
대화형 사용자 경험
Bot Framework Composer를 사용하면 제작자가 대화형 봇, 가상 에이전트, 디지털 비서 및 기타 모든 대화 인터페이스를 설계할 수 있으므로 유연하고 액세스 가능하며 강력한 방식으로 고객, 직원 및 서로 연결할 수 있습니다. 초보 디자이너이든 베테랑 개발자이든 이 섹션에서 설명하는 개념은 많은 비즈니스 시나리오를 다루는 효과적이고 책임감 있고 포용적이며 즐거운 경험을 만드는 데 도움이 되는 통찰력을 제공할 것입니다.
우리는 CUX(대화형 사용자 경험)를 자연어를 기반으로 하는 상호 작용 양식으로 정의합니다. 서로 상호 작용할 때 인간은 아이디어, 개념, 데이터 및 감정 정보를 전달하기 위해 대화를 사용합니다. CUX를 사용하면 자연스럽게 나오는 음성 및 텍스트 또는 채팅을 통해 문구와 구문을 사용하여 서로 통신하는 방식으로 장치, 앱 및 디지털 서비스와 상호 작용할 수 있습니다.

명령줄의 구문, 그래픽 사용자 인터페이스의 정보 아키텍처 또는 장치의 터치 어포던스와 같은 다른 양식은 시스템에 의미 있는 상호 작용 동작을 학습하는 작업으로 사용자에게 부담을 줄 수 있습니다. CUX는 판도를 뒤집습니다. 사용자가 시스템을 배워야 하는 것이 아니라 시스템이 배우는 것입니다. 우리가 인간의 언어에 대해 가르치는 내용(말의 패턴, 구어체, 잡담, 심지어 욕설까지)을 학습하여 적절하게 대응할 수 있습니다.
훌륭한 대화형 봇
대부분의 성공적인 봇에는 최소한 한 가지 공통점이 있습니다. 훌륭한 대화식 사용자 경험입니다. CUX는 시각적, 청각적 또는 터치 지원 구성 요소를 포함하거나 포함하지 않고 텍스트 또는 음성을 사용하는 다중 모드일 수 있습니다. 그러나 기본적으로 CUX는 인간의 언어입니다.
팁
만들고 있는 봇 유형에 관계없이 CUX를 최우선 순위로 두십시오.
봇을 설계하는 경우 사용자가 앱, 웹 사이트, 실시간 에이전트와의 전화 통화 및 특정 쿼리를 처리하는 기타 수단과 같은 대체 환경보다 봇 환경을 선호한다고 가정합니다. 따라서 훌륭한 대화식 사용자 경험을 보장하는 것이 봇을 설계할 때 최우선 순위가 되어야 합니다. 몇 가지 주요 고려 사항은 다음과 같습니다.
봇이 최소한의 왕복으로 사용자의 문제를 쉽게 해결합니까?
봇이 다른 경험보다 사용자의 문제를 더 잘/쉽게/빠르게 해결합니까?
봇이 사용자가 관심을 갖는 장치 및 플랫폼에서 실행됩니까?
봇이 검색 가능하고 호출하기 쉬운가요?
사용자가 막혔을 때 봇이 사용자를 안내합니까? 라이브 에이전트에게 인계하거나 관련 도움을 제공함으로써?
사용자는 봇이 쿼리를 해결하는 것을 중요하게 생각합니다. 훌륭한 대화형 봇은 사용자가 너무 많이 입력하거나, 너무 많이 말하거나, 여러 번 반복하거나, 봇이 자동으로 알고 기억해야 하는 사항을 설명할 필요가 없습니다.
CUX 가이드
CUX 가이드에는 봇 설계에 대한 지침이 포함되어 있습니다. 이 지침은 모범 사례와 일치하며 배운 교훈을 활용합니다. 이 지침의 작성자와 디자이너는 다양한 봇, 가상 에이전트 및 Cortana, Bot Framework Templates, Microsoft Virtual Assistant, Personality Chat 등을 비롯한 기타 대화형 경험 프로젝트를 위한 대화형 UX를 구축하고 배포한 수십 년간의 경험을 바탕으로 합니다.
팁
CUX 가이드 Microsoft.pdf 다운로드
이 CUX 가이드는 느슨하게 몇 가지 다른 섹션으로 나뉩니다.
CUX, 윤리 및 포괄적 디자인에 대한 소개.
계획 및 디자인을 위한 브레인스토밍 워크시트 및 지침.
CUX 경험 구축을 위한 실용적인 개발 팁.
항목을 순서대로 읽거나 필요에 맞는 영역으로 이동하십시오.
메모
용어에 대한 참고 사항: 이 가이드는 봇, 가상 에이전트 및 디지털 도우미를 포함한 여러 종류의 대화 경험을 탐색합니다. 이 지침의 CUX 설계 원칙이 모두에게 적용되기 때문에 이러한 용어를 비교적 상호 교환적으로 사용하지만 업계에서 차이점이 있음을 인식합니다. 우리의 의도는 의도와 관계없이 대부분의 텍스트 기반 대화 경험에 도움이 되는 지침을 제공하는 것입니다.
대화형 경험에서 생성 AI 탐색: Amazon Lex, Langchain 및 SageMaker Jumpstart 소개
Marcelo Silva , Kanjana Chandren , Justin Leto , Mahesh Biradar , Ryan Gomes , Victor Rojo 작성 | ~에 2023년 6월 8일| Amazon Lex , Amazon SageMaker , Amazon SageMaker JumpStart , 인공 지능 , 생성 AI , 기술 사용 방법 | 퍼머링크 | 댓글 | 공유하다
오늘날의 급변하는 세상에서 고객은 비즈니스로부터 신속하고 효율적인 서비스를 기대합니다. 그러나 우수한 고객 서비스를 제공하는 것은 질문의 양이 이를 해결하기 위해 고용된 인적 자원을 능가할 때 상당히 어려울 수 있습니다. 그러나 기업은 대규모 언어 모델(LLM)로 구동되는 생성 인공 지능(Generative AI)의 발전을 통해 개인화되고 효율적인 고객 서비스를 제공하면서 이러한 문제를 해결할 수 있습니다.
생성 AI 챗봇은 인간의 지능을 모방하는 능력으로 악명을 얻었습니다. 그러나 작업 지향 봇과 달리 이러한 봇은 텍스트 분석 및 콘텐츠 생성에 LLM을 사용합니다. LLM은 2017년 6월에 소개된 딥 러닝 신경망인 트랜스포머 아키텍처를 기반으로 하며 레이블이 지정되지 않은 방대한 텍스트 코퍼스에서 훈련할 수 있습니다. 이 접근 방식은 보다 인간적인 대화 경험을 생성하고 여러 주제를 수용합니다.
이 글을 쓰는 시점에서 모든 규모의 회사는 이 기술을 사용하기를 원하지만 어디서부터 시작해야 할지 파악하는 데 도움이 필요합니다. 생성 AI를 시작하고 대화형 AI에서 LLM을 사용하려는 경우 이 게시물이 적합합니다. 사전 훈련된 오픈 소스 LLM을 사용하는 Amazon Lex 봇을 빠르게 배포하기 위한 샘플 프로젝트를 포함했습니다 . 이 코드에는 사용자 정의 메모리 관리자를 구현하기 위한 시작점도 포함되어 있습니다. 이 메커니즘을 통해 LLM은 대화의 맥락과 속도를 유지하기 위해 이전 상호 작용을 기억할 수 있습니다. 마지막으로 일관된 결과를 얻기 위해 미세 조정 프롬프트와 LLM 임의성 및 결정성 매개 변수를 실험하는 것이 중요하다는 점을 강조하는 것이 중요합니다.
솔루션 개요
이 솔루션은 Amazon SageMaker 엔드포인트를 통해 액세스할 수 있는 Amazon SageMaker JumpStart 의 인기 있는 오픈 소스 LLM과 Amazon Lex 봇을 통합합니다 . 또한 LLM 기반 애플리케이션을 단순화하는 인기 있는 프레임워크인 LangChain을 사용합니다. 마지막으로 QnABot을 사용하여 챗봇용 사용자 인터페이스를 제공합니다.
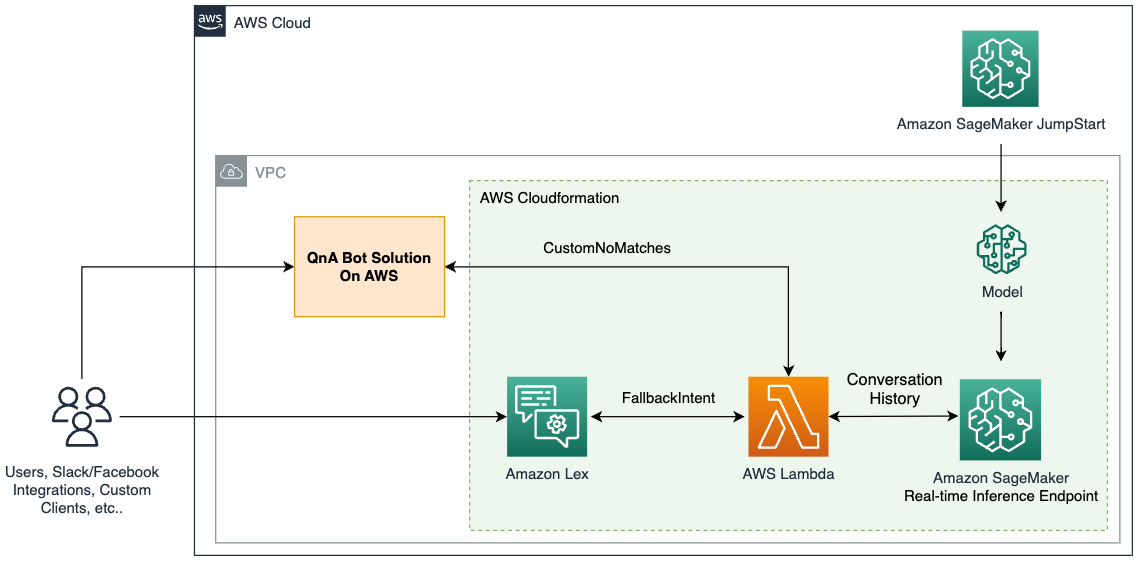
먼저 앞의 다이어그램에서 각 구성 요소를 설명하는 것으로 시작합니다.
JumpStart는 다양한 문제 유형에 대해 사전 훈련된 오픈 소스 모델을 제공합니다. 이를 통해 기계 학습(ML)을 빠르게 시작할 수 있습니다. 여기에는 딥 러닝 컨테이너에 배포된 LLM인 FLAN-T5-XL 모델이 포함됩니다. 텍스트 생성을 포함한 다양한 자연어 처리(NLP) 작업에서 잘 수행됩니다.
SageMaker 실시간 추론 엔드포인트는 이벤트 예측을 위한 ML 모델의 빠르고 확장 가능한 배포를 지원합니다. Lambda 함수와 통합할 수 있는 기능을 통해 엔드포인트에서 사용자 지정 애플리케이션을 구축할 수 있습니다.
AWS Lambda 함수는 Amazon Lex 봇 또는 QnABot 의 요청을 사용하여 LangChain을 사용하여 SageMaker 엔드포인트를 호출하기 위한 페이로드를 준비합니다 . LangChain은 개발자가 LLM으로 구동되는 애플리케이션을 만들 수 있는 프레임워크입니다.
Amazon Lex V2 봇에는 내장 AMAZON.FallbackIntent의도 유형이 있습니다. 사용자 입력이 봇의 의도와 일치하지 않을 때 트리거됩니다.
QnABot은 Amazon Lex 봇에 사용자 인터페이스를 제공하는 오픈 소스 AWS 솔루션입니다. 항목 에 대한 Lambda 후크 함수 로 구성했으며 CustomNoMatchesQnABot이 답변을 찾을 수 없을 때 Lambda 함수를 트리거합니다. 이미 배포했으며 다음 섹션에서 구성 단계를 포함했다고 가정합니다.
솔루션은 다음 시퀀스 다이어그램에서 높은 수준으로 설명됩니다.
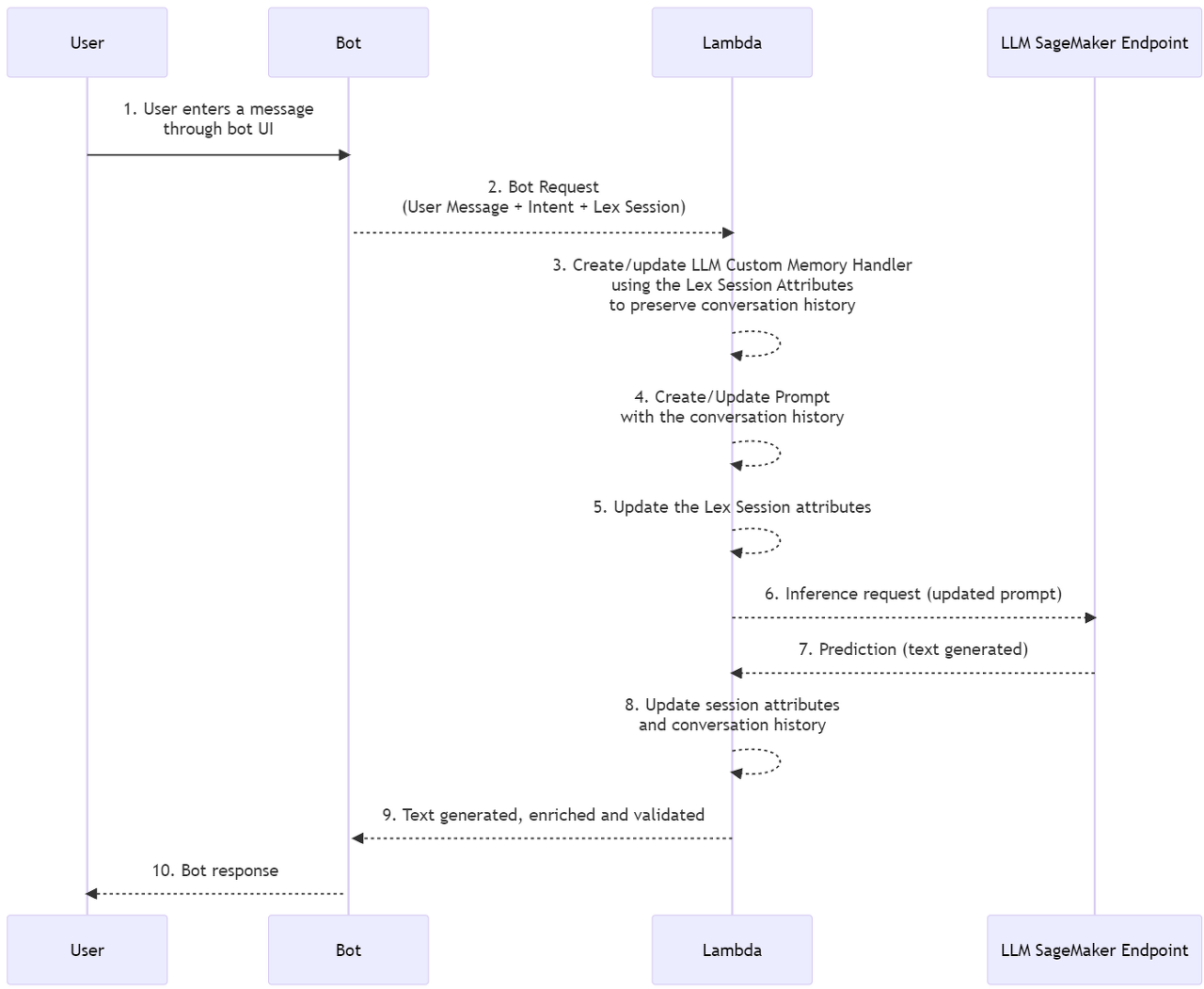
솔루션이 수행하는 주요 작업
이 섹션에서는 솔루션에서 수행되는 주요 작업을 살펴봅니다. 이 솔루션의 전체 프로젝트 소스 코드는 이 GitHub 리포지토리 에서 참조할 수 있습니다 .
챗봇 대체 처리
AMAZON.FallbackIntentLambda 함수는 Amazon Lex V2 및 CustomNoMatchesQnABot의 항목을 통해 "모름" 답변을 처리합니다 . 트리거되면 이 함수는 세션 요청과 폴백 인텐트를 확인합니다. 일치하는 항목이 있으면 요청을 Lex V2 디스패처로 전달합니다. 그렇지 않으면 QnABot 디스패처가 요청을 사용합니다. 다음 코드를 참조하십시오.
|
def dispatch_lexv2(request): """Summary Args: request (dict): Lambda event containing a user's input chat message and context (historical conversation) Uses the LexV2 sessions API to manage past inputs https://docs.aws.amazon.com/lexv2/latest/dg/using-sessions.html Returns: dict: Description """ lexv2_dispatcher = LexV2SMLangchainDispatcher(request) return lexv2_dispatcher.dispatch_intent() def dispatch_QnABot(request): """Summary Args: request (dict): Lambda event containing a user's input chat message and context (historical conversation) Returns: dict: Dict formatted as documented to be a lambda hook for a "don't know" answer for the QnABot on AWS Solution see https://docs.aws.amazon.com/solutions/latest/QnABot-on-aws/specifying-lambda-hook-functions.html """ request['res']['message'] = "Hi! This is your Custom Python Hook speaking!" qna_intent_dispatcher = QnASMLangchainDispatcher(request) return qna_intent_dispatcher.dispatch_intent() def lambda_handler(event, context): print(event) if 'sessionState' in event: if 'intent' in event['sessionState']: if 'name' in event['sessionState']['intent']: if event['sessionState']['intent']['name'] == 'FallbackIntent': return dispatch_lexv2(event) else: return dispatch_QnABot(event)
|
LLM에 메모리 제공
다중 전환 대화에서 LLM 메모리를 보존하기 위해 Lambda 함수에는 Amazon Lex V2 세션 API를 사용하여 진행 중인 다중 전환 대화 메시지로 세션 속성을 추적하고 컨텍스트를 제공하는 LangChain 사용자 지정 메모리 클래스 메커니즘이 포함되어 있습니다. 이전 상호작용을 통한 대화형 모델. 다음 코드를 참조하십시오.
|
class LexConversationalMemory(BaseMemory, BaseModel): """Langchain Custom Memory class that uses Lex Conversation history Attributes: history (dict): Dict storing conversation history that acts as the Langchain memory lex_conv_context (str): LexV2 sessions API that serves as input for convo history Memory is loaded from here memory_key (str): key to for chat history Langchain memory variable - "history" """ history = {} memory_key = "chat_history" #pass into prompt with key lex_conv_context = "" def clear(self): """Clear chat history """ self.history = {} @property def memory_variables(self) -> List[str]: """Load memory variables Returns: List[str]: List of keys containing Langchain memory """ return [self.memory_key] def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, str]: """Load memory from lex into current Langchain session memory Args: inputs (Dict[str, Any]): User input for current Langchain session Returns: Dict[str, str]: Langchain memory object """ input_text = inputs[list(inputs.keys())[0]] ccontext = json.loads(self.lex_conv_context) memory = { self.memory_key: ccontext[self.memory_key] + input_text + "\nAI: ", } return memory
|
다음은 LangChain ConversationChain에서 사용자 지정 메모리 클래스를 도입하기 위해 만든 샘플 코드입니다.
|
# Create a conversation chain using the prompt, # llm hosted in Sagemaker, and custom memory class self.chain = ConversationChain( llm=sm_flant5_llm, prompt=prompt, memory=LexConversationalMemory(lex_conv_context=lex_conv_history), verbose=True )
|
신속한 정의
LLM에 대한 프롬프트는 생성된 응답의 톤을 설정하는 질문 또는 진술입니다. 프롬프트는 관련 응답을 생성하도록 모델을 지시하는 데 도움이 되는 컨텍스트의 한 형태로 기능합니다. 다음 코드를 참조하십시오.
|
# define prompt prompt_template = """The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know. You are provided with information about entities the Human mentions, if relevant. Chat History: {chat_history} Conversation: Human: {input} AI:"""
|
LLM 메모리 지원을 위해 Amazon Lex V2 세션 사용
Amazon Lex V2는 사용자가 봇과 상호 작용할 때 세션을 시작합니다. 세션은 수동으로 중지하거나 시간 초과되지 않는 한 시간이 지나도 지속됩니다. 세션은 메타데이터와 세션 속성으로 알려진 애플리케이션별 데이터를 저장합니다. Amazon Lex는 Lambda 함수가 세션 속성을 추가하거나 변경할 때 클라이언트 애플리케이션을 업데이트합니다. QnABot에는 Amazon Lex V2에서 세션 속성을 설정하고 가져오는 인터페이스가 포함되어 있습니다.
코드에서 우리는 이 메커니즘을 사용하여 대화 기록을 추적하고 LLM이 단기 및 장기 상호 작용을 기억할 수 있도록 LangChain에 사용자 지정 메모리 클래스를 구축했습니다. 다음 코드를 참조하십시오.
|
class LexV2SMLangchainDispatcher(): def __init__(self, intent_request): # See lex bot input format to lambda https://docs.aws.amazon.com/lex/latest/dg/lambda-input-response-format.html self.intent_request = intent_request self.localeId = self.intent_request['bot']['localeId'] self.input_transcript = self.intent_request['inputTranscript'] # user input self.session_attributes = utils.get_session_attributes( self.intent_request) self.fulfillment_state = "Fulfilled" self.text = "" # response from endpoint self.message = {'contentType': 'PlainText','content': self.text} class QnABotSMLangchainDispatcher(): def __init__(self, intent_request): # QnABot Session attributes self.intent_request = intent_request self.input_transcript = self.intent_request['req']['question'] self.intent_name = self.intent_request['req']['intentname'] self.session_attributes = self.intent_request['req']['session']
|
전제 조건
배포를 시작하려면 다음 전제 조건을 충족해야 합니다.
AWS CloudFormation 스택을 시작할 수 있는 사용자를 통해 AWS Management Console 에 액세스
Lambda 및 Amazon Lex 콘솔 탐색에 익숙함
솔루션 배포
솔루션을 배포하려면 다음 단계를 진행하십시오.
스택 시작을 선택하여 리전 에서 솔루션을 시작합니다 us-east-1.
스택 이름 에 고유한 스택 이름을 입력합니다.
HFModel 의 경우 JumpStart에서 사용 가능한 모델을 사용합니다 Hugging Face Flan-T5-XL.
HFTask 에 를 입력합니다 text2text.
S3BucketName을 그대로 유지합니다 .
이는 솔루션을 배포하는 데 필요한 Amazon Simple Storage Service (Amazon S3) 자산을 찾는 데 사용되며 이 게시물에 대한 업데이트가 게시되면 변경될 수 있습니다.
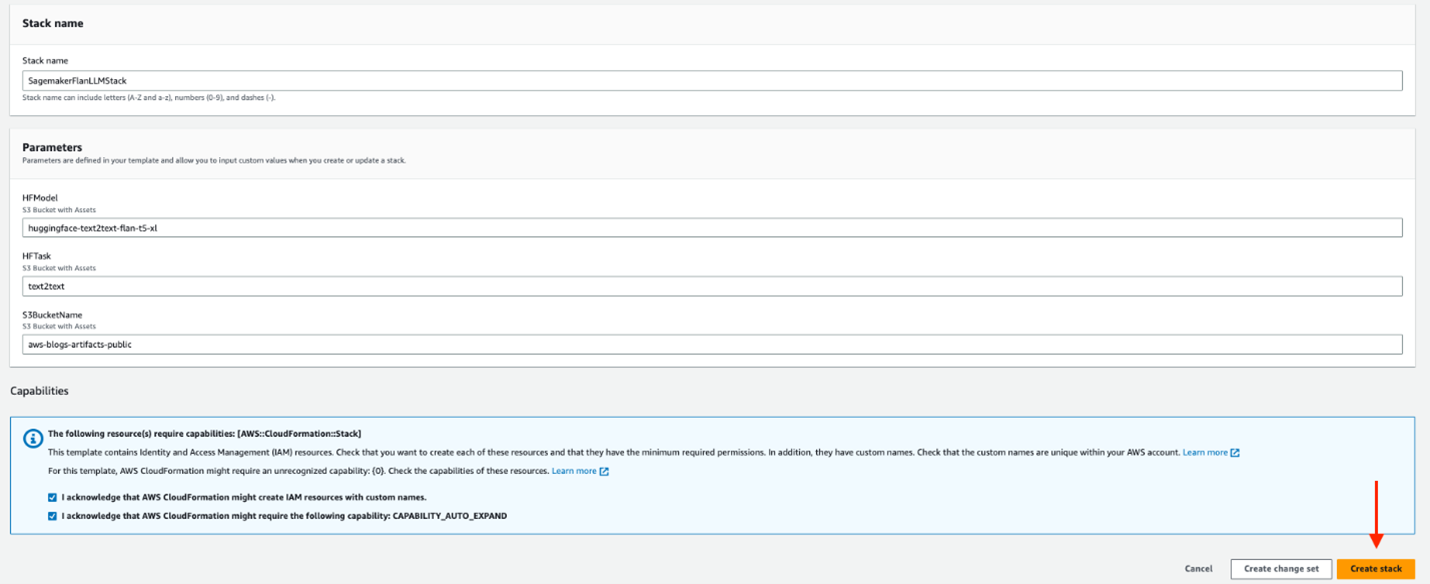
능력을 인정하십시오.
스택 생성을 선택합니다 .
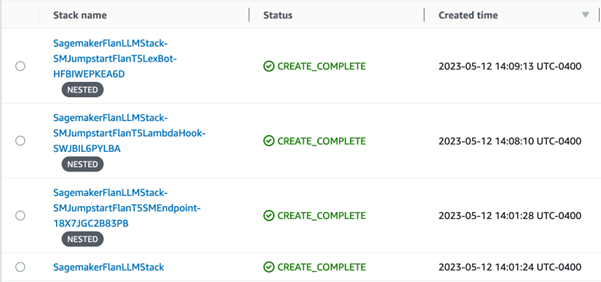
4개의 성공적으로 생성된 스택이 있어야 합니다.
Amazon Lex V2 봇 구성
Amazon Lex V2 봇과는 아무런 관련이 없습니다. CloudFormation 템플릿은 이미 어려운 작업을 수행했습니다.
QnABot 구성
환경에 기존 QnABot이 이미 배포되어 있다고 가정합니다. 그러나 도움이 필요한 경우 다음 지침에 따라 배포하십시오.
AWS CloudFormation 콘솔에서 배포한 기본 스택으로 이동합니다.
출력 탭 에서 LambdaHookFunctionArn나중에 QnABot에 삽입해야 하므로 기록해 둡니다 .

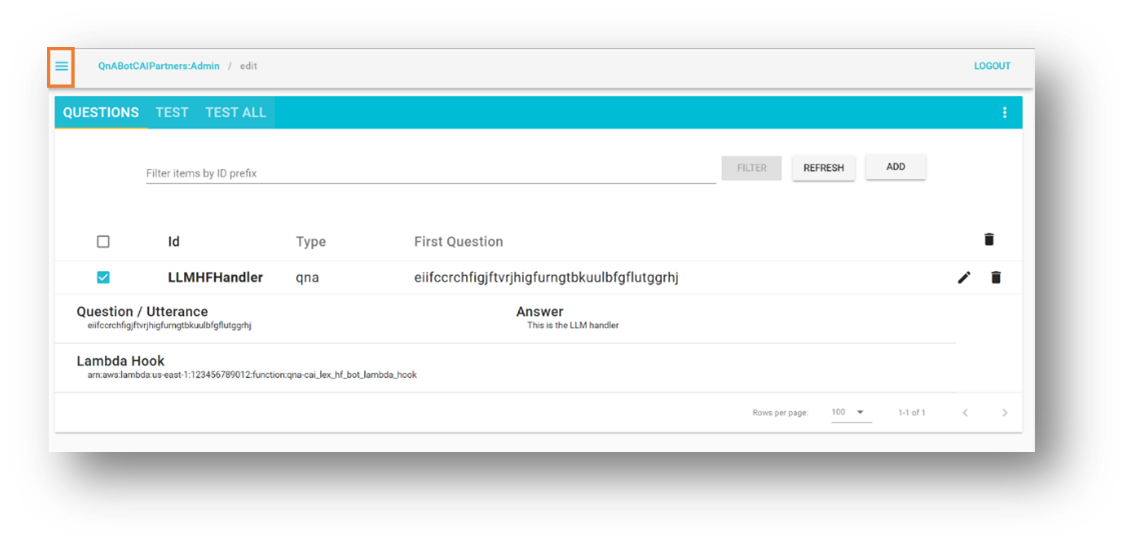
QnABot Designer 사용자 인터페이스(UI) 에 관리자로 로그인합니다 .
질문 UI 에서 새 질문을 추가합니다.
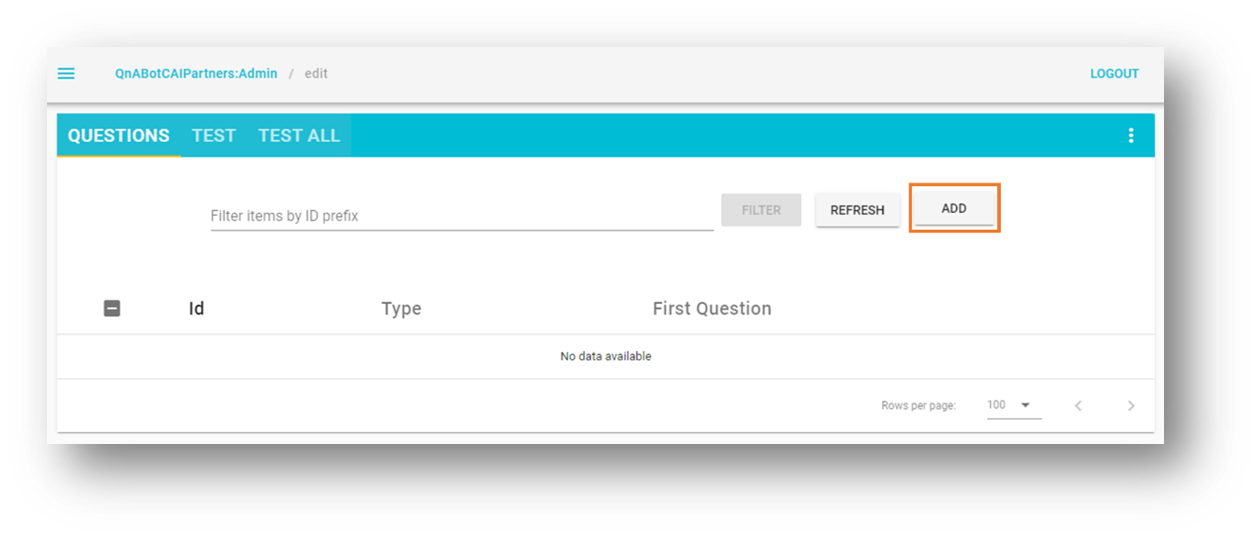
다음 값을 입력합니다.
아이디 –CustomNoMatches
질문 –no_hits
답변 – "모름"에 대한 기본 답변
고급을 선택 하고 Lambda 후크 섹션으로 이동합니다.
앞에서 기록한 Lambda 함수의 Amazon 리소스 이름(ARN)을 입력합니다.
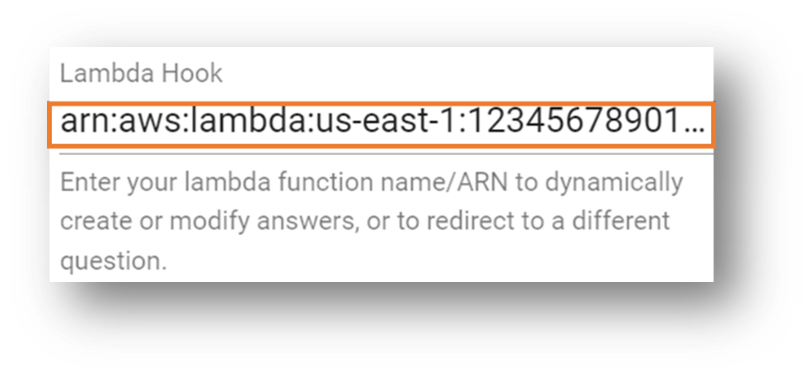
섹션 하단으로 스크롤하고 생성을 선택합니다.
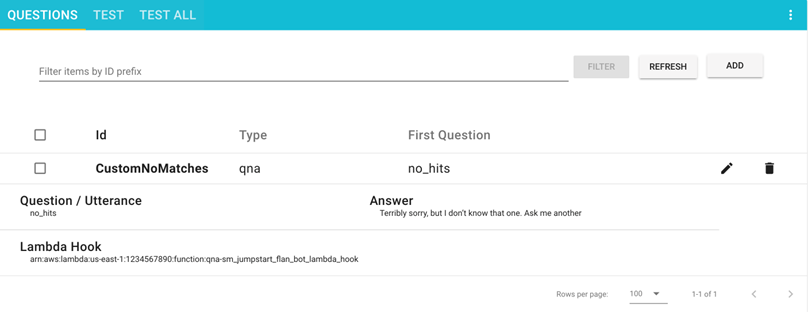
성공 메시지가 있는 창이 나타납니다.

이제 귀하의 질문이 질문 페이지 에 표시됩니다 .
솔루션 테스트
솔루션 테스트를 진행해 보겠습니다. 먼저 JumpStart에서 제공하는 FLAN-T5-XL 모델을 미세 조정 없이 배포했다는 점을 언급할 가치가 있습니다. 이것은 약간의 예측 불가능성을 가질 수 있으며 응답에 약간의 변화가 생길 수 있습니다.
Amazon Lex V2 봇으로 테스트
이 섹션은 SageMaker 엔드포인트에 배포된 LLM을 호출하는 Lambda 함수와 Amazon Lex V2 봇 통합을 테스트하는 데 도움이 됩니다.
Amazon Lex 콘솔에서 봇으로 이동합니다 Sagemaker-Jumpstart-Flan-LLM-Fallback-Bot.
이 봇은 일치하는 다른 의도가 없을 때 폴백 의도로 LLM을 호스팅하는 SageMaker 엔드포인트를 호출하는 Lambda 함수를 호출하도록 구성되었습니다.
탐색 창에서 의도를 선택합니다 .
오른쪽 상단에 "English (US) has not build changes."라는 메시지가 표시됩니다.
빌드를 선택합니다 .
완료될 때까지 기다리십시오.
마지막으로 다음 스크린샷과 같이 성공 메시지가 나타납니다.
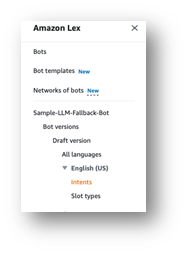
테스트를 선택합니다 .
모델과 상호 작용할 수 있는 채팅 창이 나타납니다.
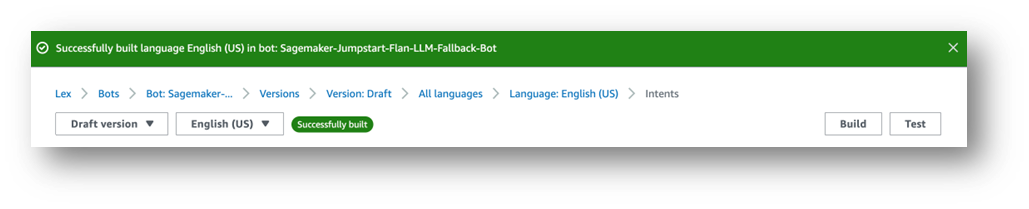
Amazon Lex 봇 과 Amazon Connect 간의 기본 통합을 살펴보는 것이 좋습니다 . 또한 예를 들어 Amazon Chime SDK 및 Genesys Cloud를 사용하는 메시징 플랫폼(Facebook, Slack, Twilio SMS) 또는 타사 Contact Center도 있습니다.
QnABot 인스턴스로 테스트
이 섹션에서는 SageMaker 엔드포인트에 배포된 LLM을 호출하는 Lambda 함수와 QnABot on AWS 통합을 테스트합니다.
왼쪽 상단 모서리에 있는 도구 메뉴를 엽니다.
QnABot 클라이언트를 선택합니다 .
관리자로 로그인을 선택합니다 .
사용자 인터페이스에 질문을 입력하십시오.
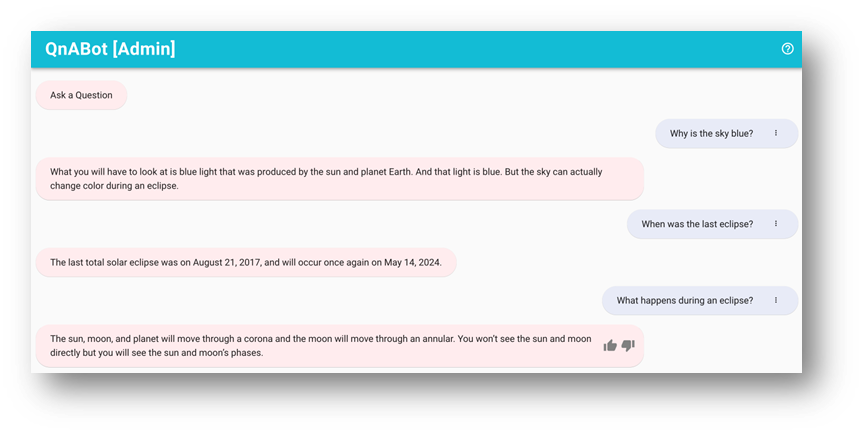
응답을 평가합니다.
청소
향후 비용이 발생하지 않도록 하려면 다음 단계에 따라 솔루션에서 생성한 리소스를 삭제하십시오.
AWS CloudFormation 콘솔에서 이름이 지정된 스택 SagemakerFlanLLMStack(또는 스택에 설정한 사용자 지정 이름)을 선택합니다.
테스트를 위해 QnABot 인스턴스를 배포한 경우 QnABot 스택을 선택합니다.
결론
이 게시물에서는 사용자 요청을 오픈 소스 대규모 언어 모델로 라우팅하는 작업 지향 봇에 오픈 도메인 기능을 추가하는 방법을 살펴보았습니다.
다음을 권장합니다.
대화 기록을 외부 지속성 메커니즘에 저장합니다 . 예를 들어 대화 기록을 Amazon DynamoDB 또는 S3 버킷에 저장하고 Lambda 함수 후크에서 검색할 수 있습니다. 이렇게 하면 Amazon Lex에서 제공하는 내부 비영구 세션 속성 관리에 의존할 필요가 없습니다.
요약 실험 – 다자간 대화에서 컨텍스트를 추가하고 대화 기록의 사용을 제한하기 위해 프롬프트에서 사용할 수 있는 요약을 생성하는 것이 유용합니다. 이렇게 하면 봇 세션 크기를 정리하고 Lambda 함수 메모리 소비를 낮게 유지하는 데 도움이 됩니다.
프롬프트 변형으로 실험 – 실험 목적과 일치하는 원래 프롬프트 설명을 수정합니다.
최적의 결과를 위한 언어 모델 적용 – 애플리케이션에 따라 임의성( temperature) 및 결정성( ) 과 같은 고급 LLM 매개변수를 미세 조정하여 이를 수행할 수 있습니다 . top_p샘플 값이 포함된 사전 학습된 모델을 사용하여 샘플 통합을 시연했지만 사용 사례에 맞게 값을 조정하는 재미가 있습니다.
다음 게시물에서는 사전 훈련된 LLM 기반 챗봇을 자신의 데이터로 미세 조정하는 방법을 발견하도록 도울 계획입니다.
AWS에서 LLM 챗봇을 실험하고 있습니까? 댓글로 자세히 알려주세요!
저자 소개

Marcelo Silva 는 최첨단 제품을 설계, 개발 및 구현하는 데 뛰어난 숙련된 기술 전문가입니다. Cisco에서 경력을 시작하면서 Marcelo는 최초의 캐리어 라우팅 시스템 배포 및 ASR9000의 성공적인 출시를 포함하여 다양한 유명 프로젝트에 참여했습니다. GenAI에 합류하기 전에는 Cisco, Cape Networks 및 AWS와 같은 여러 회사에서 수석 관리자로 재직하면서 그의 전문 지식은 클라우드 기술, 분석 및 제품 관리로 확장됩니다. 현재 Conversational AI/GenAI 제품 관리자로 일하고 있는 Marcelo는 산업 전반에 걸쳐 혁신적인 솔루션을 제공하는 데 계속해서 탁월합니다.

Victor Rojo 는 최신 AI, ML 및 소프트웨어 개발에 열정을 가진 경험이 풍부한 기술자입니다. 그는 전문 지식을 바탕으로 Amazon Alexa를 미국 및 멕시코 시장에 도입하는 데 중추적인 역할을 했으며, AWS 파트너에게 Amazon Textract 및 AWS Contact Center Intelligence(CCI)를 성공적으로 출시하는 데 앞장섰습니다. Conversational AI Competency Partners 프로그램의 현재 수석 기술 리더인 Victor는 혁신을 주도하고 업계의 변화하는 요구 사항을 충족하는 최첨단 솔루션을 제공하는 데 전념하고 있습니다.

Justin Leto 는 기계 학습을 전문으로 하는 Amazon Web Services의 선임 솔루션 아키텍트입니다. 그의 열정은 고객이 머신 러닝과 AI의 힘을 활용하여 비즈니스 성장을 주도하도록 돕는 것입니다. Justin은 AWS Summit을 포함한 글로벌 AI 컨퍼런스에서 발표하고 대학에서 강의했습니다. 그는 NYC 기계 학습 및 AI 모임을 이끌고 있습니다. 여가 시간에는 연안 항해와 재즈 연주를 즐깁니다. 그는 아내와 어린 딸과 함께 뉴욕시에 살고 있습니다.

Ryan Gomes 는 AWS Professional Services Intelligence Practice의 데이터 및 ML 엔지니어입니다. 그는 고객이 클라우드에서 분석 및 기계 학습 솔루션을 통해 더 나은 결과를 얻을 수 있도록 돕는 일에 열정적입니다. 직장 밖에서는 피트니스, 요리, 친구 및 가족과 함께 좋은 시간을 보내는 것을 즐깁니다.

Mahesh Birardar 는 DevOps 및 Observability를 전문으로 하는 Amazon Web Services의 선임 솔루션 아키텍트입니다. 그는 고객이 확장 가능한 비용 효율적인 아키텍처를 구현하도록 돕는 일을 즐깁니다. 일 외에는 영화 감상과 하이킹을 즐깁니다.

Kanjana Chandren은 Amazon Web Services(AWS)의 솔루션 아키텍트로 기계 학습에 열정을 가지고 있습니다. 그녀는 고객이 AWS 워크로드를 설계, 구현 및 관리하도록 돕습니다. 직장 밖에서 그녀는 여행, 독서, 가족 및 친구들과 시간을 보내는 것을 좋아합니다.
코멘트
대화 디자인은 UX의 미래입니다
대규모로 고객과 더 나은 관계를 구축하는 대화를 설계하는 방법을 살펴보세요.
동사로 시작
봇 작업을 하는 누군가가 “하지만 주제는 어떻습니까? 봇이 주제에 집중할 수 있습니까? 봇은 어떤 주제를 다룰까요?” 불행히도 주제는 전체의 절반에 불과합니다. 대화는 또한 행동에 관한 것입니다. 사용자가 무엇을 하려고 하는지 고려하지 않고서는 실제로 사용자를 위해 대규모 작업을 완료할 수 없습니다.
다른 언어를 배우려고 한다고 상상해 보십시오. 여기서는 요거트를 예로 들어 보겠습니다(안 되는 이유는 무엇입니까?). 요구르트에 대해 이야기하는 방법을 배우고 싶지는 않을 것입니다. 당신은 그것을 사고, 비판하고, 칭찬하는 방법을 알고 싶을 것입니다. 이 예에서 요구르트는 주제이고 동사는 주제와 관련된 동작을 전달합니다.
CxD의 맥락에서 사용자는 어떤 문제를 해결하기 위해 항상 봇에 올 것입니다(그들은 아마도 어울리기 위해 거기에 있지 않을 것입니다). 따라서 예를 들어 사용자가 담당자와 대화를 원할 경우 문제를 신속하게 해결하도록 돕기 위해 단순히 "대표"라고 말하는 프롬프트는 불완전하고 도움이 되지 않습니다. 그러나 “대표와 상의하라”는 지시는 분명하다.
시작하려면 일상 생활에서 언어를 활성화할 기회를 찾으십시오. 다음에 앱이나 챗봇을 사용할 때 대화를 시작하기 위해 동사를 사용하는지 알아차리시겠습니까? 그렇지 않다면 그러한 상황에서 어떤 동사를 사용하시겠습니까?
담화 마커 사용
여기서 "담화"라는 단어에 겁먹지 마십시오. 그것은 단지 서면 또는 구두 의사 소통을 의미합니다. 이 경우 "so", "uh" 및 "oh"와 같이 종종 필러 단어로 오인되는 단어에 대해 이야기하고 있습니다. 불필요한 것처럼 보일 수 있지만 담화 마커는 실제로 대화 언어의 기둥 중 하나입니다. 대화의 자연스러운 흐름을 만드는 데 정말 중요합니다.
담화 마커는 서로 다른 문장과 아이디어 사이의 응집력과 이들이 서로 어떻게 관련되어 있는지를 보여줍니다(Schiffrin, 1987). 그것들을 접속사로 생각할 수 있습니다. 예를 들어 "and"를 사용하면 아이디어를 기반으로 구축하고 있음을 의미합니다. 반면 "아직"은 두 가지를 비교하고 있음을 의미합니다. 이러한 연결 단어를 생략하는 것과 마찬가지로 담화 마커를 사용하지 않으면 봇이 경직되고 심지어 혼란스러워 보일 수 있습니다. 그러나 담화 마커를 포함하면 인간으로서의 자연스러운 대화와 더 유사한 경험을 디자인할 수 있습니다. 그리고 자연스러운 대화 경험을 만들어 고객과의 관계를 더욱 강화할 수 있습니다.
특히 음성 상호 작용에 적합합니다. 그리고 메시지가 붐비는 것을 피하기 위해 채팅 상호 작용에서 좀 더 드물게 사용합니다. 하지만 저는 이러한 금지된 담화 마커(흠, 어, 음)를 사용하지 않습니다. 기계가 할 수 없는 인지 처리를 의미하기 때문입니다.

담화 표지자 "오", "그래서", "글쎄", "좋아요" 목록과 대화에서 각각의 기능.
대화는 사람들과 협상하고 관계를 구축하는 통화입니다. 기본적으로 고객과 함께 구축한 성과인 협업입니다. CxD를 활용하면 브랜드에 대한 고객의 전반적인 경험에서 더 매력적이고 유익하며 궁극적으로 의미 있는 상호 교환을 만들 수 있습니다. 그리고 디자인에서 그들의 방언이나 대화 스타일을 축하함으로써 더 많은 사람들에게 다가갈 수 있습니다. 대화 디자인은 다른 어떤 디지털 경험도 할 수 없는 방식으로 더 긴밀한 관계를 자연스럽게 조성하기 때문에 UX의 미래입니다.
더 알고 싶으세요?
Trailhead 에서 Salesforce의 대화 디자인 모듈 과 관계 디자인 모듈을 확인하십시오 .
그리고 여기 당신의 CxD 관행을 알릴 수 있는 몇 가지 기사와 책이 있습니다!
새로운 DigitasLBi 조사에 따르면 미국인 3명 중 1명 이상이 Digitas 의 챗봇을 통해 구매할 의향이 있습니다 .
Deborah Shiffrin의 담론 마커 (Cambridge University Press, 1987).
Greg Bennett(UX Collective, 2019)의 아버지와 말을 하기 전의 자녀가 좋은 대화에 대해 가르쳐 줄 수 있는 것 .
대화 스타일: Deborah Schiffrin의 친구들 간의 대화 분석 (Oxford University Press, 1984).
Richard Nordquist의 대화에서 협력적 중첩 (ThoughtCo, 2020).
—
이 기사가 없었다면 Margaret Seelie, Madeline Davis, Adam Doti와 대화 디자인 Trailhead 모듈에 생명을 불어넣은 Noah Kravitz에게 많은 감사를 드립니다. 언어학 및 대화 디자인 분야에서 저의 북극성이 되어준 Deborah Tannen에게 깊은 감사를 드립니다. 삶을 변화시키는 연구를 통해 정의를 실현하고 완전히 새로운 청중에게 소개하게 되어 영광입니다. 이 작품은 매번 내가 가장 엉뚱한 연구 아이디어를 추구하도록 항상 격려해 준 Deborah Schiffrin을 기리기 위해 헌정되었습니다.
www.salesforce.com/design 에서 Salesforce 디자인에 대해 자세히 알아보십시오 .
Twitter에서 @SalesforceUX를 팔로우하십시오 .
Salesforce Lightning 디자인 시스템을 확인하십시오 .
NLP 대 NLU: 언어 이해에서 처리까지
AI가 발전하고 기술이 더욱 정교해짐에 따라 기존 기술도 진화할 것으로 기대합니다. 이러한 변화로 기반이 탄탄한 자연어 처리가 자연어 이해에 자리를 내줄까요? 아니면 두 개념이 AI에서 자신의 틈새를 잡기 위해 미묘하게 구별됩니까?
코멘트
By Sciforce , 과학 기반 정보 기술을 기반으로 하는 소프트웨어 솔루션.
인공 지능이 발전하고 기술이 더욱 정교해짐에 따라 기존 개념이 이러한 변화를 수용하거나 스스로 변화할 것으로 기대합니다. 마찬가지로 자연어의 컴퓨터 지원 처리 영역에서 자연어 처리의 개념이 자연어 이해에 자리를 내줄까요? 아니면 두 개념 사이의 관계가 단순히 기술의 선형적 진보보다 더 미묘하고 복잡합니까?
이 게시물에서는 NLP 및 NLU의 개념과 AI 관련 기술의 틈새에 대해 자세히 살펴보겠습니다.
중요한 것은 때때로 같은 의미로 사용되지만 일부 중복되는 두 가지 다른 개념입니다. 우선 둘 다 자연어와 인공지능의 관계를 다룬다. 둘 다 통계, 작업 등과 같은 구조화된 데이터와 달리 언어와 같은 구조화되지 않은 데이터를 이해하려고 시도합니다. 그러나 NLP와 NLU는 다른 많은 데이터 마이닝 기술과 반대입니다.
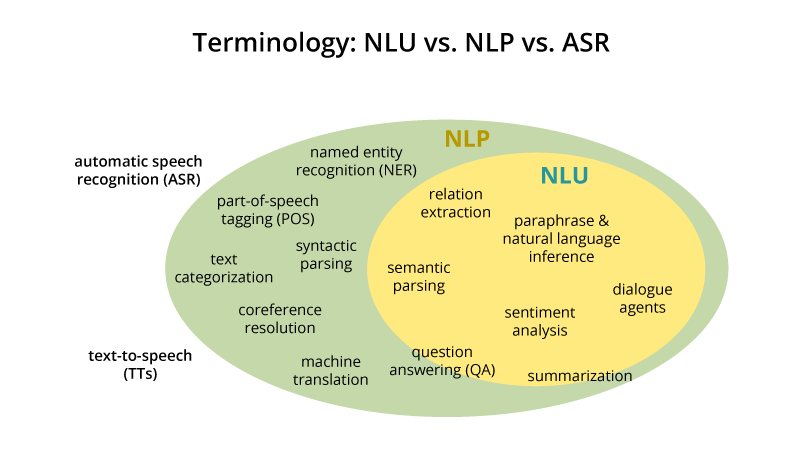
자연어 처리
NLP는 컴퓨터 과학, 인공 지능 및 점점 더 많은 데이터 마이닝의 단면에서 작동하는 이미 잘 확립된 수십 년 된 분야입니다. NLP의 궁극적인 목적은 기계가 인간의 언어를 읽고, 해독하고, 이해하고, 이해하여 인간의 특정 작업을 대신 기계가 처리하도록 하는 것입니다. 이러한 작업의 일반적인 실제 사례로는 온라인 챗봇, 텍스트 요약기, 자동 생성 키워드 탭, 주어진 텍스트의 감정을 분석하는 도구가 있습니다.
NLP가 하는 일
NLP는 가장 넓은 의미에서 음성 인식, 자연어 인식, 자연어 생성과 같은 광범위한 도구를 지칭할 수 있습니다. 그러나 역사적으로 NLP의 가장 일반적인 작업은 다음과 같습니다.
토큰화
파싱
정보 추출
유사성
음성 인식
자연 언어 및 음성 세대 및 기타 여러 가지.
실생활에서 NLP는 텍스트 요약, 감정 분석, 주제 추출, 명명된 엔터티 인식, 품사 태깅, 관계 추출, 형태소 분석, 텍스트 마이닝, 기계 번역 및 자동화된 질문 응답, 온톨로지 인구, 언어 모델링 및 우리가 생각할 수 있는 모든 언어 관련 작업.
NLP 기법
NLP의 두 기둥은 구문 분석과 의미 분석입니다.
요컨대 NLP는 기계 학습에 의존하여 텍스트 의미 체계 및 구문 분석을 통해 인간 언어에서 의미를 도출합니다.
자연어 이해
NLP는 컴퓨터 프로그래머가 간단한 언어 입력을 실험하기 시작한 1950년대로 거슬러 올라갈 수 있지만 NLU는 컴퓨터가 더 복잡한 언어 입력을 이해하게 하려는 욕구에서 1960년대에 개발되기 시작했습니다. NLP의 하위 주제로 간주되는 자연어는 목적이 더 좁으며 주로 기계 독해에 중점을 둡니다. 컴퓨터가 텍스트의 진정한 의미를 이해하도록 하는 것입니다.
NLU가 실제로 하는 일
NLP와 유사하게 NLU는 알고리즘을 사용하여 사람의 말을 구조화된 온톨로지로 줄입니다. 그런 다음 AI 알고리즘은 의도, 타이밍, 위치 및 감정과 같은 것을 감지합니다. 그러나 NLU 작업을 살펴보면 NLP가 이 개념에 얼마나 많이 구축되어 있는지 놀라게 될 것입니다.
NLU 작업.
자연어 이해는 텍스트 분류, 뉴스 수집, 개별 텍스트 보관 및 더 큰 규모의 콘텐츠 분석과 같은 많은 프로세스의 첫 번째 단계입니다. NLU의 실제 사례는 텍스트 이해를 기반으로 짧은 명령을 내리는 것과 같은 작은 작업부터 기본 구문과 적당한 크기의 어휘를 기반으로 이메일을 올바른 사람에게 다시 라우팅하는 것과 같은 작은 작업까지 다양합니다. 훨씬 더 복잡한 노력은 뉴스 기사나 시나 소설의 의미를 완전히 이해하는 것일 수 있습니다.
요컨대 NLU를 NLP를 달성하기 위한 첫 번째 단계로 보는 것이 가장 좋습니다. 기계가 언어를 처리하려면 먼저 언어를 이해해야 합니다 .
NLP와 NLU의 상관 관계
작업에서 알 수 있듯이 NLU는 자연어 처리의 필수적인 부분으로, 특정 텍스트가 렌더링하는 의미를 인간과 같은 방식으로 이해하는 역할을 합니다. NLP와 가장 큰 차이점 중 하나는 NLU가 잘못된 발음이나 문자 또는 단어의 전치와 같은 일반적인 인간 오류를 처리하는 의미를 해석하려고 하기 때문에 단어 이해를 넘어선다는 것입니다.
NLP를 추진해 온 가설은 Noam Chomsky가 1957년 Syntactic Structures에서 설정 한 가설 입니다 . L의 문장이 아니라 문법 시퀀스의 구조를 연구합니다.”
구문 분석은 단어 그룹에 문법 규칙을 적용하고 여러 기술에서 의미를 도출하여 언어가 문법 규칙과 어떻게 일치하는지 평가하기 위해 실제로 여러 작업에서 사용됩니다.
Lemmatization : 쉽게 분석할 수 있도록 단어의 변형된 형태를 단일 형태로 줄입니다.
형태소 분석 : 어근 형태로 변화된 단어를 절단합니다.
형태학적 세분화 : 단어를 형태소로 나누는 것.
단어 분할 : 연속된 텍스트를 별개의 단위로 나눕니다.
파싱(Parsing) : 문장의 문법적 분석.
품사 태깅 : 모든 단어의 품사를 식별합니다.
문장 끊기 : 연속된 텍스트에 문장 경계를 설정합니다.
구문 분석 기술.
그러나 문법적 정확성 또는 부정확성이 구문의 유효성과 항상 상관관계가 있는 것은 아닙니다. 무의미하지만 문법적인 문장인 "colorless green ideas sleep furiously"의 전형적인 예를 생각해 보십시오. 더욱이 실생활에서 의미 있는 문장은 종종 사소한 오류를 포함하고 비문법적인 것으로 분류될 수 있습니다. 인간의 상호 작용은 뛰어난 패턴 인식과 컨텍스트에서 추가 정보를 도출하여 생성된 텍스트 및 음성의 오류를 허용합니다. 이는 구문 중심 분석의 편향성과 다단계 의미 체계에 더 집중해야 할 필요성을 보여줍니다.
NLU의 핵심인 의미 분석은 단어의 의미와 해석을 이해하기 위해 컴퓨터 알고리즘을 적용하는 것으로 아직 완전히 해결되지 않았습니다.
다음은 몇 가지를 언급하자면 의미론적 분석의 몇 가지 기술입니다.
명명된 엔터티 인식(NER): 식별할 수 있는 텍스트 부분을 결정하고 미리 설정된 그룹으로 분류합니다.
단어 의미 명확화: 문맥에 따라 단어에 의미를 부여합니다.
자연어 생성 : 데이터베이스를 사용하여 의미론적 의도를 도출하고 이를 인간 언어로 변환합니다.
그러나 자연어를 완전히 이해하기 위해 기계는 시맨틱이 제공하는 문자 그대로의 의미뿐만 아니라 의도된 메시지 또는 텍스트가 달성하려는 내용에 대한 이해도 고려해야 합니다. 이 수준을 실용적인 분석 이라고 하며 NLU/NLP 기술에 도입되기 시작했습니다. 현재 우리는 감정 분석에서 어느 정도 그것을 볼 수 있습니다: 텍스트에 포함된 부정적/긍정적/중립적 감정의 평가.
NLP의 미래
인간과 같은 방식으로 인간과 상호 작용할 수 있는 챗봇을 만들고 최종적으로 Turing 테스트를 통과하기 위해 기업과 학계는 NLP 및 NLU 기술에 더 많은 투자를 하고 있습니다. 그들이 염두에 두고 있는 제품은 힘들이지 않고 감독되지 않으며 적절하고 성공적인 방식으로 사람들과 직접 상호 작용할 수 있는 것을 목표로 합니다.
이를 달성하기 위해 연구는 세 가지 수준에서 수행됩니다.
구문 — 텍스트의 문법을 이해합니다.
의미론 - 텍스트의 문자 그대로의 의미를 이해합니다.
Pragmatics — 텍스트가 달성하려는 것을 이해합니다.
불행히도 자연어를 이해하고 처리하는 것은 충분한 양의 어휘 세트를 제공하고 그것에 대해 기계를 훈련시키는 것만큼 간단하지 않습니다. NLP가 성공하려면 언어, 언어학, 인지 과학, 데이터 과학, 컴퓨터 과학 등 다양한 분야의 기술을 혼합해야 합니다. 가능한 모든 관점을 조합해야만 인간 언어의 신비를 풀 수 있습니다.
원본 . 허가를 받아 다시 게시했습니다.
약력: SciForce는 과학 기반 정보 기술을 기반으로 하는 소프트웨어 솔루션 개발을 전문으로 하는 우크라이나 기반 IT 회사입니다. 우리는 데이터 마이닝, 디지털 신호 처리, 자연어 처리, 기계 학습, 이미지 처리 및 컴퓨터 비전을 포함한 많은 주요 AI 기술에 대한 광범위한 전문 지식을 보유하고 있습니다.
챗봇 아키텍처란 무엇입니까?
챗봇 아키텍처는 챗봇 개발의 핵심 구성 요소입니다. 이는 비즈니스 운영 및 클라이언트 요구 사항의 유용성 및 컨텍스트를 기반으로 합니다.
개발자는 비즈니스 사용 사례를 기반으로 요소를 구성하고 커뮤니케이션 흐름을 정의하여 더 나은 고객 서비스와 경험을 제공합니다. 동시에 클라이언트는 특정 사용 사례에 대한 이점을 극대화하기 위해 선호도에 따라 챗봇 아키텍처를 개인화할 수도 있습니다.
챗봇의 구성 요소는 무엇입니까?
챗봇이 얼마나 단순하든 복잡하든 관계없이 챗봇 아키텍처는 동일하게 유지됩니다. 사용자가 봇과 상호 작용하는 프런트 엔드가 있습니다. 응답은 다음에 의해 처리됩니다.NLP 엔진또한 적절한 응답을 생성합니다.
1. 사용자 흐름 - 인텐트로 시작
NLU 엔진은 챗봇의 여러 구성 요소로 구성됩니다. 응답을 생성하기 위해 챗봇은 사용자가 말하려는 내용을 이해해야 합니다. 즉, 사용자의 의도를 이해해야 합니다.
메시지 처리는 다양한 문장을 입력으로, 의도를 대상으로 학습하는 의도 분류로 시작됩니다. 예를 들어 사용자가 "지금 베를린 날씨가 어때?"라고 묻는다면 의도는 사용자의 쿼리가 날씨를 아는 것입니다.
그런 다음 요청 내의 특정 의도를 이해해야 합니다. 이를 엔터티라고 합니다. 이전 예에서 날씨, 위치 및 숫자는 엔터티입니다. 확률적 모델 또는 훨씬 더 복잡한 생성 모델을 사용하여 훈련된 사전 훈련된 모델인 엔티티 추출도 있습니다.
2. 응답 가져오기
응답을 예측하기 위해 이전 사용자 대화는 현재 의도, 엔터티 및 사용자가 제공한 정보에 대한 정보가 있는 사전 개체와 함께 데이터베이스에 저장됩니다. 이 정보는 다음 용도로 사용됩니다.
봇 빌더가 설정한 규칙에 따라 정의된 메시지로 사용자에게 응답
데이터베이스에서 데이터 검색
의도와 일치하는 결과를 얻기 위해 API를 호출합니다.
첫 번째 옵션은 더 쉽고 옵션 2와 3에서는 상황이 조금 더 복잡해집니다. 제어 흐름 핸들은 다시 한 번 다음 작업을 예측하기 위해 '대화 관리' 구성 요소 내에 유지됩니다. 대화 관리자는 이 작업과 검색된 결과를 기반으로 현재 상태를 업데이트하여 다음 예측을 만듭니다. 작업이 사용자에 대한 응답에 해당하면 '메시지 생성기' 구성 요소가 대신합니다.
3. 백엔드 통합
챗봇은 다른 시스템이나 애플리케이션에 의해 노출된 정보와 서비스에 의존하기 때문에아피스, 이 모듈은 API를 통해 해당 애플리케이션 또는 시스템과 상호 작용합니다.
따라서,봇날씨, 버스 또는 비행기 일정 또는 공연 티켓 예매 등과 같은 모든 종류의 정보 및 서비스를 사용자에게 제공합니다.
채널
챗봇이 거주하고 소통하는 매체입니다. 예를 들어 Engati와 같은 플랫폼에서 통합 채널은 일반적으로 WhatsApp, Facebook Messenger, Telegram, Slack, Web 등입니다.
외부 통합 서비스
이러한 서비스는 외부 시스템, 서비스 또는 데이터베이스에서 정보를 수집하기 위해 일부 챗봇에 존재합니다.
이는 참조 구조 및 아키텍처에 필요한 것입니다.챗봇 만들기.
챗봇의 사용이 점점 더 단순해지고 있지만 그 뒤에는 복잡한 기술이 많다는 사실을 잊어서는 안 됩니다. 또한 챗봇의 성격과 대화 흐름을 정의하는 것과 관련하여 많은 디자인과 작업이 있으며, 마지막으로 통합을 통해 일반적으로 타사 서비스로 액세스하는 많은 기능과 정보가 있습니다.
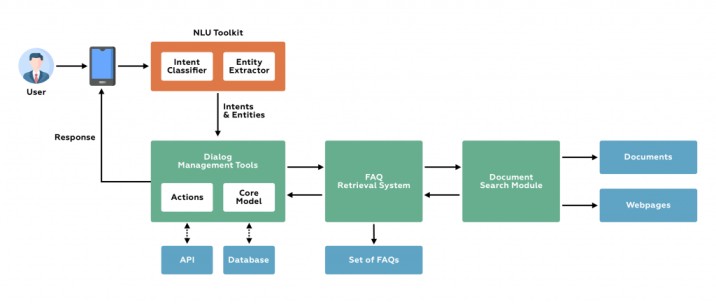
원천:QBurst 블로그
다양한 유형의 챗봇 아키텍처는 무엇입니까?
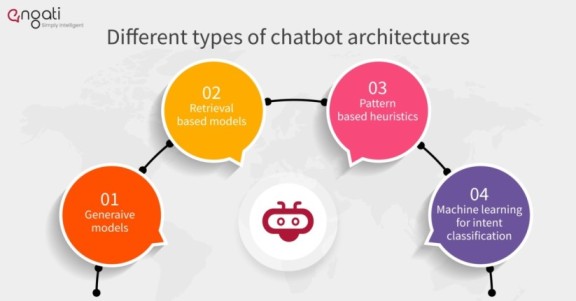
1. 생성 모델
생성 모델챗봇의 미래이며 봇을 더 똑똑하게 만듭니다. 이 접근 방식은 챗봇 개발자가 널리 사용하지 않으며 현재 대부분 실험실에 있습니다.
2. 검색 기반 모델
검색 기반 모델은 구축하기가 훨씬 쉽습니다. 또한 보다 예측 가능한 결과를 제공합니다. 응답의 정확도를 100% 얻지는 못하겠지만 적어도 가능한 모든 응답을 알고 있으며 부적절하거나 문법적으로 잘못된 응답이 없는지 확인할 수 있습니다.
검색 기반 모델은 현재 더 실용적이며 많은 알고리즘과 API를 개발자가 쉽게 사용할 수 있습니다. 챗봇은 미리 정의된 봇 메시지 목록에서 최상의 응답을 선택하기 위해 메시지와 대화 컨텍스트를 사용합니다. 컨텍스트에는 대화 트리의 현재 위치, 대화의 모든 이전 메시지, 이전에 저장된 변수(예: 사용자 이름)가 포함될 수 있습니다.
3. 패턴 기반 휴리스틱
응답을 선택하기 위한 휴리스틱은 if-else 조건 논리에서 기계 학습 분류기에 이르기까지 다양한 방식으로 엔지니어링될 수 있습니다. 가장 간단한 기술은 규칙에 대한 조건으로 패턴이 있는 일련의 규칙을 사용하는 것입니다. 이러한 유형의 모델은 엔터테인먼트 봇에 매우 인기가 있습니다. AIML은 패턴 및 응답 템플릿 작성에 널리 사용되는 언어입니다.
4. 의도 분류를 위한 기계 학습
패턴 기반 휴리스틱스의 고유한 문제는 패턴을 수동으로 프로그래밍해야 하며 특히 챗봇이 수백 개의 의도를 올바르게 구분해야 하는 경우 쉬운 작업이 아니라는 것입니다. 고객 서비스 봇을 구축 중이고 봇이 환불 요청에 응답해야 한다고 상상해 보십시오. 사용자는 "환불을 원합니다", "내 돈을 환불해 주세요", "내 돈을 돌려주세요"와 같이 수백 가지의 다양한 방식으로 표현할 수 있습니다. 동시에 "서비스가 마음에 들지 않으면 환불을 요청할 수 있습니까?", "환불 정책은 무엇입니까?"와 같은 동일한 단어가 다른 컨텍스트에서 사용되는 경우 봇은 다르게 응답해야 합니다. 인간은 자연어 이해를 위한 패턴과 규칙을 작성하는 데 능숙하지 않지만 컴퓨터는 이 작업을 훨씬 더 잘 수행합니다.
기계 학습을 통해 우리는의도 분류 알고리즘. 수백 또는 수천 개의 예제로 구성된 훈련 세트가 필요하며 데이터에서 패턴을 선택합니다.
챗봇 및 라이브 채팅으로 수익 3배
|
데모 예약
|
음성 봇용 챗봇 아키텍처
이것챗봇 아키텍처음성을 처리하기 위한 추가 레이어가 있는 텍스트 챗봇과 유사할 수 있습니다.
우선 음성 처리를 위한 두 개의 블록이 있는데, 이는 챗봇이 음성으로 통신하는 경우에만 의미가 있습니다.
음성 인식: 사용자가 말하는 내용을 인식합니다.
음성 합성: 음성으로 봇 응답 생성
대화 관리자: 대화의 흐름이나 사용자가 묻거나 요구하는 것에 대한 답변을 결정하는 모듈입니다. 기본적으로 이것은 대화, 성격, 스타일 및 챗봇이 기본적으로 제공할 수 있는 것을 정의하는 중심 요소입니다.
자연어 이해: 사용자가 말하고자 하는 것의 의미를 음성이나 문자로 처리합니다.
챗봇의 아키텍처를 개발할 때 고려해야 할 사항은 무엇입니까?
챗봇을 구축하기 전에 청중을 기억하십시오. 유용성과 원활한 고객 경험을 보장하려면 다음 요소를 고려해야 합니다.
사용자 친근성
속도
언어 지원
WhatsApp, Facebook Messenger, Slack 등과 같은 채널과의 호환성
CRM 솔루션과 같은 백엔드 통합,쇼피파이, 확장된 유용성을 위한 Google 캘린더.
분석 및 피드백 제공
대화형 챗봇 아키텍처의 구성 요소는 무엇입니까?
다음은 사용 사례, 도메인 및 챗봇 유형에도 불구하고 대화형 챗봇 아키텍처의 구성 요소입니다.
환경
환경은 주로 자연어 처리(NLP)를 사용하여 사용자의 메시지/입력을 맥락화하는 역할을 합니다. 고객 쿼리에 의미를 부여하고 질문의 의도를 파악하는 것은 챗봇 아키텍처의 중요한 부분 중 하나입니다.
질의 응답 시스템
Q&A 시스템은 고객이 자주 묻는 질문에 답변하거나 처리하는 역할을 합니다. 개발자는 봇을 수동으로 교육하거나 자동화를 사용하여 고객 쿼리에 응답할 수 있습니다. Q&A 시스템은 고객 의도에 따라 주어진 데이터베이스에서 답변 또는 솔루션을 자동으로 선택합니다.
플러그인/구성 요소
플러그인 및 지능형 자동화 구성 요소는 타사 앱 또는 서비스와 연결할 수 있는 챗봇 솔루션을 제공합니다. 이러한 서비스는 일반적으로 보고서, 인사 관리, 결제, 캘린더 등과 같은 내부 용도로 사용됩니다.
노드 서버 / 트래픽 서버
노드 서버는 사용자로부터 들어오는 트래픽 요청을 처리하고 이를 관련 구성 요소로 채널화합니다. 또한 트래픽 서버는 내부 구성 요소의 응답을 다시 프런트 엔드 시스템으로 보내 올바른 정보를 검색하여 고객 쿼리를 해결합니다.
프런트엔드 시스템
페이스북 메신저, 왓츠앱 비즈니스, 슬랙, 구글 행아웃과 같은 일련의 프론트엔드 시스템을 보유하는 것은 웹사이트나 모바일 앱 기반 챗봇과는 별도로 대다수의 고객 기반과 상호 작용할 수 있는 가능성을 확보하는 데 매우 중요합니다.
챗봇 아키텍처에서 질문 및 답변 교육은 어떻게 이루어지나요?
다음은 챗봇 아키텍처에서 봇을 훈련시키는 두 가지 방법입니다.
수동 교육
전문가가 FAQ(자주 묻는 질문)를 만든 다음 관련 답변과 매핑하는 프로세스를 수동 교육이라고 합니다. 이를 통해 봇은 중요한 질문을 식별하고 효과적으로 답변할 수 있습니다.
자동화된 훈련
자동화된 교육에는 정책 문서 및 기타 Q&A 스타일 문서와 같은 회사 문서를 봇에 제출하고 코치에게 직접 요청하는 작업이 포함됩니다. 엔진은 이러한 문서의 질문 및 답변 목록을 제공합니다. 그러면 봇이 이러한 질문에 자신 있게 대답할 수 있습니다.
'say와 AI 챗봇친구 만들기 보고서' 카테고리의 다른 글
| 대화 디자인은 UX의 미래입니다 (0) | 2023.08.08 |
|---|---|
| 챗GPT와 나만의 글쓰기 스타일, 어떻게 가능할까? (0) | 2023.08.06 |
| AI 챗봇 이란? - 정의, 원리, ChatGPT, 구축 과정 [AI 챗봇의 시작부터 성공 노하우까지 완벽 정리] (0) | 2023.08.03 |
| 챗GPT 거대한 전환 (4) | 2023.08.02 |
| 채팅 GPT4 [가장 진보된 언어 모델] (0) | 2023.08.02 |



