이터의 변경 기점을 조사해 볼 필요가 있습니다.
또한 본격적인 MLOps 구현 전에, 파일럿 설루션을 위해 단순한 것부터 시작하는 것이 좋습니다. 가능한 한 빨리 엔드 투 엔드 pipeline을 구축한다면 좋겠지만, 먼저 관리형 서비스를 통해 시간과 노력, 비용을 절감하는 것이 효과적일 수 있습니다. MLOps는 기본적으로 인프라가 중요하기 때문에, 전문 공급업체와 협업을 통해 관리형 서비스를 시작하면 팀은 시스템 다루는 것에 익숙해질 뿐만 아니라 생산성 향상에 집중할 수 있습니다.
데이터헌트는 그동안 MLOps 구축 사례를 분석하면서 다양한 케이스를 연구해 왔습니다. 도구와 기술 계획뿐만 아니라, 비용 효율적인 MLOps 구축을 위해 적극적으로 커뮤니케이션하고 있습니다. 중앙 집중화된 워크플로우와 추적 가능한 프로세스를 희망한다면, MLOps를 위한 데이터라벨링 전문 기업 데이터헌트와 상의해 보실 것을 권합니다.
요약
- MLOps는 개발과 운영을 따로 나누지 않고, 생산성 및 안정성을 최적화하기 위한 DevOps를 머신러닝 시스템에 적용한 것입니다.
- MLOps는 총 3단계로 나눌 수 있으며, LV 2의 경우 CI/CD의 자동화를 통해 모델의 학습과 배포, 모니터링 과정을 하나의 Pipeline에서 수행하는 것을 목표로 합니다.
- MLOps를 구축하기 위해서는 이를 무조건적으로 복제하기 보다는 나의 비즈니스 환경에 맞게 구체적인 설계 과정을 거쳐 파일럿 솔루션을 제작하거나, 전문 공급업체와 협업을 통해 관리형 서비스를 시작하는 것을 권장합니다.
보안 AI 활용 기술
그렇다면 보안 인공지능에는 어떤 기술이 적용되고 있을까요?
- 통계적 분석 (Statistical analysis)
AI는 시스템 또는 네트워크의 사용자 활동 패턴을 분석하여 정상적인 동작과 비교합니다.
이를 위해 대량의 데이터가 필요하며, 일반적으로 평균, 표준편차, 분산 등의 통계적 지표를 사용하여 정상 범위를 설정합니다.
그런 다음 실시간으로 들어오는 데이터와 비교하여 이상 혹은 비정상적인 패턴을 감지합니다. - 머신러닝 (Machine learning)
AI 모델은 사전에 학습된 데이터를 기반으로 이상 행위를 탐지하는 데 사용됩니다.
예를 들어, 로그인 패턴, 파일 액세스 패턴, 네트워크 트래픽 패턴 등과 같은 데이터로 모델이 학습됩니다.
학습된 모델은 새로운 입력 데이터에 대해 예측을 수행하고, 이러한 예측 결과에서 이상한 동작을 식별합니다. - 심층 학습 (Deep Learning)
딥 러닝은 다층 신경망을 사용하여 복잡한 패턴 인식과 분류 작업을 수행합니다.
데이터의 다양한 특징과 패턴을 자동으로 학습하고, 이를 기반으로 이상 행위를 탐지합니다.
예를 들어, 신경망은 네트워크 트래픽 데이터를 입력으로 받아 정상적인 패턴을 학습하고, 새로운 데이터에서 이와 다른 패턴을 감지하여 이상 행위로 분류할 수 있습니다.
오프라인 보안 활용 기술
현대의 보안은 크게 온라인과 오프라인 상황으로 구분할 수 있습니다. 예를 들어, 오프라인 보안에 활용되는 기술은 사람보다 더 빠르고 정확하게 물리적인 위험을 감지하고 대응할 수 있게 합니다.
- 동작 기반 감시 (Behaviour-based surveillance)
AI는 시스템의 사용자나 애플리케이션의 동작을 실시간으로 모니터링하여 이상 행위를 탐지할 수 있습니다.
예를 들어, 특정 프로세스가 예상되는 동작 패턴을 벗어나거나, 비인가된 시스템 변경이 감지될 경우 AI 시스템은 이를 이상 행위로 판단하고 경고 또는 차단 조치를 취할 수 있습니다. - 얼굴, 물체 및 이벤트 인식 (Facial, Object, and Event Recognition)
아무리 영상을 잘 녹화하더라도 사건 발생 중이나 발생 후 특정 이벤트, 사물 또는 사람을 식별하는 것은 매우 어려운 일입니다. 바로 이 점이 AI 보안 및 감시 솔루션이 필요한 이유죠. 이러한 설루션은 얼굴, 사물, 이벤트를 쉽게 인식할 수 있을 뿐만 아니라 실시간 전달과 사전 예방적 보안을 촉진합니다.
이외에도, AI를 적용한 보안 솔루션은 얼굴이 없는 상태에서도 인식할 수 있습니다. 예를 들면 키, 성별, 혹은 옷이나 자세와 같은 사람의 신체적 특징을 가지고 사람을 식별하는 것이죠. 또한 활동 패턴을 인식하여 안전한 환경을 장려하면서, 범죄나 비정상적인 행동이 발생하는 것을 감지할 수 있습니다.
'say와 AI 챗봇친구 만들기 보고서' 카테고리의 다른 글
| 강화학습, Reinforcement Learning이 궁금하다면? (2) | 2023.10.19 |
|---|---|
| YOLO Object Detection, 객체인식 - 개념, 원리, 주목해야 할 이유, Use Case (1) | 2023.10.19 |
| ChatGPT를 넘어, 생성형 AI(Generative AI)의 미래 – 1, 2편 (2) | 2023.10.19 |
| 챗GPT가 메신저가 되고, 메타가 이모티콘 공짜로 만들어 주면 ‘카카오의 운명은’? (강정수 박사) (1) | 2023.10.18 |
| [스타트업 IP] 당신의 아이디어, 지식재산(IP)의 가치는 얼마일까? (1) | 2023.10.18 |



