

Generative AI (생성 AI) 란?
인간은 사물을 분석하는 데 능숙합니다. 기계는 훨씬 더 뛰어납니다. 기계는 일련의 데이터를 분석하고 그 안에서 패턴을 찾아내어 사기나 스팸 탐지, 배송 예상 시간 예측, 다음에 보여줄 TikTok 동영상 예측 등 다양한 사용 사례에 활용할 수 있습니다. 이러한 작업은 점점 더 똑똑해지고 있습니다. 이를 “Analytical AI” 또는 traditional AI라고 합니다.
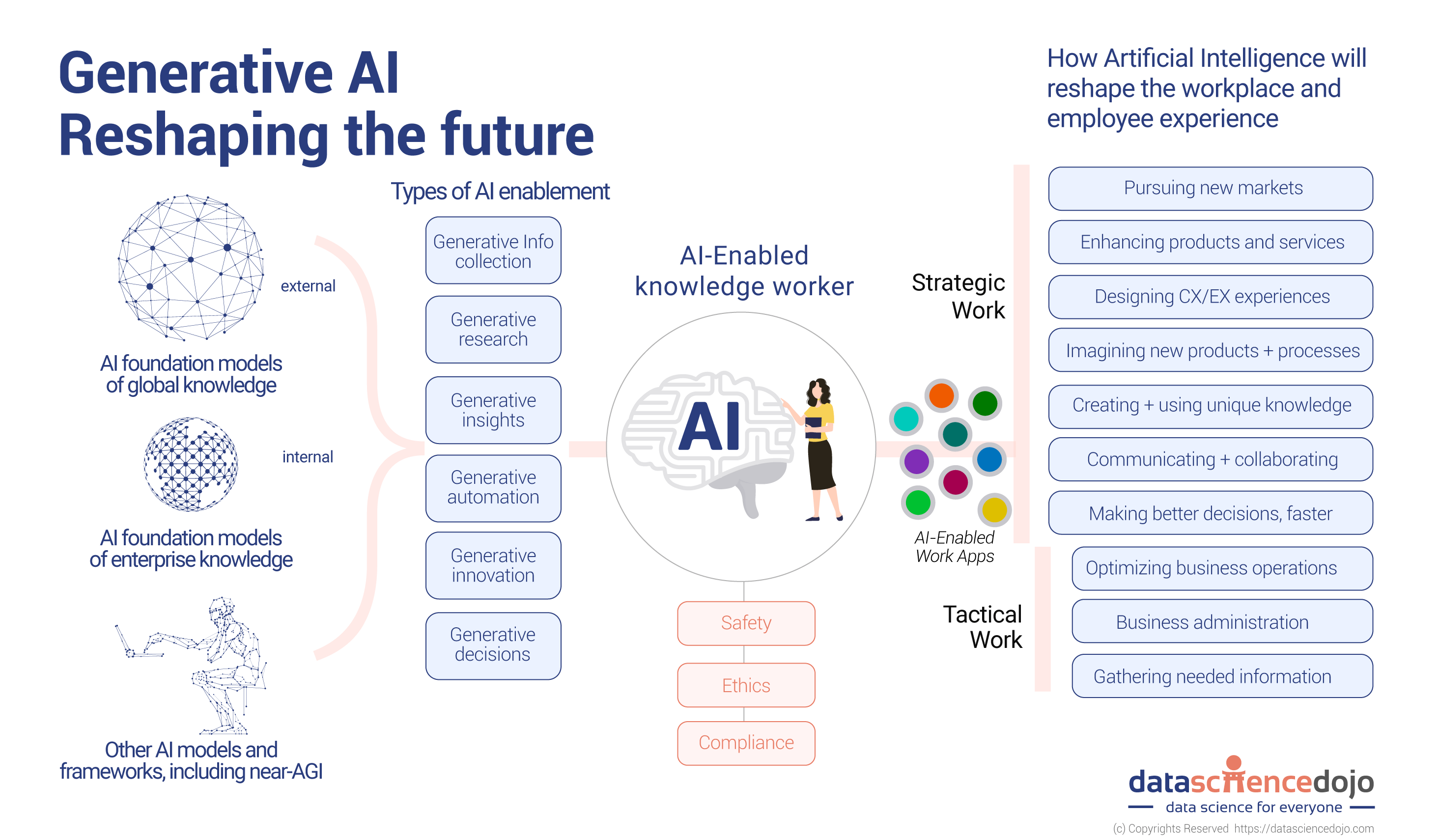
Generative AI는 비정형 딥 러닝 모델을 사용하여 사용자 입력을 기반으로 콘텐츠를 생성하는 인공지능의 일종입니다. 이용자의 특정 요구에 따라, 결과를 능동적으로 생성하는 인공지능 기술을 통칭하고 있습니다. 예를 들어, ChatGPT에 질문을 입력하면 간단하지만 합리적이고 상세한 서면 답변을 제공하는 것과 같습니다. 또한 후속 질문을 입력하고 다시 답변받을 수 있으며, 이때 챗봇은 대화 초기의 세부 사항을 기억할 수 있습니다.
Generative AI, 생성 AI 는 인간이 손으로 만드는 것보다 더 빠르고 저렴할 뿐만 아니라 경우에 따라서는 더 나은 결과를 만들어낼 수 있는 단계에 와 있습니다. 소셜 미디어에서 게임, 광고, 건축, 코딩, 그래픽 디자인, 제품 디자인, 법률, 마케팅, 영업에 이르기까지 인간이 독창적인 작업을 만들어야 하는 모든 산업이 재창조될 수 있습니다. 어떤 업무, 작업은 생성 AI로 완전히 대체될 수도 있고, 어떤 기능은 인간과 기계 간의 긴밀한 반복적 창작 주기를 통해 번창할 가능성이 높습니다. 제너레이티브 AI가 창작과 지식 작업의 한계 비용을 0으로 낮춰 막대한 노동 생산성과 경제적 가치를 창출할 것이라는 것에는 모두가 동의하게 되었습니다.
최근 Generative AI의 혁신이 가속화되면서 시장과 대중의 관심을 사로잡고 있습니다. OpenAI의 GPT는 사람이 쓴 것처럼 보이는 정확한 텍스트를 생성할 수 있습니다. 또한 DALL·E와 같은 Image generator는 단어 입력을 기반으로 사실적인 이미지를 생성할 수 있죠. 구글, 페이스북, 바이두를 포함한 다른 기업 역시 사람이 쓴 것처럼 생생한 텍스트와 이미지, 컴퓨터 코드를 생성할 수 있는 정교한 Generative AI 개발에 박차를 가하고 있습니다.
👉 AI의 정의와 역사, 유형에 대한 구체적 설명이 궁금하다면?
AI 인공지능 이란 무엇인가? - 정의, 역사, 유형, 응용 분야
AI의 개념, 유형, 활용까지 한판 정리
AI 개념
정의
AI (Artificial intelligence, 인공지능) 이란, 인간처럼 생각할 수 있는 기계를 만드는 과학입니다. 전통적으로 인간 지능이 필요했던 작업들을 컴퓨터로 수행하는 것을 의미합니다.
AI 기술은 사람보다 많은 양의 데이터를 다양한 방식으로 처리할 수 있습니다. 인공지능은 인간의 지능과 유사한 방식으로 학습하고 사고하고 행동할 수 있는 컴퓨터 시스템을 개발하는 것입니다. AI는 컴퓨터 공학, 데이터 분석, 통계, 신경 과학, 철학, 심리학 등 다양한 학문의 연구 결과를 바탕으로 개발되고 있습니다.
이를 토대로 AI는 데이터 분석이나 예측, 분류, 자연어 처리, 추천, 지능형 데이터 가져오기 등을 수행할 수 있습니다. 또한 자율주행 자동차나 로봇, 의료 진단, 재정 분석, 고객 서비스 등 다양한 분야에서 활약하고 있습니다.
장점
AI 기술을 활용함으로써 다양한 이점을 얻을 수 있습니다.
- 워크플로우 및 프로세스 자동화
AI는 워크플로 및 프로세스를 자동화하고, 독립적이고 자율적인 작업을 할 수 있습니다. 또한 AI를 사용하면 문서를 확인하거나 텍스트 변환, 간단한 고객의 질문에 답변하기 등 반복적이고 단순한 작업을 자동화하여 인적 자본이 더 중요한 일에 집중할 수 있습니다. - 휴먼 에러 감소
AI는 인간보다 더 많은 정보를 빠르게 처리하며, 사람이 놓칠 수 있는 데이터의 패턴을 찾고 관련성을 발견하는 데에 능합니다. 또한 AI는 할당된 작업을 계속 진행할 수 있습니다. 매번 동일한 프로세스를 따르는 자동화 및 알고리즘을 통해 데이터 처리, 분석, 제조 및 기타 작업 과정에서 인간이 범할 수 있는 수동 오류를 줄일 수 있습니다. - 연구 및 개발 가속화
방대한 양의 데이터를 빠르게 분석할 수 있는 기능은 연구 개발의 가속화로 이어질 수 있습니다.
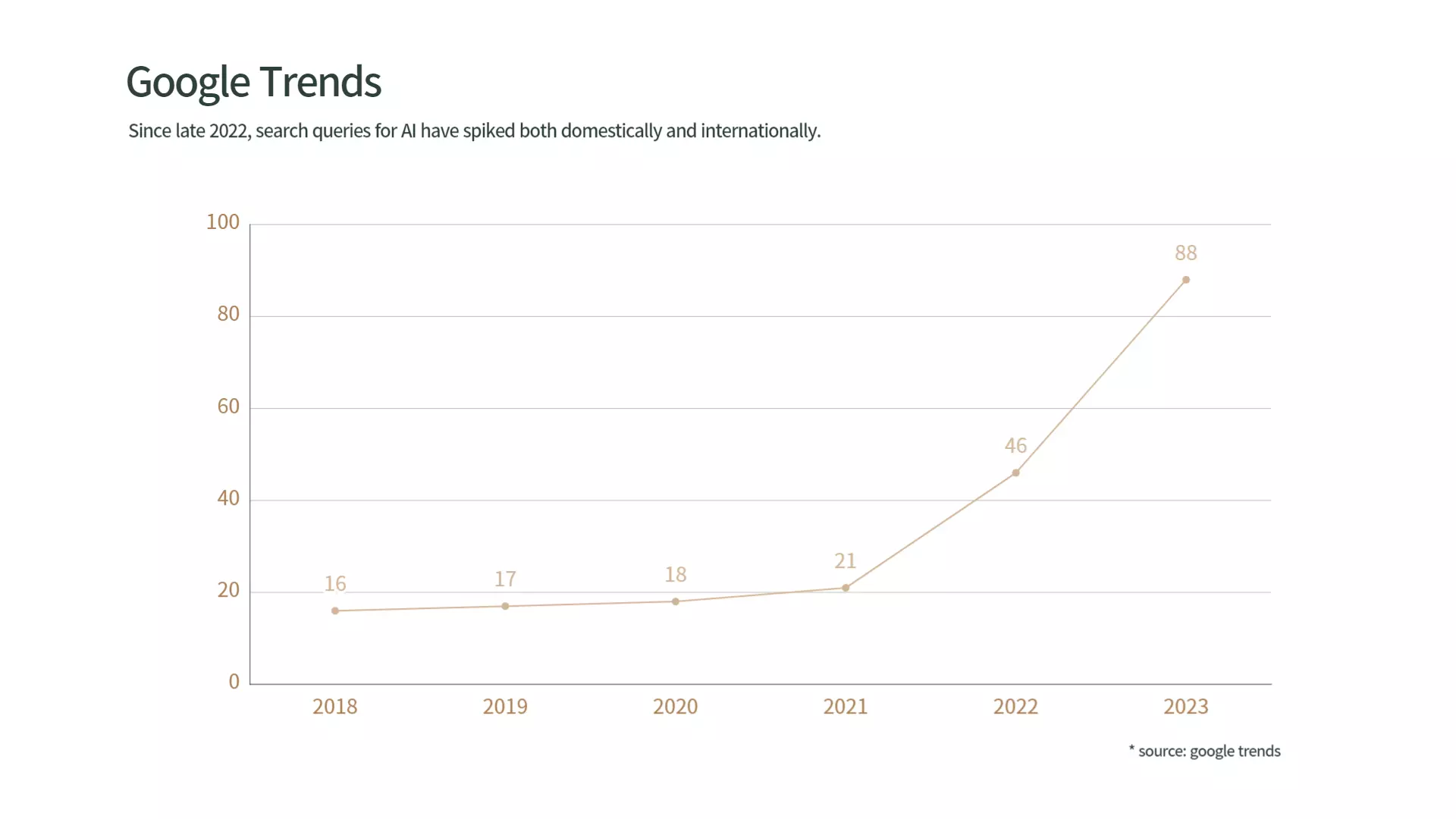
2022년 말부터 국내외에서 AI에 대한 검색 쿼리가 급증했습니다. 2022년 전 세계 인공지능 시장 규모는 692억 5,000만 달러였으며 전 세계 기업의 35%가 인공지능을 사용하고 있었습니다. 오늘날 인공지능은 수요가 많은 기술을 제공하고, 신기술을 이해하도록 도울 뿐만 아니라 문제 해결 및 의사결정 능력을 향상할 수 있다는 점에서 여전히 큰 관심을 받고 있습니다.
👉 Generative AI의 역사와 적용 사례가 궁금하다면?
강인공지능 vs. 약인공지능
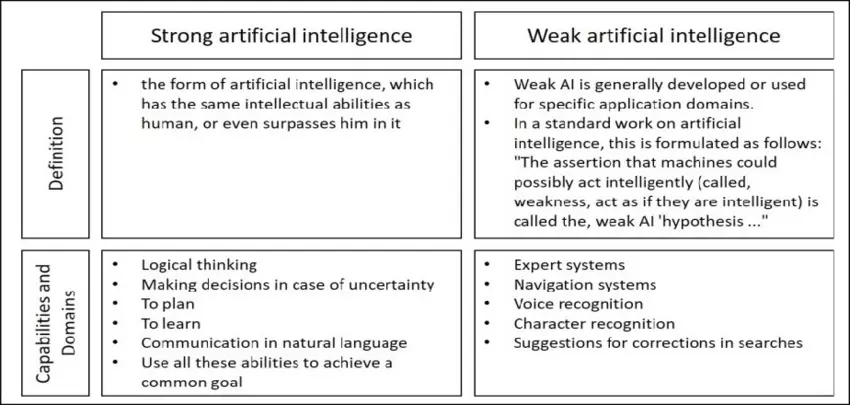
강인공지능과 약인공지능은 AI 구축의 목적에 따라 달라진다고 할 수 있습니다.
약인공지능 (Weak AI, WAI) 란?
- 특정 인지 기술이 필요한 작업을 자동화하도록 설계된 AI 애플리케이션
- ‘약한’ 의 뜻은 응용프로그램이 특정한 인지 기능에 초점을 맞추고 있다는 것을 의미
- 객체 인식, 챗봇, 개인 음성 비서, 자동 수정 시스템이나 Google 검색 알고리즘 등 특정 작업에 맞게 조정된 머신러닝 모델
- ChatGPT, Midjourney, Stable Diffusion, DALL·E, Bard 등이 여기에 포함
강인공지능 (Strong AI, SAI) 란?
- 인공지능의 분석적 사고 및 기타 지적 능력 등의 계산 능력이 인간의 두뇌를 모방할 수 있다는 믿음에서 출발
- 좁은 작업을 수행하기 위해 모델에 의존하지 않음
- 인간의 뇌 기능을 시뮬레이션하여 일반적인 작업을 처리할 수 있는 잠재력
- 시간이 지남에 따라 진화하는 기술 시스템과 환경 변화에 적응할 수 있는 능력
Weak AI와 Strong AI의 차이점을 간략하게 요약하면 다음과 같습니다.
- 특정 프로세스를 자동화하여 다양한 분야의 효율성을 높이는 약인공지능과 달리, 강인공지능은 인간 두뇌의 기능을 모방하는 것을 목표로 설계되어 ‘인간처럼’ 광범위한 작업을 수행할 수 있습니다.
- 약인공지능은 특정 데이터 세트에 의존하여 패턴을 학습하고 반복 작업을 수행합니다. 반면 강인공지능은 인간의 인지 과정을 모방하기 위해 광범위하고 방대한 양의 데이터를 학습합니다.
- 약인공지능의 시스템이 만든 예측 및 결과는 일정하기 때문에 신뢰할 수 있습니다. 반면 강인공지능은 보다 복잡하고 창의적인 작업을 처리하기 위한 문제 해결 접근 방식이 도입되어 종종 불명확하고 신뢰할 수 없는 결과를 낼 수도 있습니다.
AI 기술 범주
인공지능은 인간의 지능과 유사한 행동과 특성을 모방하는 시스템을 가지고 작업을 수행하기 위해 학습하고, 추론하고, 이해할 수 있습니다. 이를 통해 다양한 산업 분야에서 눈부신 발전을 이루었습니다. 이 섹션에서는 가장 대표적인 인공지능 기술의 4가지 범주를 소개합니다.
Machine learning (머신러닝)
- 특정 작업을 수행하도록 프로그래밍하는 대신, 경험을 통해 자동으로 배우고 개선하는 AI Application
- Unsupervised, Supervised 및 Reinforcement Learning 등의 알고리즘을 사용
- 데이터 정확도에 따라 출력 정확도가 상이
NLP (자연어 처리)
- 인간과 컴퓨터 간의 상호 작용을 용이하게 하기 위해 인간의 언어를 컴퓨터 프로그래밍
- speech-to-text, text-to-speech, IVR(Interactive Voice REsponse), 번역 등에 활용
자동화 및 로보틱스
- 기계가 단조롭고 반복적인 작업을 수행하여 비용 효율적인 결과를 얻고, 생산성과 효율성을 향상시키는 것을 목표
- 머신러닝, 신경망 그래프를 자동화에 적용
- 온라인 금융 거래에서 사기를 방지하는 기술인 CAPTCHA가 대표적인 사례
- RPA (Robot Process Automatic) 을 통해 다양한 상황의 변화에 적응할 수 있는 대량의 반복 작업을 구축
Computer Vision
- 카메라를 사용하여 시각적 정보를 캡쳐하고, 아날로그 이미지를 데이터로 변환하고 처리하는 작업
- Pattern recognition, Object Detection 기술을 통해 서명 식별 및 의료 영상 분석 등으로 활용
👉 RPA의 핵심 기술, OCR에 대해 알아보기
OCR 이란? - 정의, 기술, Use case, 데이터 품질
광학 문자 인식(OCR)의 역사와 최신 트렌드까지 총정리

OCR (광학 문자 인식) 이란?
정의
광학 문자 인식 (OCR, Optical Character Recognition) 은 텍스트 이미지를 ai 컴퓨터가 읽을 수 있는 포맷의 텍스트로 변환하는 과정을 의미합니다. 예를 들어, 물리적인 인쇄물이나 영수증을 스캔하는 경우 컴퓨터는 스캔본을 이미지 파일로 저장합니다. 이미지 파일에서는 텍스트 편집기를 사용하여 단어를 편집, 검색하거나 단어의 수를 계산할 수 없습니다. 그러나 OCR을 사용하면 이미지를 텍스트 문서로 변환하여 텍스트 데이터로 저장하고 다양한 작업을 할 수 있습니다.
기술 원리
OCR = Text detection + Text recognition
OCR 엔진에는 여러 OCR 모델과 알고리즘이 단계 별 task를 수행합니다. Text detection과 Text Recognition은 그 중에서 가장 중심적인 task이며, 전체적인 워크플로우는 아래와 같습니다.
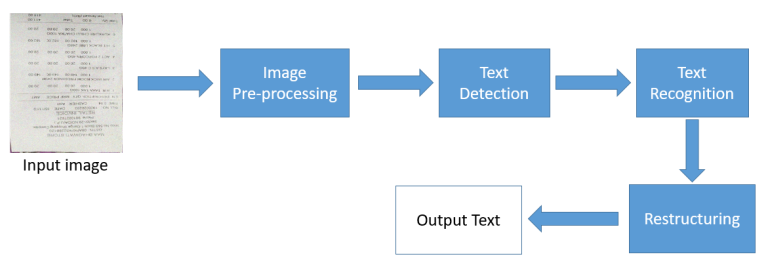
- Pre-processing: OCR의 input image는 노이즈로 인해 손상되거나 기울어지거나 또한 회전되어 있는 경우가 많습니다. 이러한 경우 다음 단계에서 제대로 된 결과가 나올 수 없기 때문에 사전에 손상된 이미지를 복구하거나 회전이나 기울여진 이미지를 복구합니다.
- Text Detection: Text detection은 Object detection의 확장 버전이라고 할 수 있습니다. Text recognition은 검출된 영역의 문자가 무엇인지를 인식하는 과정을 의미합니다. OCR은 구체적으로는 Classification, Detection과 Segmentation 기법이 결합된 형태입니다. 최근에는 두 가지 모두를 동시에 해내는 End-to-end 모델 개발이 성행하고 있습니다. 그 외에도 속도를 개선하거나, 프로세스를 조정하는 등 다양한 케이스로 발전되고 있습니다.
- Text Recognition: 이 단계에서 detection, segmentation 된 image boundary에 어떤 text가 있는지를 인식합니다. 작업 결과 일반적으로 텍스트와 함께 이미지 내 좌표와 영역이 나열된 텍스트 파일을 얻을 수 있습니다.
- Restructuring: Restructuring이란 input image에 있던 좌표에 따라 텍스트를 재배치하는 것을 의미합니다. 각 좌표를 반복하여 인식된 텍스트를 배치하기만 하면 됩니다. 재구성된 데이터는 원본 이미지와 구조적으로 유사한 형태로 만들어지며, 텍스트가 가진 정보의 context를 인식하는데 도움이 됩니다.
( ex> 이름: 문상선 -> [문상선]은 이름이다 )
OCR이 계속 주목받는 이유
OCR은 현재까지 20여년 간 사용 되었습니다. 기술 발전으로 인해 문서나 이미지만 인식하던 기술에서 일상적인 사진이나 동영상 속 문자까지 인식하는 기술로 발전되고 있죠. 왜 OCR 기술이 중요할까요?
비즈니스 업무 효율 향상
OCR은 기업의 이미지 및 문서 처리 업무를 자동화하여 프로세스 효율 극대화 및 비용 절감에 효과적입니다. 특히 증빙서류 등의 문서 처리가 많은 기업에서 많이 사용하고 있습니다. 특히 모바일 사용이 대중화되면서 기업이 처리해야 할 스캔 이미지가 모바일 촬영 이미지로 대체되고 있습니다. 수집된 이미지의 내부 자료화를 위해 문자 내용을 사람이 일일이 엑셀파일이나 데이터베이스에 입력하는 방식 대신 OCR 기술을 적용하면 생산성을 크게 높일 수 있습니다.
특히 OCR은 프로세스의 효율화 및 자동화 측면에서, RPA와 연계했을 때 더욱 효과적입니다. RPA는 단순 반복적인 업무 프로세스를 사람 대신 소프트웨어 로봇이 수행하게끔 설계하는 업무 자동화 기술입니다. RPA와 연계된 OCR은 인식한 값들을 저장 및 전송하는 것에서 더 나아가 프로세스 전체를 자동화할 수 있습니다.
LLM 학습 데이터 파인 튜닝
또한 OCR 기술은 스캔한 문서와 이미지에서 텍스트를 추출하여 대규모 언어 모델(LLM)을 학습하고 미세 조정하는 데에 사용할 수 있습니다. LLM은 텍스트를 생성하고, 언어를 번역하고, 다양한 종류의 창의적인 콘텐츠를 작성하고, 질문에 답변할 수 있는 Generative AI입니다. ChatGPT나 Bard, PaLM 등 Foundation Model이 여기에 포함되어 있습니다.
이러한 LLM, 대규모 언어 모델들은 텍스트와 코드로 구성된 방대한 데이터 세트를 학습하며, 학습하는 데이터 품질이 성능에 매우 중요합니다. OCR 기술은 스캔 문서나 이미지, PDF 등 다양한 형식의 고품질 데이터를 LLM에 제공하며 고객 응대 ai 챗봇 등에 활용될 수 있습니다. 이 데이터는 Text classification, NLP, Q&A 등 다양한 작업에서 LLM을 훈련시키는 데에 사용할 수 있습니다.
OCR 설루션 및 활용 사례
PDF 스캐너
PDF OCR 이란, 자동으로 광학 문자 인식(OCR)을 문서에 적용하고 편집 가능한 PDF 사본으로 변환하는 것입니다. PDF 스캐너에서 OCR은 이미지를 다른 비즈니스 소프트웨어가 읽을 수 있는 텍스트 데이터로 변환하여 개인과 기업의 시간과 비용 리소스를 절약할 수 있다는 장점이 있습니다.
일상에서 쉽게 사용할 수 있는 유무료 PDF 스캐너를 간단하게 소개합니다.
- PDF24
- 브라우저 작동 방식으로 별도의 소프트웨어 설치 불필요
- 오프라인 사용이 필요할 시 데스크톱 응용 프로그램 사용 가능
- 리눅스와 스마트폰에서도 호환 가능
- SodaPDF
- 웹 브라우저에서 온라인 변환 가능, 데스크톱 응용 프로그램으로 오프라인 작업 가능
- 이메일로 OCR된 문서를 다른 사람에게 전송하고 공유
- 인식한 PDF를 HTML, DOCX, TIFF로 변환하고 웹 브라우저에서 수정 가능
- AvePDF
- 100가지 이상의 형식 지원
- 영어, 프랑스어, 독일어, 스페인어, 이탈리아어, 포르투갈어 중에서 OCR 언어 선택 가능
- PDF를 PPT, Word, JPG, PDF/A, PNG, TIFF, Grayscale, Excel, TXT로 변환
- 최대 파일 크기 128MB, 시간당 최대 1건 무료, 처리당 최대 파일 수 10건
- Aspose.app
- Aspose API를 사용하여 높은 인식 품질
- 자동 이미지 전처리를 수행하여 저해상도, 저대비, 노이즈 및 스큐 수정
- 자동화된 문서 레이아웃 감지 알고리즘
ChatGPT를 통한 OCR 시스템
ChatGPT는 OpenAI를 통해 책과 코드, 구글 검색 결과로 학습한 대화형 인공지능 서비스입니다. 이 모델에 OCR 기술을 접목하면, 이미지에서 추출한 원시 텍스트 데이터의 후처리에 이상적입니다. GPT를 OCR 시스템에 결합하면, 스캔한 문서는 컴퓨터와 휴대폰에서 자동으로 API로 보낼 수 있습니다.

LLM에 구축된 OCR 모델은 방대한 데이터 세트를 학습하여 언어의 구조를 깊이 이해하기 때문에, 필기 텍스트나 저품질 데이터 등 까다로운 텍스트 출력 과정에서 OCR 모델의 정확도를 향상할 수 있습니다. 또한 언어의 기본 원리를 학습하는 과정을 통해 새로운 맥락에서 텍스트를 인식할 수 있습니다. 예를 들어 GPT에 OCR 데이터를 제공한 뒤 텍스트의 상세 내용에 대해 질문을 하면 답변을 받을 수 있는 것이죠.
물론 LLM 기반 OCR 모델에도 장점과 한계는 있습니다. 이 방식은 손으로 쓴 텍스트나 품질이 낮은 이미지 등 까다로운 입력에도 정확하게 대응합니다. 영어를 포함해 몇 종류의 단어에만 능숙한 기존 OCR 모델보다 다양한 언어의 텍스트를 인식할 수 있습니다. 하지만 훈련 및 배포에 많은 비용이 소모될 수 있으며, 많은 양의 학습 데이터가 필요합니다. 모델에 입력한 데이터가 학습 데이터와 매우 다를 경우 이를 인식하지 못할 수도 있습니다.
NAVER
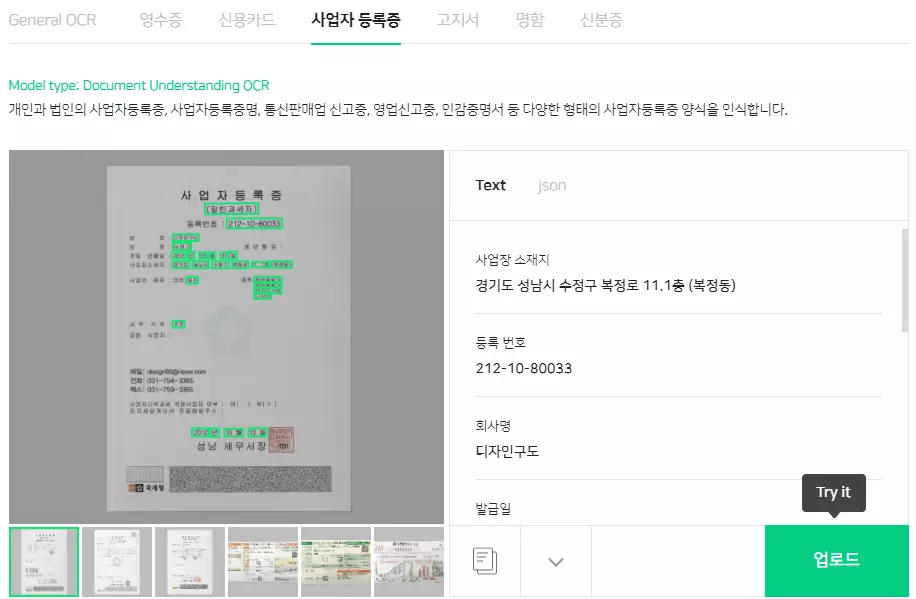
네이버는 실제 사용 환경과 실용성에 따른 모델 개선에 주목하고 있습니다. Clova AI에서 서비스되는 Document understanding OCR은 문서의 종류에 따라 API를 분리했기 때문입니다. 즉, 영수증이나 신용카드, 사업자등록증, 고지서, 명함, 신분증 등 문서가 무엇이냐에 따라 전처리와 후처리 방법이 다르게 설정되어 있다는 것을 알 수 있습니다.
네이버의 Text detection 모델은 watershed 기반의 학습 데이터 전처리 방법으로 데이터를 먼저 가공한 후, U-Net 기반 네트워크를 이용하여 학습합니다. 이후 Text recognition 모델은 검출된 텍스트의 인식을 위해 모델들을 조합하여, 객관적인 benchmark 방법을 제안합니다. 논문에 의하면, TPS+ResNet+BiLSTM+CTC 조합이 가장 우수하다고 합니다.
KAKAO
카카오는 YOLO와 유사한 특성으로 설계하여 실시간성에 주목하고 있습니다. 카카오는 처음 1차 인식 모델 RNN Layer를 사용했지만, 의존적인 구조와 순차적으로 글자를 뽑아낼 수밖에 없다는 한계를 개선하기 위해 연구해 왔습니다. 그 결과, Self-attention 구조를 통해 성능은 유지하고 속도만 개선하는 데에 성공했습니다.
카카오의 OCR 구성 키워드를 분류하자면 다음과 같습니다.
- 구조: Text detection, Text Recognition 모델 분리
- Text detection model: Character-level Output, Model-based Clustering, Orientation Prediction, Simple Postprocessing (No NMS)
- Text recognition model: Less Resources(No TPS), Transformer Only Model, Fixed Length Input
Google, Microsoft, meta
Google 역시 카카오와 유사한 방식의 Multi-head를 이용한 OCR 기술을 구축했습니다. Word와 Character별로 Bounding box를 각각 획득한 뒤, Recognition을 수행하는 것을 알 수 있었습니다. 이외에도 구글은 Vision-transformer 등을 통해 Vision Task에서도 Attention을 이용하고자 하며, 이를 OCR에도 활용하고 있습니다.

Microsoft Azure는 문단 단위로 텍스트 검출 영역을 확보하고 line detection, word 단위의 결과로 리턴합니다. 이는 앞에서 설명한 구글과는 다소 다른 방식인데, 일부 Structured text에 적용할 수 있다는 점에서 화제가 되고 있습니다. 즉, Microsoft는 구조화된 텍스트에 특화된 OCR 모델에 주목하고 있습니다.
META는 Scene text 대상 End-to-End 모델에서 활용 가능한 image-text, region-text-QA 구조의 멀티 모달을 연구하고 있습니다. 이러한 구조로 된 TextVQA data를 이용해 multi-modal로 학습한 경우, 같은 모델보다 최대 20% 이상 성능 향상을 거둘 수 있다는 점에서 놀라운 결과를 보였습니다.
딥 러닝과 OCR
Before Deep learning
딥 러닝이 적용되기 전 OCR은 OCR Engine으로 Tesseract OCR을 사용했습니다. 이 기술은 휴렛 팩커드가 제작한 뒤 오픈소스되고, 구글에 의해 디벨롭되면서 꾸준히 연구되고 있습니다. OCR의 역사에 대해 더 자세히 알고 싶다면 여기를 참고해 보세요.
딥러닝이 OCR에 활용되기 전에는 어떤 방식으로 이미지 속 문자를 찾아냈을까요? 관심 있으신 분은 논문 링크를 통해 살펴보실 수 있습니다.
이 글에서 설명할 OCR의 대략적인 architecture는 아래와 같습니다.
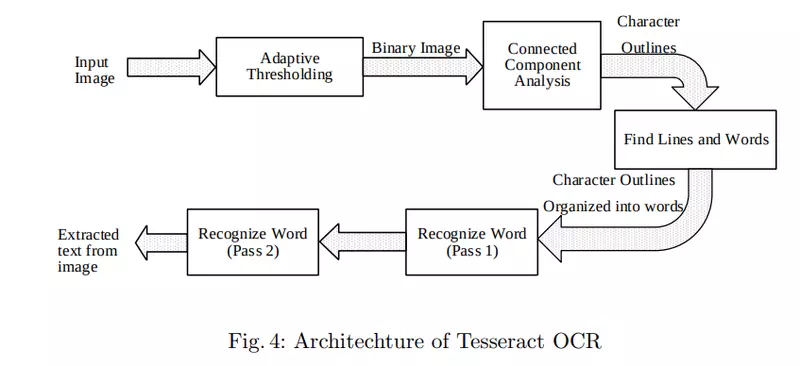
- Adaptive Thresholding: 입력 영상의 이진화를 통해 흑백으로 변환
- Connected Component Analysis: 문자 영역을 검출
- Find Lines and Words: 라인 또는 단어 단위를 추출
- Recognize Word: 단어 단위 이미지를 Text로 변환하기 위해 문자를 하나씩 인식하고 다시 결합
위의 과정은 일반적인 딥 러닝 기반의 OCR에도 적용되는 기본적인 단계입니다. 수행하고자 하는 목표와 기본 흐름은 같으나, 딥 러닝이 없었던 시절인 만큼 방법이 달랐다고 볼 수 있습니다.
Text detection
딥 러닝을 이용해 이미지에서 텍스트의 위치를 찾는 Text detection은 Object detection이나 segmentation 기법 등과 유사한 속성이 있지만 세부적으로는 다른 특성이 있습니다.
문자는 몇 개가 모여서 단어나 문장을 이루기 때문에, 이미지 내에서 문자를 검출해 낼 때엔 최소 단위를 설정하는 과정이 필요합니다.
[고] , [구], [마], [는], [맛], [있], [다]
예를 들어, 위처럼 글자 단위로 따로 검출한다면 이후 맥락에 맞추어 글자를 붙여주는 과정을 거쳐야 합니다.
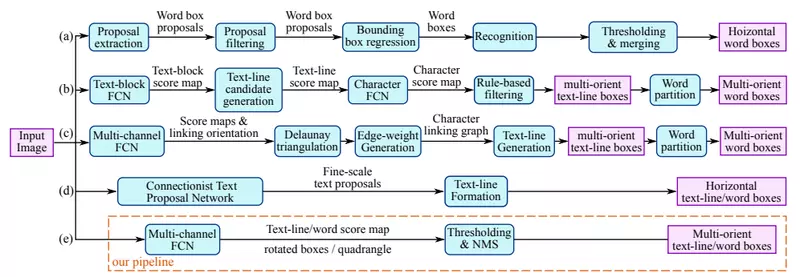
위 그림은 2017년에 발표된 EAST:An Efficient and Accurate Scene Text Detector 논문에서 발표한 Text detection 기법을 정리한 것입니다. 당시에는 Text의 Bounding box를 구하는 방식이 주를 이루었습니다. 따라서 가로 방향의 텍스트 박스를 구하는 방식이나 여러 방향(Multi-oriented)의 텍스트 박스를 구하는 방식이 다양하게 소개되어 있습니다. 특히 단어 단위의 탐지와 글자 단위의 탐지가 모두 활용되고 있다는 것을 알 수 있습니다.
단어 단위의 탐지 방법과 글자 단위의 탐지 방법은 어떤 차이가 있을까요?
문장 또는 단어 단위의 탐지
- Object detection의 Regression 기반의 탐지
- 긴 단어 혹은 문장과 함께 짧은 길이도 찾을 수 있어야 함
- Anchor를 정의하고 단어의 유무와 Bounding box의 크기를 추정해서 단어를 탐지
글자 단위의 탐지
- Bounding box regression을 사용
- 글자를 놓치지 않고 찾아낼 수 있지만, 글자를 다시 맥락에 맞게 묶어주는 과정이 필요
- 글자 영역을 Segmentation 하는 방법으로 접근
Text recognition
글자의 이미지들은 문자의 순서대로 정보를 가지고 있습니다. 다만 일부 이미지는 분리에 비용이 많이 들거나 난이도가 어려워 segmentation이 되지 않은 상태일 수 있습니다.
이런 데이터에 대해서 CNN(Convolutional neural network)와 RNN(Recurrent neural network)를 함께 쓰는 방식으로 Text recognition을 수행할 수 있습니다. 이런 모델을 CRNN이라고 합니다. CRNN은 입력된 이미지가 어떤 문자일지를 높은 확률로 맞추어내어 data processing과 Deep learning에 도움을 주고 있습니다.
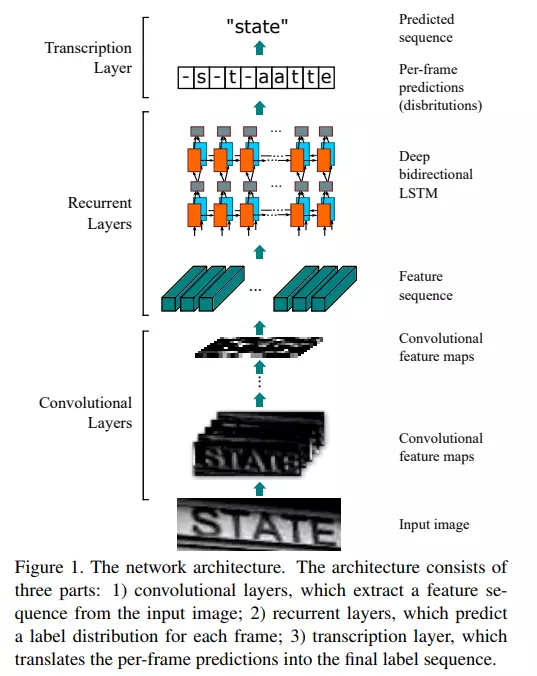
또한 Attention과 Text recognition 모델의 조합이 딥 러닝 OCR 분야에 큰 영향을 미치고 있습니다. Attention 기반 순차 예측은 문장의 길이를 고정하고 입력되는 Feature에 대한 Attention을 기반으로 해당 글자의 Label을 예측하는 방법입니다. 첫 번째에 입력된 Feature에 대한 Attention을 기반으로 Label을 추정하고, 추정된 Label을 다시 입력하여 다음 글자를 추정하는 방식입니다.
예를 들어, "안녕하세요"라는 문장을 예측한다고 가정해 보겠습니다. Attention 기반 순차 예측은 첫 번째 글자인 "안"에서 입력 Feature에 대한 Attention을 기반으로 "녕"이라는 Label을 추정합니다. 추정된 Label인 "녕"을 다시 입력으로 사용하여 다음 글자인 "하"를 추정합니다. 이 과정을 반복하여 "안녕하세요"라는 문장을 예측합니다.
Attention과 Text recognition 모델의 조합에 대한 성능 정보는 Naver Clova의 논문에서 자세히 알 수 있습니다.
OCR 최신 연구 논문
아래에는 최근 주목받고 있는 기술 개요와 논문으로, 자세한 내용은 각 논문 링크에서 확인하실 수 있습니다.
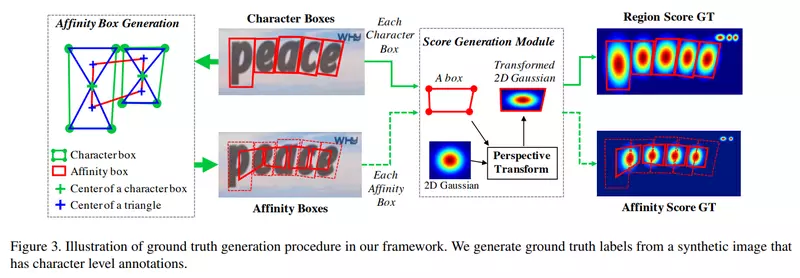
- CRAFT (Character region Awareness for Text Detection)
- 문자 단위로 문자의 위치를 찾아낸 뒤, 이를 연결하는 방식을 segmentation 기반으로 구현한 방법
- 문자의 영역을 명확히 구현하지 않고 원형의 score map을 만들어서 배치하는 방법으로 문자 영역을 학습
- Weakly supervised learning 활용
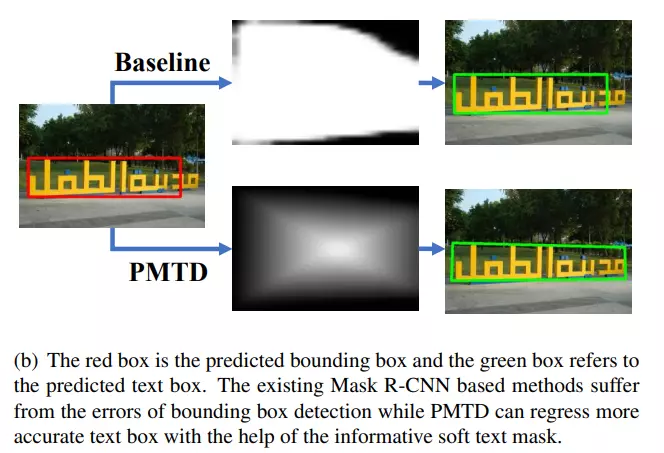
- PMTD (Pyramid Mask Text Detector)
- Mask-RCNN의 구조를 활용해 text 영역을 region proposal network로 탐지
- 이후 Box head에서 더 정확하게 regression 및 classification 후 mask head에서 instance segmentation
- Mask 정보가 부정확한 경우를 대비 및 반영하고자 Soft-segmentation 활용
OCR 데이터 품질 높이는 방법
최근 개발된 OCR 시스템은 Error Correction 모델을 추가하여 성능이 더욱 향상된 것을 볼 수 있었습니다. 예를 들어, OCR 시스템이 B로 적힌 문자를 A로 잘못 인식했을 경우, Error Correction 모델은 문서에서 문자가 A일 확률과 B일 확률을 비교하여 이 오류를 식별할 수 있습니다. 경우에 따라 Error Correction 모델의 채용은 OCR 시스템의 오류율을 최대 50%까지 줄일 수 있다고 하죠.
또한 인식 대상 텍스트에 유의해야 할 맥락이 있거나, 특정 Wrong Case에 있을 경우 이를 정확히 분석해내고 있습니다. Error case에 대한 통계 데이터를 보유하고 있는 경우 환영할 만한 개선 결과입니다. 수동적인 접근 방식부터 단어 수준의 접근 방식, 문맥에 따른 접근 방식 등을 활용할 수 있습니다. 이외에도 OCR 데이터 품질을 개선하기 위한 여러 방안이 나오고 있습니다. 그중에서 데이터헌트가 추천하는 OCR 정확도 높이는 방법 두 가지를 소개합니다.
성능 평가
정확도를 높이는 방법에는 여러 가지가 있습니다. 그중 OCR 모델의 기본적인 성능을 분석한 결과를 토대로, 문제점을 파악하고 성능을 개선할 수 있습니다. 일반적으로 기존에 이루어지던 성능 평가 방법을 요약하면 아래와 같습니다.
- 검출 평가 방법 (IoU, Intersection over Union): 정답과 예측 박스가 얼마나 겹치는지 확인
- 인식 평가 방법 (WEM, Word based Exactly Matching): 정답과 예측 단어가 정확히 일치하는지 단어 기반으로 체크
- 인식 평가 방법 (1-NED, Normalized Edit Distance): 두 단어간 편집 거리를 측정한 뒤, 긴 단어의 길이로 정규화
- End-to-End 평가 방법: 검출 평가(IoU) → 인식 평가(WEM, 1-NED) 등으로 순차 평가 처리

그러나 기존 방법은 정교한 성능이 측정 불가하다는 단점이 있습니다. 하나의 정답 박스가 여러 개의 박스로 나뉘어 예측되거나, 여러 개의 정답 박스가 한 개의 박스로 합쳐져 예측되는 경우 정확한 성능을 측정할 수가 없었죠. 기존 방식의 한계에 대한 자세한 내용은 이 문서에서 확인하실 수 있습니다.

위의 문제를 해결하는 단서는 PopEval에 있었습니다. 신규 평가 방법은 피어슨 통계 분석 결과 기존 방법보다 우수한 것으로 밝혀졌습니다. 특히 Split, Merge 문제 해결에 가장 효과가 있었습니다.
원리는 단순합니다. 겹치는 영역의 글자 중에서 같은 글자를 하나씩 지우는 방식으로 정답률을 계산하고 성능을 측정하는 것이죠. 이는 사람의 평가 방식과 가장 유사하며, 글자 단위로 평가하기 때문에 정교한 성능 측정이 가능합니다.
Popeval 평가 알고리즘은 기존의 방식에 비해 인간의 정성적 평가에 가까운 방식으로 진행합니다. 문자 수준 접근 방식으로 고안되었지만, 비교 실험의 결과에 따르면 단어 수준에서 주석이 달린 기존 데이터 세트와도 호환이 가능한 것으로 밝혀져 업계에서도 주목을 받고 있습니다.
데이터헌트의 OCR 품질 개선
OCR 작업의 정확도를 높이기 위해서는 전처리가 중요합니다. 데이터헌트는 이 과정에서 AI와 사람이 협업하는 구조를 만들었습니다.
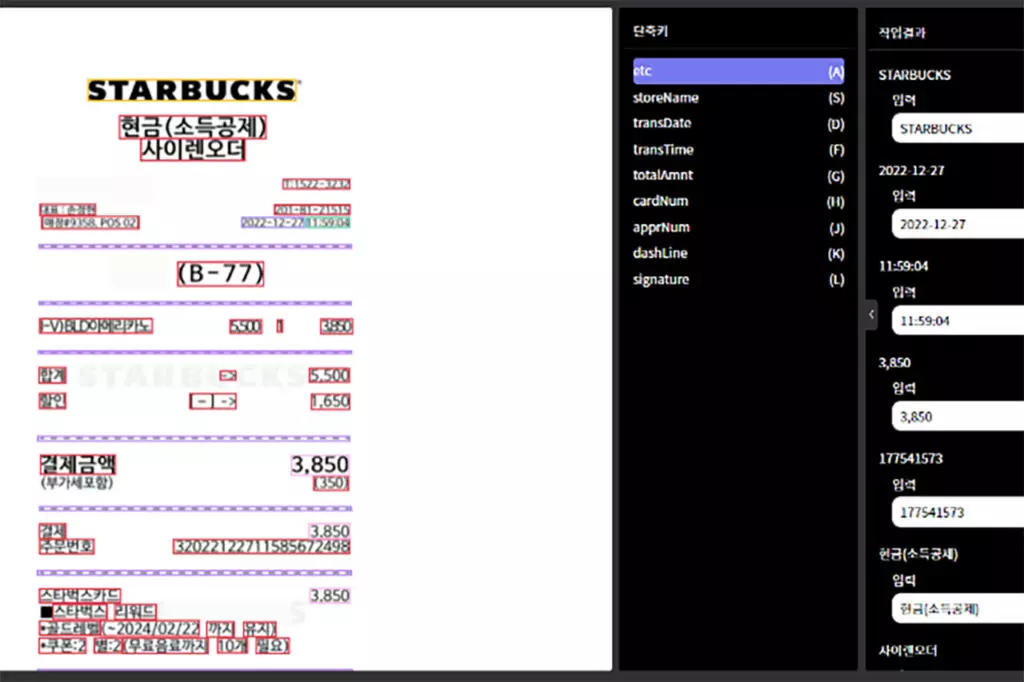
데이터헌트는 한국전력공사로부터 요청받은 영수증 이미지 10,000장 정제 미션을 수행하게 되었습니다. 데이터 구축 가이드라인 기준에 따라 Raw-data를 정제한 뒤, 글자 기울기에 따라 Bounding box 또는 Polygon을 사용했습니다. 이후 작업한 영역을 Text transcription을 진행하였으며, 메타 데이터 추출을 위한 Text classification 작업을 진행했습니다.
OCR 작업을 위한 전처리 과정에 인공지능을 도입하여 정확도뿐만 아니라 작업 시간 개선에서도 큰 성과를 보일 수 있었습니다. 평균적으로 데이터 라벨링 작업 시간을 40%가량 단축할 수 있었죠.
결론: OCR 시스템에 AI를 접목하여 데이터 추출 품질을 향상할 수 있다.
OCR 처리된 데이터로 AI를 훈련할 때 가장 중요한 것은 Bounding box의 밀도입니다. 모델이 텍스트 문자와 단어 사이의 공간적 관계를 학습할 때 이 기준이 중요하게 작용하기 때문입니다. Bounding box의 밀도가 높다는 것은 박스 간의 간격이 가깝다는 것으로, 이를 통해 AI는 원본 문서에서 이러한 문자와 단어가 서로 가까이 있을 가능성이 높다는 것을 학습할 수 있습니다. 이 정보를 사용하면 AI의 OCR 정확도를 향상할 수 있습니다.
예를 들어 BBOX의 밀도가 낮으면 AI가 원본 문서에서 ‘A’와 ‘B’가 서로 가까이 있을 가능성이 높다는 것을 학습하지 못할 수도 있습니다. 물론 밀도가 지나치게 높을 경우 AI가 모든 문자와 단어가 항상 서로 가깝다고 학습할 가능성이 높기 때문에, ‘THE’라는 단어를 학습하는 과정에서 ‘T’와 ‘HE’로 나누어서 판단할 수도 있죠.
따라서 OCR 가공 데이터로 모델을 학습시킬 때에는 Bounding box 밀도의 균형을 찾는 것이 중요합니다. 이를 위해서는 처리 중인 문서 유형에 적합한 Bounding box 밀도를 적용해야 하며, 표시해야 하는 텍스트 주위를 제대로 표기할 필요가 있습니다. 다양한 Bounding box 크기를 사용하고 글꼴을 사용해 모델이 지나치게 일반화되는 것을 방지하는 것도 중요합니다. 데이터헌트가 AI를 통해 OCR 작업을 진행할 때, 기울기를 수동으로 보정한 것도 Bounding box의 밀도를 더 높이기 위한 목적이었죠.
데이터헌트는 Human in the loop 원칙으로 사람의 평가 방식과 가장 유사한 방법을 채택합니다. 그와 동시에 AI를 통해 작업 시간을 단축하고 정확도를 향상하는 방법으로 OCR 품질 향상에 힘쓰고 있습니다. OCR은 비즈니스 자동화를 구축하기 위한 첫걸음이면서, 최우선으로 이루어져야 할 과제입니다. 중요한 미션인 만큼 최선을 다해 연구하고 검수하는 데이터헌트의 모습을 보여드리겠습니다.
요약
- 광학 문자 인식(OCR)은 컴퓨터 비전 기술의 한 분야로, 텍스트 이미지를 컴퓨터가 읽을 수 있는 텍스트 포맷으로 변환하는 기술입니다. 텍스트 편집기를 사용할 수 없는 이미지 파일을 텍스트 문서로 변환하여 내용을 편집 및 검색, 단어 수를 계산할 수 있도록 만들 수 있습니다.
- OCR은 Text detection 모델과 Text recognition 모델의 결합으로, Classification과 Detection, Segmentation 기법이 결합된 형태입니다. 최근에는 두 가지 모두를 동시에 해내는 End-to-end 모델 개발이 성행하고 있습니다. 또한 머신러닝 기반의 알고리즘을 활용하면서 인식률이 크게 높아졌습니다. 또한 딥러닝을 적용해 정확도가 향상된 것을 확인할 수 있습니다.
- OCR 데이터 품질을 높이기 위한 방법 중 Popeval 기술을 적용한 평가 방법은 Split, Merge 등의 문제 해결에 효과적입니다. 데이터헌트는 주로 AI-assisted 기술로 AI와 사람이 협업하는 구조를 만들었으며, 이미지 전처리 과정에서 사람의 개입을 통해 작업 시간 개선 및 정확도 개선의 성과를 거두었습니다.
'say와 AI 챗봇친구 만들기 보고서' 카테고리의 다른 글
| ChatGPT의 학습방법 (0) | 2023.10.15 |
|---|---|
| AI의 역사 (0) | 2023.10.15 |
| 생성형 AI 챗봇 GPT 실패의 원인과 해결방안 분석 (0) | 2023.10.15 |
| 챗GPT로 효율적인 마케팅 자동화 및 콘텐츠 관리 전략 (2) | 2023.10.14 |
| ‘챗GPT·클로바·바드’ 세 AI에 물어보니 ① 그것들은 만능이 아니다 ② 틀리거나 거짓말도 한다 ③ 상호 보완적 관계다 (2) | 2023.10.14 |



