
AI 어시스턴트 개인화를 위한 뤼튼의 첫 걸음


2023 상반기 출시 예정
사용자 의도를 파악해 최적의 서비스에 연결합니다.
대화를 분석해 최적화된 서비스를 제공합니다.

지메일

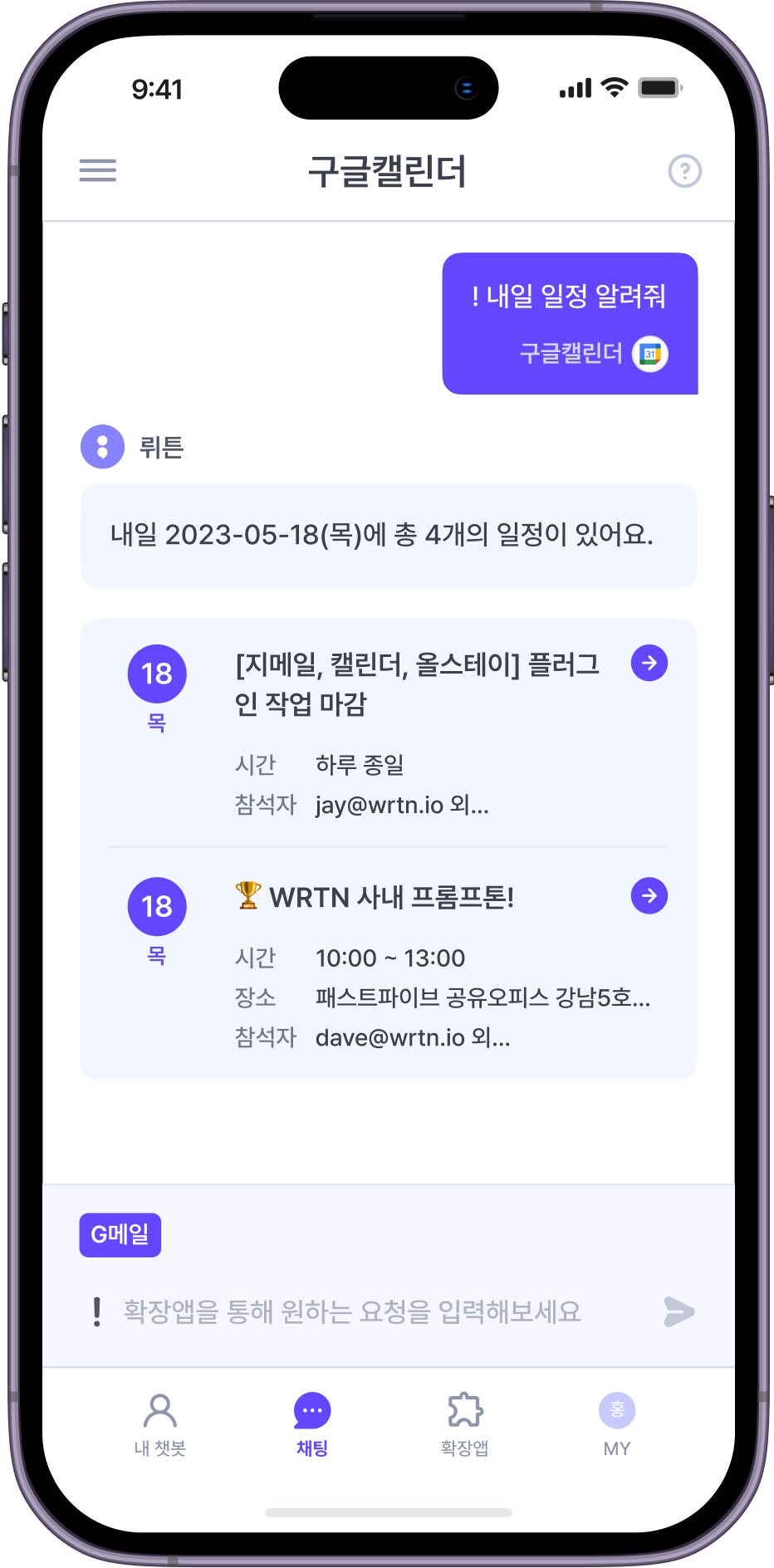
구글캘린더

언제 어디서나
당신의 생산성을 최대로
숙박부터 액티비티까지, 모든 여정을 함께하세요.
뤼튼과 여행의 문을 열고 새로운 경험을 만끽해보세요.
DBPIA

원티드

당신의 가치를 높이는
유능한 파트너
필요한 논문부터 최신 논문까지 한 눈에 확인하세요.
당신의 성공적인 구인구직 뤼튼과 함께하세요.


올스테이

성공적인 여행을 위한
최고의 플래너
빠르게 메일을 찾고 필요한 내용을 요약하세요.
캘린더로 당신의 일정을 체계적으로 관리하세요.
뤼튼 플러그인과 함께하는
서비스를 소개합니다.
지식
디비피아
부동산
직방
의료
닥터나우
강남언니
이커머스
G마켓
11번가
금융
하나은행
KB 금융그룹
홈쇼핑
신세계 라이브쇼핑
구인구직
프리모아
원티드
맛집 검색
식신
뷰티
아모레퍼시픽
패션
라포랩스
숙박
올스테이
행사 / 이벤트
온오프믹스
법률
로앤굿
교육/강의
유데미
원티드
건강
플랜핏
여행
마이리얼트립
모빌리티
타다
뤼튼 플러그인
개인화된 AI 어시스턴트를 위한 뤼튼의 첫 걸음
뤼튼 사용법, 뤼튼(Wrtn) AI, 무료 챗GPT-4
뤼튼(Wrtn)은 인공지능 기술을 이용하여 자동으로 다양한 종류의 콘텐츠를 생성하는 도구입니다. 블로그, SNS, 제품 설명서, 광고, 유튜브, 이력서 등 다양한 분야에서 사용할 수 있는 한국형 챗GPT-4 기반으로 하는 AI 챗봇입니다.
뤼튼이란?
뤼튼(Wrtn)은 인공지능 기술을 이용하여 자동으로 다양한 종류의 콘텐츠를 생성하는 툴입니다. SNS, 유튜브, 광고, 제품설명서, 요리 레시피, 등 다양한 분야에서 사용할 수 있습니다. 뤼튼은 최신 자연어 처리 기술과 딥러닝 알고리즘을 활용하여, 인간 수준의 글쓰기 능력을 자동화하는 것이 가능해졌습니다.
예를 들어, 블로그 포스트를 작성할 때, 뤼튼을 사용하면 기본 틀과 주요 내용을 설정하면 뤼튼이 대부분의 글을 작성해 주어 시간과 노력을 절약할 수 있습니다. 또한, 뤼튼에서 생성된 글을 기반으로 필요한 부분을 수정하고 추가하여 완성도 높은 내용을 만들 수 있으며, 이를 통해 더욱 창의적인 작업에 집중할 수 있게 되었습니다.

뤼튼
뤼튼 사용법
- 뤼튼 웹사이트에 접속하기(뤼튼 웹사이트에 접속하여 회원가입을 하고 로그인을 합니다.)
- 내용 생성하기 (새로운 콘텐츠를 작성하기 전에, 어떤 종류의 내용을 필요로 할는지 선택합니다. 키워드나 주제를 입력하고, 몇 개의 내용을 생성할지 선택합니다.)
- 뤼튼 생성하기('뤼튼 생성하기' 버튼을 클릭합니다. 뤼튼은 몇 분 후에 자동으로 내용을 생성하여 알려줍니다.)
- 결과 확인하기(만족스러운 결과물이라며, 다운로드하고 사용합니다. 만약, 추가적인 수정이 필요하다면, 뤼튼에서 생성된 글을 기반으로 필요한 부분을 수정 또는 추가하여 완성도 높은 내용을 만듭니다.

뤼튼의 장점 및 결론
뤼튼은 사용하면 짧은 시간 내에 다양한 종류의 콘텐츠를 생성할 수 있습니다. 여러 가지 글쓰기 능력과 기술이 필요한 작업을 쉽게 처리할 수 있고, 이를 통해 브랜드 혹은 제품의 마케팅 효과를 높일 수 있습니다. 또한, 뤼튼 앱을 사용하면 작업에 소요되는 시간과 노력을 줄일 수 있어, 효율적으로 작업을 처리할 수 있으며, PC뿐만 아니라 스마트폰 앱을 사용하면 시간과 장소에 구애받지고 사용할 수 있습니다.

뤼튼은 챗GPT-4를 기반으로 한국형 챗봇으로 보다 완성도 높은 한글화 작업을 할 수 있으며 기존에 챗GPT-4를 사용하기 위해서는 유료요금제를 사용해야 가능했지만 뤼튼을 사용하면 무료로 사용할 수 매우 큰 장점을 가지고 있어 꼭 사용하시기를 강력 추천합니다.
|
마감
2023 예비창업패키지 사업계획서 지원금 최대 1억 원 사업화 창업진흥원 |
|
마감
2023 생애최초 청년창업 지원사업 사업계획서 사업화자금 최대 7천만원 사업화 창업진흥원 |
|
마감
2023 초기창업패키지 사업계획서 지원금 최대 1억 원 사업화 창업진흥원 |
|
마감
2023 창업도약패키지 사업계획서 지원금 최대 3억 원 사업화 창업진흥원 |
|
마감
2023 창업중심대학 예비창업자 사업계획서 사업화자금 최대 1억 원 사업화 창업진흥원 |
|
마감
2023 창업중심대학 초기창업자 사업계획서 사업화자금 최대 1억 원 사업화 창업진흥원 |
|
마감
2023 창업중심대학 도약기 사업계획서 사업화자금 최대 3억 원 사업화 창업진흥원 |
|
마감
2023 데이터바우처 사업계획서 지원금 최대 6천만원 사업화 한국데이터산업진흥원 |
|
마감
2023 혁신바우처 사업계획서 5천만 원 이내 바우처 성장 중소벤처기업진흥공단 |

|
한글 자연어 처리 관련 공식 문서는 어떤게 있나요?
|
|
한글 자연어 처리 관련 공식 문서로는 다음과 같은 것들이 있습니다.
|
|
공식 문서 이외에도 한글 자연어 처리 예제나 실습 자료 추천해주세요.
|
|
한글 자연어 처리 예제나 실습 자료로는 다음과 같은 것들이 있습니다.
|
|
한글 자연어 처리를 처음 배우는 입문자를 위한 쉬운 예제를 추천해주세요.
|
|
한글 자연어 처리를 처음 배우는 입문자를 위한 쉬운 예제로는 다음과 같습니다.
from konlpy.tag import Okt okt = Okt() text = "아버지가 방에 들어가신다." morphs = okt.morphs(text) print(morphs) 위 ��드의 결과로는 text에서 추출된 형태소들이 출력됩니다. morphs 변수의 값을 출력하면, ['아버지', '가', '방', '에', '들어가신다', '.'] 와 같은 리스트 형태로 출력됩니다. 이 예제는 한글 형태소 분석의 기초 중 하나인 형태소 추출을 다룬 것입니다.
from konlpy.tag import Okt okt = Okt() text = "아버지가 방에 들어가신다." pos = okt.pos(text) print(pos) 위 코드의 결과로는 text에서 추출된 형태소들과 이들의 품사가 출력됩니다. pos 변수의 값을 출력하면, [('아버지', 'Noun'), ('가', 'Josa'), ('방', 'Noun'), ('에', 'Josa'), ('들어가신다', 'Verb'), ('.', 'Punctuation')] 와 같이 리스트형태로 출력됩니다.
from keras.models import Sequential from keras.layers import Dense, LSTM, Embedding, Dropout from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences import numpy as np # 학습 데이터 docs = ["그 영화는 정말 재밌어요!", "그 영화는 이제 질려요.", "이 영화관은 좋아요.", "이 상영 시간은 항상 좋지 않아요."] # 0: 부정, 1: 긍정 labels = np.array([1, 0, 1, 0]) # Tokenizer를 이용한 단어 토큰화 및 정수 인코딩 t = Tokenizer() t.fit_on_texts(docs) vocab_size = len(t.word_index) + 1 print(vocab_size) X_encoded = t.texts_to_sequences(docs) # 패딩 처리 max_len = max(len(l) for l in X_encoded) X_train = pad_sequences(X_encoded, maxlen=max_len, padding='post') # 모델 생성 model = Sequential() model.add(Embedding(vocab_size, 4, input_length=max_len)) model.add(LSTM(32)) model.add(Dropout(0.5)) model.add(Dense(1, activation='sigmoid')) # 모델 컴파일 및 학습 model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) model.fit(X_train, labels, epochs=50, verbose=2) # 새로운 문장으로 예측 new_sentence = ['이 영화는 좋지 않았어요.'] new_sentence_encoded = t.texts_to_sequences(new_sentence) new_sentence_padded = pad_sequences(new_sentence_encoded, maxlen=max_len, padding='post') print(model.predict(new_sentence_padded)) 위 코드는 Keras와 TensorFlow를 이용한 간단한 한글 감성 분석의 예제입니다. 코드를 실행 후 "이 영화는 좋지 않았어요."를 입력하면, [0.2745269] 와 같이 예측 결과의 부정적인 정도를 ���타내는 값을 확인할 수 있습니다. |
|
초보자를 위한 한글 자연어 처리 핵심 예제는 무엇인가요?
|
|
한글 자연어 처리를 처음 접하는 초보자가 핵심적으로 이해해야 하는 예제는 다음과 같습니다.
|
|
한글 형태소 분석 예제
|
|
한글 형태소 분석을 위해 KoNLPy 라이브러리를 사용하는 예제 코드입니다. 다음은 "나는 밥을 먹었다" 라는 문장을 형태소 분석하여 단어를 분리하고, 각 단어의 품사를 태깅하는 예제입니다.
python from konlpy.tag import Okt okt = Okt() text = "나는 밥을 먹었다" words = okt.morphs(text) # 형태소 분석 tags = okt.pos(text) # 품사 태깅 print(words) print(tags) 위 코드를 실행하면 다음과 같은 결과가 출력됩니다. ['나', '는', '밥', '을', '먹었다'] [('나', 'Noun'), ('는', 'Josa'), ('밥', 'Noun'), ('을', 'Josa'), ('먹었다', 'Verb')] 위 예제에서는 Okt 객체를 생성한 후, morphs()와 pos() 메소드를 사용하여 형태소 분석과 품사 태깅을 수행합니다. 각각의 메소드는 입력된 문장을 형태소 단위로 분리하고, 각 형태소에 대한 품사 태그를 부착합니다. 반환값은 각각 리스트와 튜플 형식으로 되어 있으며, 리스트의 각 항목은 문장을 이루는 단어 또는 형태소를 나타냅니다. 튜플은 (형태소, 품사) 형식으로 되어 있습니다. 예제를 통해 얻은 정보를 활용하여 다양한 자연어 처리를 수행할 수 있습니다. |
|
형태소 분석 라이브러리는 어떤 것이 있나요?
|
|
한글 형태소 분석은 다양한 라이브러리를 사용할 수 있습니다. 몇 가지 주요 라이브러리는 다음과 같습니다.
|
|
한글 형태소 분석기를 이용한 실제 적용 사례를 알려주세요.
|
|
한글 형태소 분석기는 다양한 분야에서 활용됩니다. 그 중 몇 가지 예시를 들면 다음과 같습니다.
|
|
한글 형태소 분석기를 이용한 실제 적용 사례를 알려주세요.
|
|
한글 형태소 분석기는 다양한 분야에서 활용됩니다. 그 중 몇 가지 예시를 들면 다음과 같습니다.
|
|
김형태소 분석기의 성능을 향상시키기 위해서는 어떤 방법이 있을까요?
|
|
형태소 분석기의 성능을 향상시키기 위해서는 다양한 방법을 적용할 수 있습니다. 그 중에서도 대표적인 방법 몇 가지를 소개합니다.
|
|
형태소 분석기 성능을 위한 협업 프로젝트는 어떻게 진행될 수 있을까요?
|
|
형태소 분석기의 성능을 높이기 위한 협업 프로젝트는 다음과 같이 진행될 수 있습니다.
|
|
사용자가 직접 추가하는 단어나 문장은 어떻게 처리되나요?
|
|
한글 형태소 분석기는 보통 내장 사전을 가지고 있어서, 그 내부에서 분석을 수행합니다. 따라서 기존 사전에 등록된 단어나 문장만 분석이 가능합니다. 하지만 사용자가 직접 추가한 단어나 문장은 기존 사전에 없는 단어이거나, 의미가 변경된 기존 단어일 수 있습니다. 이 경우에는 사용자 정의 사전을 사용하면 대처할 수 있습니다. 사용자 정의 사전이란, 한글 형태소 분석기 내에 직접 단어를 추가해 주는 것입니다. 여기서 단어란, 실질적으로 토큰단위의 단어를 의미합니다. 토큰단위란 최소 의미 단위로, 일반적으로는 단어가 됩니다. 사용자 정의 사전은 두가지로 대개 구분됩니다. 하나는 온라인 서비스를 제공하는 경우 사용자가 직접 등록하는 방식이고 다른 하나는 로컬에서 프로그램으로 직접 등록하는 방식입니다. 사용자가 직접 등록을 하면 단어를 추가하거나 삭제, 품사를 지정할 수 있습니다. 사용자가 추가한 단어와 문장은 기존 사전에 없는 단어이므로, 분석기가 사용자가 지정한 대로 처리하게 됩니다. 따라서 사용자가 분석하고자 하는 문서에 맞춰서 사용자 정의 사전을 연구하고 추가하는 것이 좋습니다.
|
|
단어나 문장 추가 기능이 제공되는 형태소 분석기가 있나요?
|
|
네, 단어나 문장 추가 기능이 제공되는 형태소 분석기는 많이 있습니다. 대표적인 한글 형태소 분석기인 KoNLPy(코엔엘파이)에서도 사용자 정의 사전을 추가할 수 있습니다. 사용자가 직접 원하는 단어나 표현을 추가할 수 있고, 이를 이용하여 KoNLPy 내에서 제공하는 형태소 분석기 중 하나인 Okt(Open Korea Text)에서도 추가한 단어를 포함하여 분석할 수 있습니다. 그 외에도, Komoran(코모란)이나 Hannanum(한나눔) 등의 한글 형태소 분석기에서도 사용자 사전 추가 기능을 제공하고 있습니다. 이들 형태소 분석기는 오픈소스로 개발되어 있어, 개발자나 사용자가 직접 소스 코드를 수정하여 사용자 정의 사전 기능을 추가할 수도 있습니다. 또한, 최근에는 구글의 '구글 코랩'에서 제공하는 파이썬 라이브러리 중 하나인 'KoBERT'(코버트)에서도 사용자 정의 사전 기능을 제공합니다. 이를 이용하면 사전에 등록되지 않은 신조어나 상투어, 도메인별 용어 등을 추가하여 형태소 분석의 정확도를 높일 수 있습니다. 따라서, 여러 형태소 분석기에서 사용자 정의 사전 추가 기능을 제공하고 있으니, 사용자의 목적과 요구 사항에 맞게 적합한 분석기를 선택하여 사용할 수 있습니다.
|
|
사용자 정의 사전 등록 방법을 알려주세요.
|
|
사용자 정의 사전 등록 방법은 형태소 분석기마다 조금씩 다를 수 있지만, 대부분의 경우 다음과 같은 방법으로 등록할 수 있습니다.
|
|
형태소 분석기에서 사용자 사전 이외에도 추가적인 기능이 있나요?
|
|
네, 형태소 분석기에는 사용자 사전 이외에도 다양한 기능이 있습니다.
|
|
형태소 분석기에서 제공하는 기능은 무엇인가요?
|
|
형태소 분석기에서 제공하는 기능은 다음과 같습니다.
|
|
형태소 분석 이외의 추가적인 기능은 무엇이 있나요?
|
|
형태소 분석 이외의 추가적인 기능은 다음과 같습니다.
|
|
형태소 분석으로 작성된 시/노래 가사 분석도 가능한가요?
|
|
네, 형태소 분석으로 작성된 시/노래 가사분석이 가능합니다. 시나 가사는 문장 형태로 작성된 경우가 많아, 형태소 분석을 통해서 각 단어들을 분리하고, 각각의 단어가 가진 품사와 의미 정보를 추출할 수 있습니다. 이를 통해 각 단어의 역할과 문장 전체의 구성을 분석하고, 여러 가지 기술, 키워드, 노래 주제 등을 파악할 수 있습니다. 또한, 감성 분석 기능을 추가하여 감정을 분석하는 것도 가능합니다. 예를 들어, 노래 가사의 경우 각 단어의 긍정/부정/중립적인 감성을 판별하고, 이를 기반으로 전반적인 감정상태를 판별할 수 있습니다. 따라서, 형태소 분석을 통해 다양한 구성 요소와 정보를 파악하고, 이를 기반으로 문학 작품의 시각적 분석, 의미 분석 등 다양한 분석을 할 수 있습니다.
|
|
자연어 처리 기술로 무엇을 더 개발할 수 있을까요?
|
|
자연어 처리 기술은 다양한 분야에서 활용되고 있으며, 앞으로도 계속해서 다양한 분야에서 적용될 것으로 예상됩니다. 여러 가지 가능한 분야를 나열해 보면 다음과 같습니다.
|
|
자연어 처리 기술로 무엇을 더 개발할 수 있을까요?
|
|
자연어 처리 기술은 다양한 분야에서 활용되고 있으며, 앞으로도 계속해서 다양한 분야에서 적용될 것으로 예상됩니다. 여러 가지 가능한 분야를 나열해 보면 다음과 같습니다.
|
|
이 분야에서 자연어 처리 기술을 활용한 뛰어난 기술적인 예시가 있나요?
|
|
예, 다음은 자연어 처리 기술을 활용하여 뛰어난 성과를 보인 몇 가지 기술적인 예시입니다.
|
|
자연어 처리 기술이 현재 어떻게 발전하고 있나요?
|
|
자연어 처리 기술은 계속해서 발전하고 있으며, 다양한 분야에서 활용 예상이 대단합니다. 최근에는 다음과 같은 발전이 있었습니다.
|
|
자연어 처리 기술이 현재 어떻게 발전하고 있나요?
|
|
자연어 처리 기술은 계속해서 발전하고 있으며, 다양한 분야에서 활용 예상이 대단합니다. 최근에는 다음과 같은 발전이 있었습니다.
|
|
자연어 처리 기술이 현재 어떻게 발전하고 있나요?
|
|
자연어 처리 기술은 계속해서 발전하고 있으며, 다양한 분야에서 활용 예상이 대단합니다. 최근에는 다음과 같은 발전이 있었습니다.
|
|
자연어 처리 기술이 현재 어떻게 발전하고 있나요?
|
|
자연어 처리 기술은 계속해서 발전하고 있으며, 다양한 분야에서 활용 예상이 대단합니다. 최근에는 다음과 같은 발전이 있었습니다.
|
|
자연어 처리 기술이 현재 어떻게 발전하고 있나요?
|
|
자연어 처리 기술은 계속해서 발전하고 있으며, 다양한 분야에서 활용 예상이 대단합니다. 최근에는 다음과 같은 발전이 있었습니다.
|
|
음성 인식이 발전한다면 어떤 분야에서 더 활용될 수 있을까요?
|
|
음성 인식 기술이 발전함에 따라, 다양한 분야에서 더욱 높은 수준의 음성 인식 기능이 활용될 수 있을 것으로 예상됩니다. 여기서는 음성 인식 기술이 더욱 발전했을 때, 예상되는 분야를 설명해 드리겠습니다.
|
'say와 AI 챗봇친구 만들기 보고서' 카테고리의 다른 글
| ChatGPT(챗GPT) 공식 가이드라인 [ChatGPT-5 및 창작 과정] (0) | 2023.06.25 |
|---|---|
| 고급화 전략으로 자라가 반등한 건에 대하여 [남다른 생각으로 성공을 이뤄라! 파괴적 사고 프로세스] (0) | 2023.06.24 |
| 인공지능(AI) 신에 등장한 슈퍼스타, 챗GPT(ChatGPT) [튜링 빌더로 직접 챗봇을 자유롭게 제작해보세요.] (0) | 2023.06.24 |
| AI 모델 40만개 공개했다, 개발자 200만명 홀린 [때로는 미묘한...MS·오픈AI 동맹 '비하인드 스토리'] (0) | 2023.06.17 |
| 챗GPT로 마인크래프트 자동 플레이? AI 모델 보이저 [오픈AI 챗GPT 운영비, 하루 10억원 육박] (1) | 2023.06.17 |



