
구라제거기[키보드 보안 프로그램 삭제] 7.21 업데이트
PC 뱅킹의 주적은 PC 뱅킹 프로그램이다.
PC 뱅킹을 하고 나면 컴퓨터가 미친 듯이 느려지기 때문이다.
키보드 보안 프로그램을 필두로 컴퓨터를 느려지게 만드는 악의 무리들이 너무나 많다.
전통의 명가(?) nProte**부터 컴퓨터 발목 잡기의 거목 안* 온라인 시큐**, 그 외에도 수많은 잡 구라들…
KISA에서 I사 보안모듈 프로그램에 문제가 있다고 발표할 정도로 완성도가 엉망인 경우도 있다.
보안 취약점을 갖고있는 보안 프로그램이라니… 무슨 열림교회 닫힘도 아니고…
더군다나 이런 프로그램들은 몰래 설치가 되는 것도 아니고 아예 (강제로) 동의를 받아 설치된다.
마치 건물 철거 강제 집행하면서 동의서 서명당하는 기분이다
게다가 보안 전문가인 블라디미르 팔란트 씨의 글에 따르면 이 과정에서 설치된 루트 인증서를 제대로 삭제하지도 않는다.
그래서 간단히 만들었다.
설치 프로그램 목록에서 이러한 백해무익한 쓰레기들을 찾아서 한방에 제거해 주는 프로그램.
이번 7.x대에서는 업데이트 여부를 확인하는 기능을 추가했고, 7.10에서는 루트 인증서를 확인하는 기능을 추가했으며, 7.16에서는 목록들을 정렬하는 기능을 추가했다.
그리고, 7.17에서는 후원 계좌를 띄우지 않고 토스 아이디를 통해 후원받도록 수정했다.
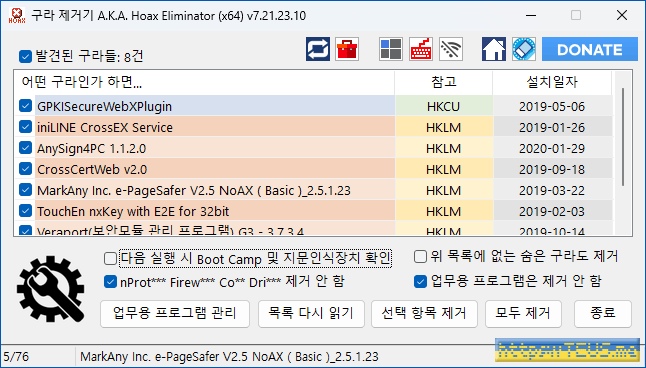
이 프로그램을 실행하면 위와 같은 화면이 나온다.
PC에 설치된 프로그램들 중에 제거해야 될 프로그램들의 목록을 띄워준 것이다.
여기서 일부를 선택해서 제거를 클릭해도 되고, 그냥 모두 제거를 클릭해도 된다.
클릭하면 지정된 프로그램들을 하나씩 제거할 수 있는 배치 파일을 만들고 실행해서 몽땅 제거해 준다.
화면에 다이얼로그가 뜨면 하나씩 확인 버튼만 클릭하면 된다.
이 프로그램은 아래 링크에서 다운로드할 수 있다.
x86과 x64 버전이 함께 들어있는데, 64비트 환경이라면 x64 버전을 추천한다.
password: teus.me
덧 1. 알리는 말씀
프로그램의 특성상 모든 경우를 다 시험해 볼 수 없습니다.
혹시 삭제 후 문제가 발생하는 나쁜 프로그램에 대해 댓글로 알려주시면 추가로 확인하겠습니다.
또, 설치된 프로그램 이름을 오진하는 경우가 발생할 수 있으니, 댓글로 알려주시면 반영하겠습니다.
모두 제거 버튼을 클릭하기 전에 반드시 목록을 확인하시기를 강력히 권고드립니다.
이 프로그램은 여러분의 관심으로 발전해 갑니다.
관심 가져주시는 모든 분들께 감사드립니다.
덧 2. 이 프로그램이 삭제하는 목록은 아래와 같음
덧 3. PayPal 기부 및 TOSS 기부를 기다립니다. 페이지 상단에도 링크가 있습니다.
이 프로그램은 여러분의 기부를 먹고 자랍니다. ☜ 중요
덧 4. 본 프로그램 이전 버전 관련 포스팅의 댓글을 달지 못하게 수정했습니다.
댓글은 여기에 달아주시기 바랍니다.
덧 5. 간혹 압축을 풀면 실행파일이 없다는 답글이 달리는데,
압축 프로그램 and/or 백신 프로그램의 문제입니다.
덧 6. 프로그램은 암호를 걸어 압축했습니다.
알집으로 압축 해제 시 종종 실패하는 것 같으니 반디집을 추천합니다.
▲ 히스토리
2023.10.15: v7.21
- Google/RE2 라이브러리를 2023.9.1 버전으로 업데이트
- Google/Abseil 라이브러리를 20230802.1 버전으로 업데이트
- 코드 정리
- 제거 대상 프로그램 추가/보완
ExA****er_N*W**
if*N*Ser****
memcpy() 계열 최적화?
memcpy() 계열 최적화?
깃헙 zlib-ng 라이브러리에 아래와 같은 내용이 반영된 수정이 올라왔다. unaligned access를 허용하지 않는 환경에서는 memcpy(), memcmp()를 사용하고, 허용된다면 직접 비교한다는 것. /* Force compiler to emit
teus.me
깃헙 zlib-ng 라이브러리에 아래와 같은 내용이 반영된 수정이 올라왔다.
unaligned access를 허용하지 않는 환경에서는 memcpy(), memcmp()를 사용하고, 허용된다면 직접 비교한다는 것.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
/* Force compiler to emit unaligned memory accesses if unaligned access is supported
on the architecture, otherwise don't assume unaligned access is supported. Older
compilers don't optimize memcpy and memcmp calls to unaligned access instructions
when it is supported on the architecture resulting in significant performance impact.
Newer compilers might optimize memcpy but not all optimize memcmp for all integer types. */
#ifdef UNALIGNED_OK
# define zmemcpy_2(dest, src) (*((uint16_t *)(dest)) = *((uint16_t *)(src)))
# define zmemcmp_2(str1, str2) (*((uint16_t *)(str1)) != *((uint16_t *)(str2)))
# define zmemcpy_4(dest, src) (*((uint32_t *)(dest)) = *((uint32_t *)(src)))
# define zmemcmp_4(str1, str2) (*((uint32_t *)(str1)) != *((uint32_t *)(str2)))
# if UINTPTR_MAX == UINT64_MAX
# define zmemcpy_8(dest, src) (*((uint64_t *)(dest)) = *((uint64_t *)(src)))
# define zmemcmp_8(str1, str2) (*((uint64_t *)(str1)) != *((uint64_t *)(str2)))
# else
# define zmemcpy_8(dest, src) (((uint32_t *)(dest))[0] = ((uint32_t *)(src))[0], \
((uint32_t *)(dest))[1] = ((uint32_t *)(src))[1])
# define zmemcmp_8(str1, str2) (((uint32_t *)(str1))[0] != ((uint32_t *)(str2))[0] || \
((uint32_t *)(str1))[1] != ((uint32_t *)(str2))[1])
# endif
#else
# define zmemcpy_2(dest, src) memcpy(dest, src, 2)
# define zmemcmp_2(str1, str2) memcmp(str1, str2, 2)
# define zmemcpy_4(dest, src) memcpy(dest, src, 4)
# define zmemcmp_4(str1, str2) memcmp(str1, str2, 4)
# define zmemcpy_8(dest, src) memcpy(dest, src, 8)
# define zmemcmp_8(str1, str2) memcmp(str1, str2, 8)
#endif
#endif
|
그런데, unaligned access를 지원하는 x86/x64 계열 1에서 최신 컴파일러를 사용하면 저런 처리는 알아서 다 해준다.
아래의 코드를 보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
const static size_t SZ = 1000000000;
BYTE *p1 = new BYTE[SZ];
memset(p1, 0x7f, SZ);
BYTE* p2 = new BYTE[SZ];
for (size_t i = 0; i < SZ; i += 4) {
memmove(p2 + i, p1 + i, 4);
}
for (size_t i = 0; i < SZ; i += 4) {
*(uint32_t*)(p2 + i) = *(uint32_t*)(p1 + i);
}
|
memcpy() 또는 memmove() 한 방으로 끝날 것을 굳이 복잡하게 작성한 코드다.
그리고, 루프를 돌면서 memcpy()도 아니고 미묘하게라도 더 느린 memmove()를 사용해서 구현했다.
비주얼 스튜디오 2022로 디버그 모드에서 이를 컴파일한 결과는 아래와 같다.
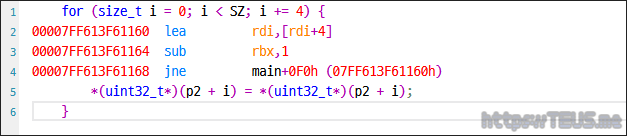
우선 memmove() 파트를 보면 코드 그대로 부지런하게 memmove()를 호출하는 것을 볼 수 있다.

다음은 나름 최적화한 uint32_t*로 캐스팅해서 복사한 파트를 보자.
for() 루프는 동일하지만 맨 마지막에 call memmove() 대신 move dword ptr로 복사하는 것을 볼 수 있다.
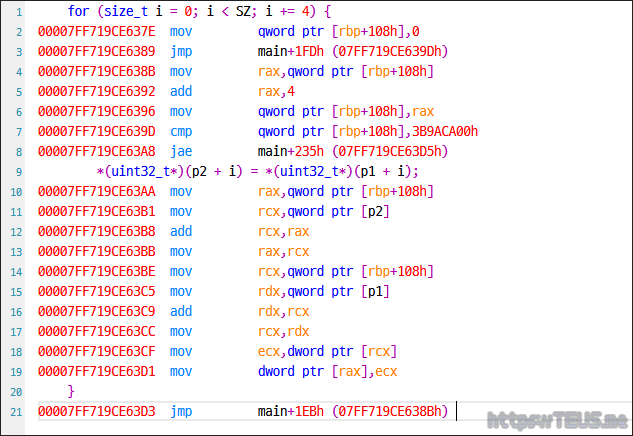
당연하게도 memmove()를 사용하지 않는 쪽이 훨씬 더 빠르다.
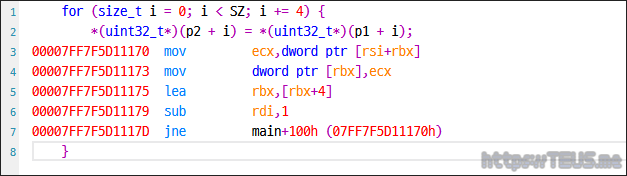
그렇다면 이를 릴리즈 모드로 컴파일한 결과는 어떨까?
아래 컴파일 된 결과를 보자.
call memmove()는 사용하지 않고, for() 루프와 합쳐서 코드를 생성하는 것을 볼 수 있다.

따라서, 나름 최적화한(?) 아래쪽과 100% 동일한 코드를 생성한다.
하는 김에 아래와 같이 p1를 p2로 바꿔서 무의미한 코드로 바꿔보면 어떨까?
|
1
2
3
4
5
6
7
|
for (size_t i = 0; i < SZ; i += 4) {
memmove(p2 + i, p2 + i, 4);
}
for (size_t i = 0; i < SZ; i += 4) {
*(uint32_t*)(p2 + i) = *(uint32_t*)(p2 + i);
}
|
memmove() 행은 코드를 아예 생성하지도 않는다.
그냥 무의미하게 루프만 돌려줌.
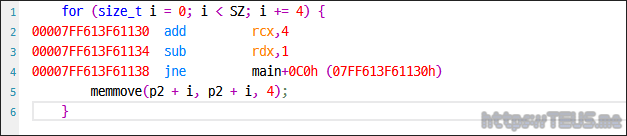
나름 최적화한 쪽도 마찬가지.
역시 무의미하게 루프만 돌려준다.
memset()에 대해서도 비슷한 포스팅을 했었는데, 최신 환경에서 최신 컴파일러들은 이런 최적화는 알아서 해준다.
한 줄 요약: 컴파일러가 다 알아서 해주니 memmove() 편하게 쓰자
덧 1. 원론적으로 memcpy()는 메모리 영역이 충돌하는지 확인하지 않고, memmove()는 확인한다.
따라서 미세하게라도 memcpy()가 더 빠르지만, memmove()가 훨씬 안전함.
덧 2. 이 글은 zlib-ng의 구현이 틀렸다는 얘기가 아님. 모든 환경을 지원하려면 저렇게 작성해야 함.
덧 3. 루프 내에 코드가 없어도 for() 루프 문은 컴파일되는데, 다양한 이유에서 미묘한 delay가 필요하기 때문.
memcpy() 최적화 2차 도전
2023.10.25 - memcpy() 계열 최적화?
1년 반쯤 전에 쓴 글에서 memcpy() 계열을 굳이 더 최적화할 필요가 없다는 글 1을 썼었다.
그런데, 스택 오버플로우에서 재미있는 글타래(faster alternative to memcpy?)를 발견했다.
댓글들의 요지는 AVX2 레지스터를 활용하면 더 빠른 복사를 할 수 있고, 이를 병렬수행하면 더 효과가 높아진다는 것.
전자의 경우 기존의 memcpy()에서도 활용할 것 같지만, 후자는 효과가 있을지 여부가 좀 궁금해졌다.
메모리 대역폭이 명령어 실행 사이클보다 충분히 크다면 효과가 없지는 않을 것 같았다.
위 글의 코드들을 대폭 참조한 코드를 만들어 돌려봤다.
코드의 구성들은 대략 아래와 같았고, 동작환경은 AMD Ryzen 9 5900X, 64GB 메모리.
- 1. memcpy() 순정품
- 2. ippsCopy_64f(): 모든 값을 double로 생성하여 IPP 함수 중 이 함수 활용
- 3. __m256i 레지스터를 통한 32바이트 단위 복사
- 4. 병렬수행: C++의 thread()를 활용하여 4개의 스레드 동시 수행
- 5. 병렬수행: C++ 17의 병렬수행을 활용하여 4개의 스레드 동시 수행
- 6. 1번, 3번, 5번을 조건에 따라 선택적으로 수행
테스트는 일정한 개수의 double 값들을 무작위로 생성하여 복사하는 것으로 진행했다.
균일한 난수를 생성한 뒤 합을 구해서 난수가 정상적으로 생성되는 것과 복사가 정상적으로 진행됨을 확인.
대략의 결과는 아래와 같았다.
1. 4번과 5번은 개념은 동일하고, 스택 오버플로우의 답글에서는 4번 만을 구현했는데, 돌려보니 5번이 더 빠름.
2. 병렬수행 시 스레드의 개수는 4개 이상에서는 유의미한 차이가 없어 4개로 제한. 메모리 대역폭이 무한하지 않기 때문인 듯.
3. IPP를 활용한 복사는 아이고 의미 없다...
좀 더 상세하게 보면 아래와 같았다.
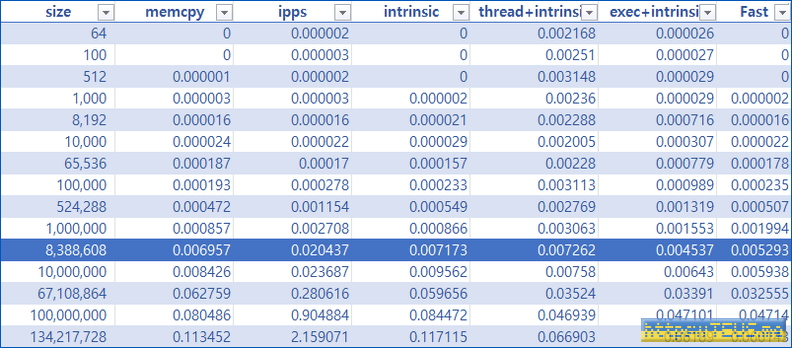
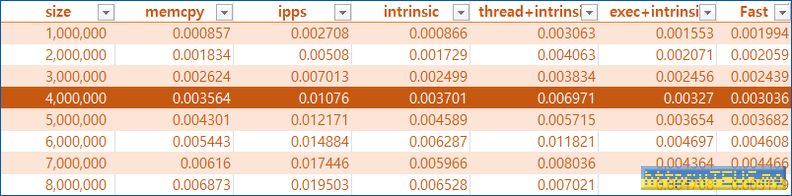
우선, 1차적으로 생성한 난수들에 대한 연산 시간은 아래 표와 같았다.
표를 다 읽을 필요는 없고, 100만 개 정도(즉, 800만 바이트 정도)부터는 병렬수행을 통한 복사가 더 빨라진다는 점만 보면 될 듯.
이를 한눈에 볼 수 있도록 그래프로 그리면 아래와 같다.
뭔가 하나가 튀어서 나머지 그래프를 보기 힘든데, 튀는 것이 ippsCopy_64f()이다.
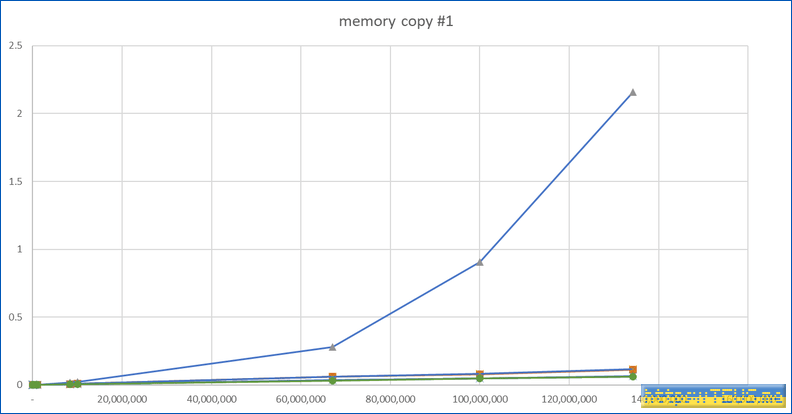
불필요한 IPP 함수를 제거하면 아래와 같다.
그래프의 y축은 시간이므로 클수록 느리다는 뜻.
위의 둘이 1번과 3번이다. 다시 말해 적어도 VS2022에서는 memcpy()는 AVX2 레지스터를 활용한 구현이 되어있다는 뜻.
아래쪽이 병렬수행한 결과인데, 데이터의 양이 어떤 수준이 되면 유의미하게 빠른 속도를 보여준다.
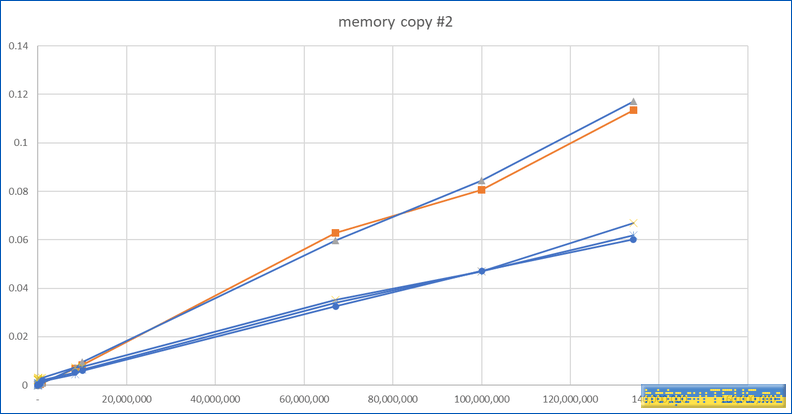
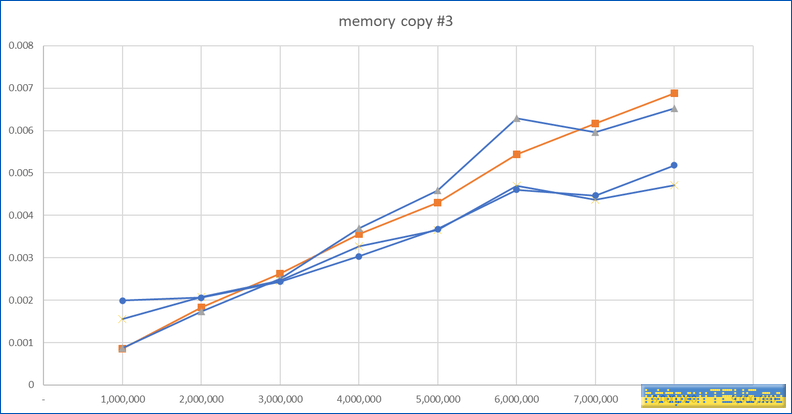
다음은 데이터의 양이 얼마 정도가 되면 이러한 병렬수행이 힘을 발휘하는가를 확인할 차례.
확인 결과 데이터가 대략 400만 바이트 이상이 되면 병렬수행 쪽이 더 빨라진다.
더불어, thread를 직접 생성하는 것보다 execution을 활용하는 쪽이 유의미하게 빠른 속도 2를 보여준다.
그래프로 보면 아래와 같다.
병렬수행 방안에 따른 성능 차이는 존재하지만 memcpy()와 비교해 보면 큰 의미가 없다는 생각도 든다.
300만.. 400만 바이트 구간에서 더 위쪽으로 가는 둘이 병렬수행을 하지 않는 memcpy()와 AVX2의 결과.
이 내용을 모두 갈아 넣은 코드는 아래와 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
void MemcpyFast(void* pvDest, void* pvSrc, size_t nBytes, size_t nThreads = 4) {
// check alignment
if (((intptr_t(pvDest) & 31) | (intptr_t(pvSrc) & 31)) ||
(nBytes < 4000000)) {
memcpy(pvDest, pvSrc, nBytes);
return;
}
const __m256i* pSrc = reinterpret_cast<const __m256i*>(pvSrc);
__m256i* pDest = reinterpret_cast<__m256i*>(pvDest);
intptr_t nVects = nBytes / sizeof(*pSrc);
const intptr_t nVectsPerThread = (nVects + nThreads - 1) / nThreads;
std::vector<int> v;
v.resize(nThreads);
iota(v.begin(), v.end(), 0);
std::for_each(std::execution::par, v.begin(), v.end(), [&](int p) {
const intptr_t curStart = p * nVectsPerThread;
const intptr_t nextStart = std::min(curStart + nVectsPerThread, nVects);
intptr_t nVects = nextStart - curStart;
const __m256i* pSrc0 = pSrc + curStart;
__m256i* pDest0 = pDest + curStart;
for (; nVects > 0; nVects--, pSrc0++, pDest0++) {
const __m256i loaded = _mm256_stream_load_si256(pSrc0);
_mm256_stream_si256(pDest0, loaded);
}
});
_mm_sfence();
const size_t remain = nBytes & 31;
if (remain) {
intptr_t nVects = nBytes / sizeof(*pSrc);
const char* pSrcChar = reinterpret_cast<const char*>(pSrc + nVects);
char* pDestChar = reinterpret_cast<char*>(pDest + nVects);
memcpy(pDestChar, pSrcChar, remain);
}
}
|
한 줄 요약: 400 MB 이상에선 병렬처리가 성능을 향상하고 그 외엔 무조건 memcpy()
'Interface' 카테고리의 다른 글
| 유부남이 선호하는 결혼 기념일 선물 1위 (0) | 2023.10.31 |
|---|---|
| 제대로 파는 자바스크립트(JavaScript) - 업데이트판 (가독성UP/추가내용) (0) | 2023.10.26 |
| 엔비디아 PC용 CPU 침공 인텔 정조준 AMD도 ARM 기반 CPU 준비 (0) | 2023.10.25 |
| 윈도우 설치 디스크로 자동 설치하기 (0) | 2023.10.24 |
| 한국 AI, 세계 몇 등? (1) | 2023.10.10 |



